




Metaの基礎AI研究チームが複数の研究を発表、AIモデルやデータセットなど複数の成果を共有

Metaの基礎AI研究チーム(Meta FAIR)が、オープンサイエンスの理念のもと複数の新しい研究成果を一般公開しました。Meta FAIRの発表したものの中には、新しいマルチモーダルAIモデルや、開発に携わったデータセット、音声生成AI、オーディオウォーターマーク技術などが含まれています。
Sharing new research, models, and datasets from Meta FAIR
https://ai.meta.com/blog/meta-fair-research-new-releases/

Meta FAIRは、オープンな研究を通じてAIの最先端技術を進歩させ、すべての人に利益をもたらすことを使命として、AI関連のあらゆる領域の基礎的な理解を深めることを目指しています。Meta FAIRは10年以上にわたってオープンリサーチを通じてAIの最先端技術の進歩に注力してきました。この分野のイノベーションが急速に進む中で、Metaは「グローバルAIコミュニティとのコラボレーションがこれまで以上に重要になってくると考えています」と言及しています。Meta FAIRはオープンサイエンスのアプローチを維持しながらコミュニティと研究を共有することで、「誰にとっても機能し世界をより近づけるようなAIシステムを構築するという目標に忠実であり続けることができる」と述べました。
こういった理念のもと、Meta FAIRは最新の6つの研究成果をまとめています。
◆1:Meta Chameleon
Meta Chameleonは、テキストと画像を入力として組み合わせることで、エンコードとデコードの両方に単一の統合アーキテクチャを使用して、テキストおよび画像の任意の組み合わせを出力することができるというマルチモーダル大規模言語モデル(LLM)です。既存のAIモデルのほとんどが拡散モデルが採用されていますが、Meta Chameleonはテキストと画像にトークン化を採用しているため、より統合されたアプローチが可能となり、AIモデルの設計・保守・拡張も容易となります。画像にクリエイティブなキャプションを生成したり、テキストプロンプトと画像を組み合わせることで全く新しい画像を生成したりすることも可能です。
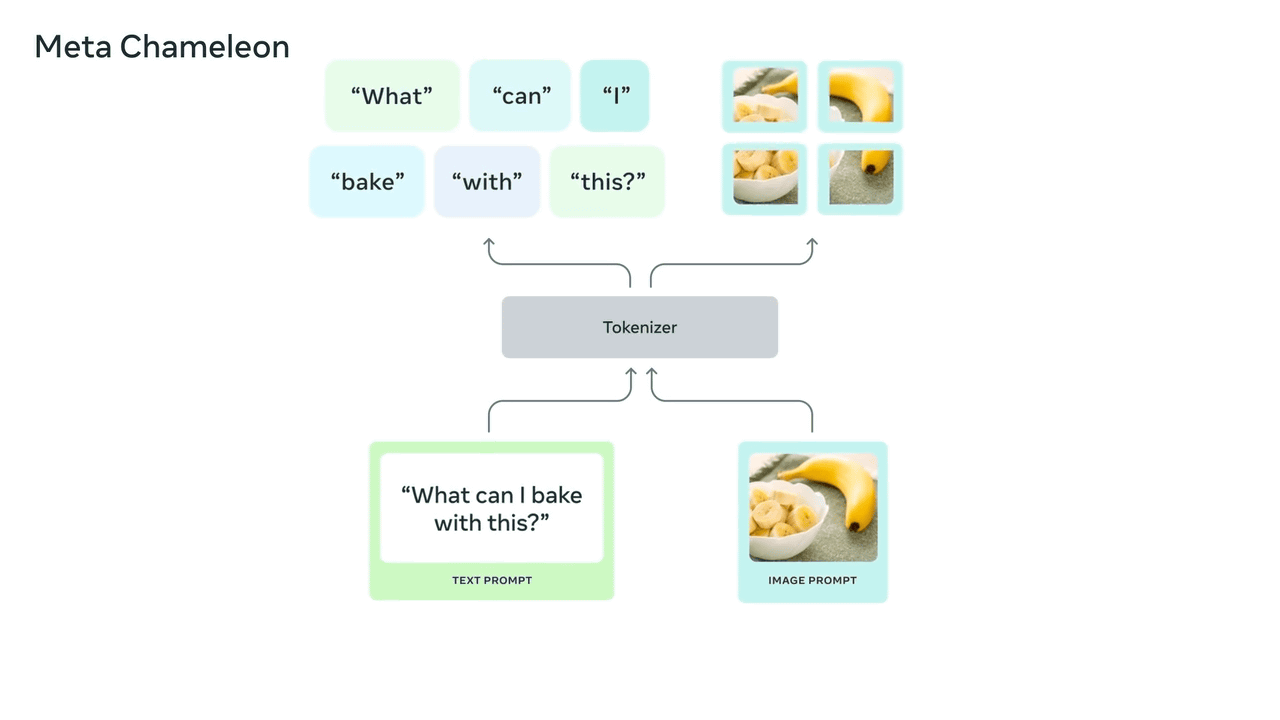
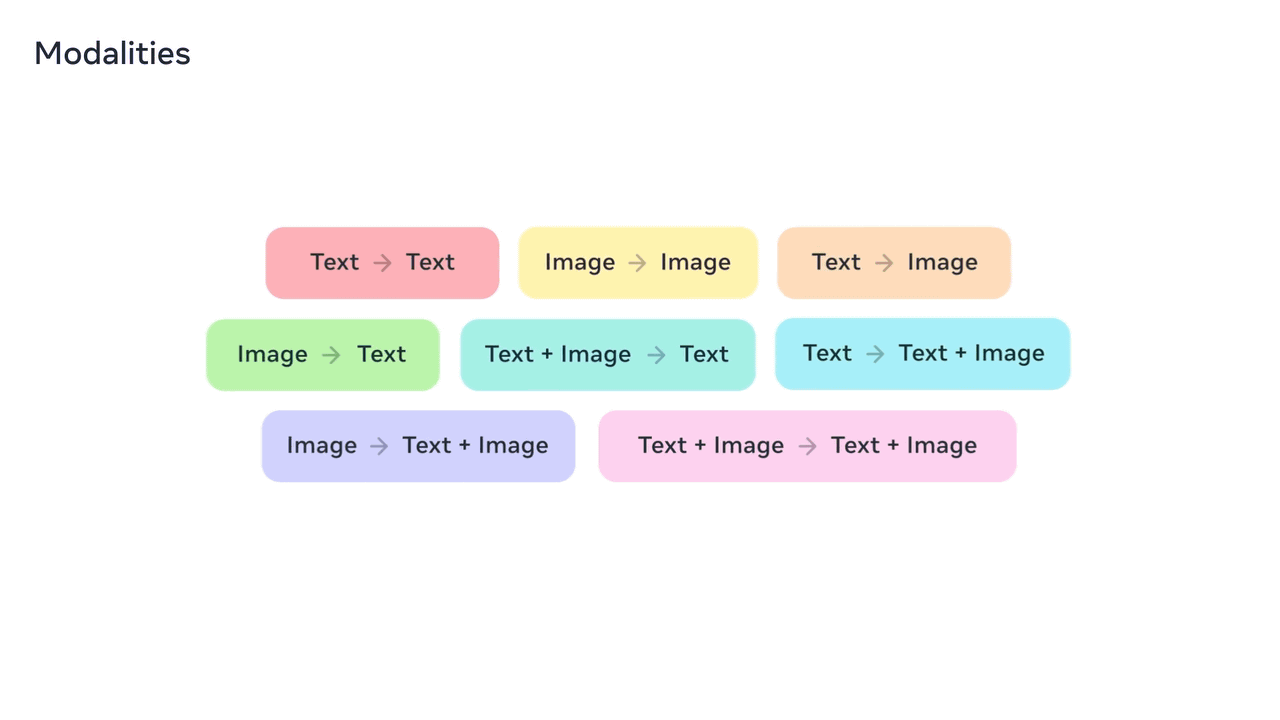
Meta Chameleonでは、テキストから新しいテキストを生成したり、画像から別の新しい画像を生成したり、テキストから画像を生成したり、画像からテキストを生成したり、テキストと画像の組み合わせからテキストを生成したり、テキストからテキストと画像の組み合わせを生成したり、画像からテキストと画像の組み合わせを生成したり、画像とテキストの組み合わせから別の画像とテキストの組み合わせを生成したりすることもできます。
