




1兆のテキストトークン・34億個の画像・PDF・ArXivの論文などを含むオープンソースのデータセット「MINT-1T」をSalesforceが公開

クラウドコンピューティングサービスを提供するSalesforceのAI研究部門・Salesforce AI Researchが、1兆ものテキストトークンを含むオープンソースのマルチモーダルデータセット「MINT-1T」を公開しました。
GitHub - mlfoundations/MINT-1T: MINT-1T: A one trillion token multimodal interleaved dataset.
https://github.com/mlfoundations/MINT-1T
MINT-1T: Scaling Open-Source Multimodal Data by 10x: A Multimodal Dataset with One Trillion Tokens
https://blog.salesforceairesearch.com/mint-1t/
Breaking news! ➡️➡️➡️ We just released the MINT-1T 🍃dataset! One trillion tokens. Multimodal. Interleaved. Open-source. Perfect for training multimodal models and advancing their pre-training. Try it today!
— Salesforce AI Research (@SFResearch) July 24, 2024
Blog: https://t.co/e36YvEBrcP
Dataset: https://t.co/FHKhkAURdN pic.twitter.com/guqup91SBW
AIの開発には膨大な量のテキストや画像を含むデータセットが必要であり、高品質なデータセットがオープンソースで公開されることは、AI分野の発展にとって大きなメリットとなります。
新たにSalesforce AI Researchは、「MINT-1T」というマルチモーダルなデータセットをオープンソースで公開しました。MINT-1Tには1兆ものテキストトークンや34億枚の画像が含まれているほか、PDFやプレプリントサーバーであるArXivの論文など、これまでのデータセットには活用されていなかったデータも含まれているとのこと。
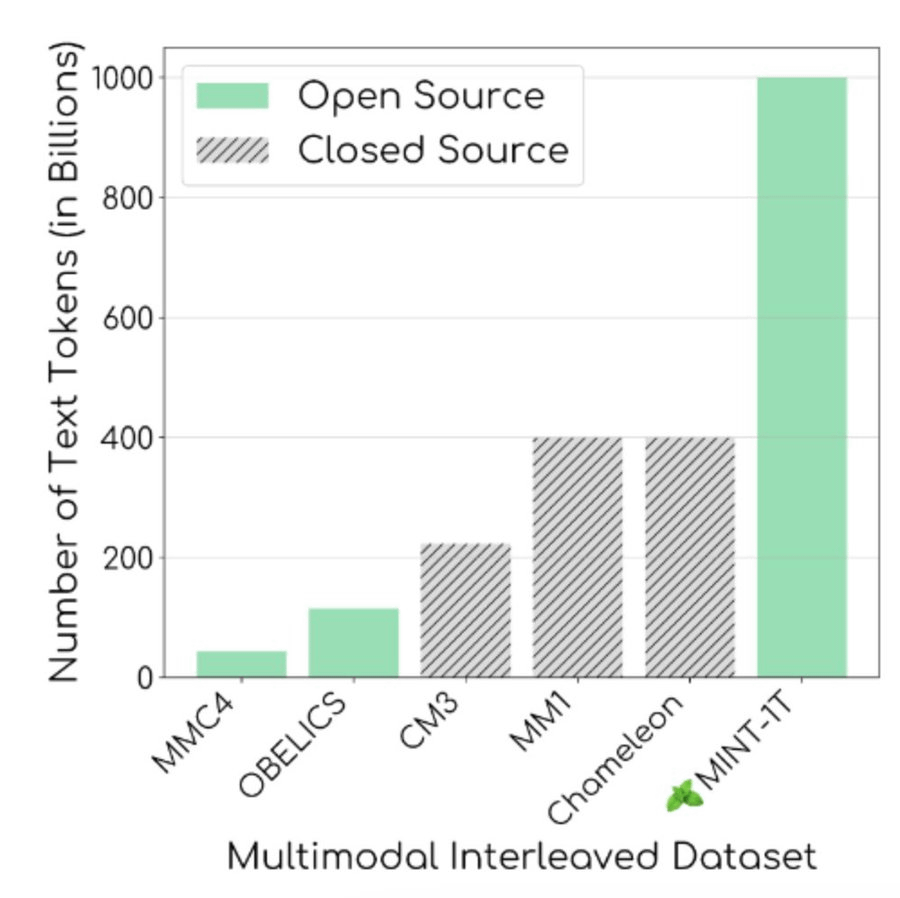
以下の図が示しているように、OBELICSやMMC4といったこれまでのオープンソースデータセットのトークン数は最大1150億であり、MINT-1Tは大幅にトークン数が増加しています。
以下はMINT-1Tに含まれているドキュメントのサンプルです。画像と共にテキストが併記されており、さまざまなグラフやヒートマップなども含まれていることがわかります。Salesforce AI Researchは、「MINT-1Tのキュレーションの主な原則は、規模と多様性です」「MINT-1Tの多様性を向上させるために、HTMLドキュメントを超えてWebのPDFやArXivの論文も含めるようにしています。これらの追加ソースにより、特に科学文書のドメインカバレッジが向上することがわかりました」と述べました。

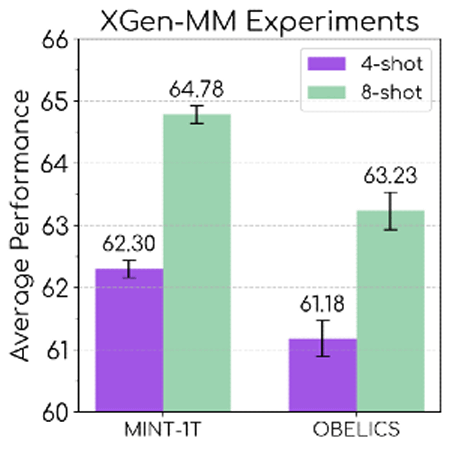
以下のグラフは、Salesforce AI Researchが開発したAIモデルのXGen-MMを使い、MINT-1Tでトレーニングした場合(左)とOBELICSでトレーニングした場合(右)のパフォーマンスを比較した結果です。MINT-1Tでトレーニングした方が、全体的なパフォーマンスが向上していることがわかります。
・関連記事
AIを開発するために必要なデータが急速に枯渇、たった1年で高品質データの4分の1が使用不可に - GIGAZINE
きちんとチェックすると「781年」かかるAI用データセット「LAION-5B」の課題がよくわかる「Models All The Way Down」 - GIGAZINE
AIモデルのトレーニングで使えるアニメーション特化のデータセット「Sakuga-42M」が登場 - GIGAZINE
画像生成AIのStable Diffusionなどに使われるデータセット「LAION-5B」に同意のない子どもの写真が含まれており身元まで特定可能 - GIGAZINE
Metaの基礎AI研究チームが複数の研究を発表、AIモデルやデータセットなど複数の成果を共有 - GIGAZINE
AI学習にYouTubeの字幕を使用したとの報道にAppleが「Apple Intelligence」を含む製品版AIには使っていないと反論 - GIGAZINE
・関連コンテンツ






in AI, ソフトウェア, ネットサービス, Posted by log1h_ik
You can read the machine translated English article Salesforce releases open source dataset ….