Meta Chameleon自体は2024年5月に論文で発表されていたのですが、現地時間の2024年6月18日にはMeta Chameleonの7Bモデルと34Bモデルの主要コンポーネントが、研究者向けに公開されました。研究者向けに公開された2つのモデルは安全性が考慮されており、研究目的で使用できるようにマルチモーダル入力とテキストのみの出力をサポートしています。
Metaはこれらのモデルを責任を持って開発するための措置を講じていますが、リスクが残ることも認識しているため、記事作成時点ではMeta Chameleonの画像生成モデルを公開していません。
◆2:マルチトークン予測
LLMのトレーニング目標のほとんどは、「次の単語を予測する」という単純な作業をより正確にすることです。このアプローチは単純でスケーラブルな方法ですが、非効率的でもあります。例えば、LLMに子どもと同程度の言語の流ちょうさを取得させるには、子どもの教育に必要とされるテキスト量よりもはるかに多いテキスト量が必要です。
そこで、Metaはマルチトークン予測と呼ばれる手法を用いて、より優れたLLMを構築するためのアプローチを提案しました。マルチトークン予測を用いて言語モデルをトレーニングすることで、一度に複数の単語予測が可能となります。これにより、AIモデルの機能とトレーニング効率が向上し、反応速度も向上することにつながります。Metaはオープンサイエンスの精神のもと、コード補完用の事前トレーニング済みモデルを非商用・研究用のライセンスでリリースしました。
◆3:Meta JASCO
生成AIの登場により、テキストから音楽ファイルを生成することができるツールが登場しています。MusicGenなどの既存のAIモデルは、音楽生成において主にテキスト入力に依存していますが、Meta JASCO(Joint Audio and Symbolic Conditioning for Temporally Controlled Text-to-Music Generation)は特定のコードやビートなどのさまざまな条件入力を受け入れ、生成された音楽出力の制御を向上させることが可能です。具体的には、情報ボトルネックレイヤーを時間的ブラーと組み合わせて適用し、特定のコントロールに関する関連情報を抽出。これにより、同じテキストから音楽を生成するAIモデルと比べて、記号ベースとオーディオベースの両方の条件を組み込むことが可能となります。
MetaはJASCOの研究論文を公開しており、2024年後半にはMetaのサウンド生成ツールである「AudioCraft」の一部として推論コードがMITライセンスのもと公開される予定です。
◆4:AudioSeal
生成AIツールは人々が自分の作品を友人・家族・ソーシャルメディアのフォロワーと共有することを促しています。そのため、Metaは「すべてのAIイノベーションと同様に、これらのツールの責任ある使用を確実にすることが我々の役割でもあります」と述べました。そのためのツールとして、Metaは「AudioSeal」を発表しています。AudioSealは音声生成AIツール向けに設計されたウォーターマーク技術で、長いオーディオスニペット内でAI生成セグメントを正確に特定できるようになる技術だそうです。
AudioSealはステガノグラフィーではなくAI生成コンテンツの検出に重点を置くことで、従来のオーディオウォーターマーク技術を刷新しています。複雑なデコードアルゴリズムに依存する従来の方法とは異なり、ローカライズされた検出アプローチにより、より高速で効率的な検出が可能になっているそうです。これにより、AudioSealは従来の方法と比べて検出速度が最大485倍も向上し、大規模リアルタイムアプリケーションでの使用に適しているそうです。また、AudioSealは堅牢性と知覚されにくさの点で、オーディオウォーターマーク技術としては最先端のパフォーマンスを実現します。

AudioSealは商用ライセンスでリリースされており、テキストと音声の基礎翻訳モデルであるSeamlessM4T v2とAudioboxによって生成された音声サンプルにもAudioSealが採用されているそうです。
◆5:PRISMデータセットの公開を支援するパートナーシップ
さまざまな人々からフィードバックを得ることは、LLMを改善する上で重要ですが、研究コミュニティではフィードバックプロセスに関する方法・領域・目的について未解決の問題が残っています。Metaは外部パートナーと協力してこれらの問題に取り組んでおり、75カ国から集まった1500人の多様な参加者の社会人口統計と好みをマッピングしたPRISMデータセットのリリースをサポートしました。Metaは対人関係や異文化間で意見の相違が生じやすいトピックについて、主観的かつ多文化的な視点を中心とした会話に焦点を当てることで、外部パートナーによるPRISMデータセットの編集に助言しています。
Metaは対話の多様性、好みの多様性、福祉の結果に関する3つのケーススタディを通じてPRISMデータセットの有用性を示しており、どの人間が整合基準を設定するかが重要であると指摘。MetaはPRISMデータセットがAIコミュニティのリソースとして役立つことを期待しており、AI開発へのより幅広い参加を促し、テクノロジー設計へのより包括的なアプローチを促進することを望んでいると説明しました。
◆6:テキストから画像を生成するシステムにおける地理的差異の測定と改善
テキストから画像を生成することができるAIモデルにとって、世界の地理的および文化的多様性を反映することは非常に重要です。これらのモデルを改善するには、研究者が既存のモデルのどこに欠陥があるかをよりよく理解できるようにするための新しいツールが必要となります。
Metaはテキストから画像を生成するAIモデルにおける潜在的な地理的差異を評価するために、「DIG In」と呼ばれる自動指標を開発し、異なる地域の人々の地理的表現に対する認識がどのように異なるかを理解するために大規模な注釈調査も実施しています。テキストから画像を生成するAIモデルの自動評価と人間による評価を改善すべく、魅力・類似性・一貫性・共通の推奨事項を網羅した6万5000件を超える注釈と20件を超えるアンケート調査の回答が収集されました。
この研究により、人々は生成画像の地理的な表現を認識する時に、画像全体を総合的に見るのではなく画像内の特定コンポーネントを利用することが判明しています。Meta FAIRでの共同アプローチの一環として、Metaはマサチューセッツ大学アマースト校の大学院生チームを指導し、これまで導入してきた自動インジケーターを前景の概念と背景の表現に分解するフォローアップ評価も実施しています。
DIG Inの情報に基づき、テキストから画像を生成するAIモデルの出力の多様性を向上させる方法も模索しました。ここから生まれたのがコンテキスト化されたVendi Scoreと呼ばれるガイダンスです。これはMetaが過去に発表したフィードバックガイダンス作業を拡張し、画像品質とプロンプト生成の一貫性を維持あるいは改善しながら、生成されたサンプルの表現の多様性を増加させるように、最先端の画像生成AIモデルを導く推論時間介入を使用したものとなっています。
・関連記事
Metaはどのようにして大規模なAIを稼働させるインフラをメンテナンスしているのか? - GIGAZINE
MetaがFacebookとInstagramの投稿でAIを強化する計画をEUで一時停止へ - GIGAZINE
MetaのAI施策に反発する形でアンチAIプラットフォーム「Cara」のユーザー数が1週間で17倍超に増加 - GIGAZINE
Metaのスマートグラス「Ray-Ban Meta」でビデオ通話が可能に&AIアシスタント「Meta AI」のベータ版も北米で展開開始 - GIGAZINE
MetaがAI強化のため「訴えられてもいいから著作権で保護された作品をかき集めよう」と議論していたとの報道 - GIGAZINE
・関連コンテンツ






in ソフトウェア, Posted by logu_ii
You can read the machine translated English article Meta's basic AI research team publis….