




AIモデルのトレーニングで使えるアニメーション特化のデータセット「Sakuga-42M」が登場

AIモデルを用いて動画を生成するツールは多数ありますが、フォトリアルな動画ではなく二次元のアニメーションを上手く生成することができるツールはほとんどありません。そんな状況を打破すべく、アニメーションに特化した大規模なデータセットとして作成されたのが「Sakuga-42M」です。
[2405.07425] Sakuga-42M Dataset: Scaling Up Cartoon Research
https://arxiv.org/abs/2405.07425
Sakuga-42M Dataset: Scaling Up Cartoon Research
https://arxiv.org/html/2405.07425v1
Stable Video Diffusion(SVD)やSoraといった動画生成AIの登場により、「大規模なデータセットを使用してAIモデルをトレーニングし、自然な動画を理解・生成する」という取り組みは目覚ましい進化を遂げています。しかし、これはあくまで「実写風の動画」にのみに当てはまることであって、アニメーション分野ではそれほど効果的な進捗がみられないと、アルバータ大学のZhenglin Pan氏ら研究チームは指摘しています。これはAIモデルのトレーニングに利用されるデータセットには、大規模なアニメーションのみのものが存在しないためです。
そこで、大規模なアニメーションのみのデータセットとして作られたのが「Sakuga-42M」です。Sakuga-42Mには、さまざまなスタイル・地域・年代のアニメーション動画が含まれており、キーフレームの総数は4200万点とされています。動画データにはテキストでの説明が含まれているだけでなく、コンテンツ分類のためのタグ付けなども行われているそうです。
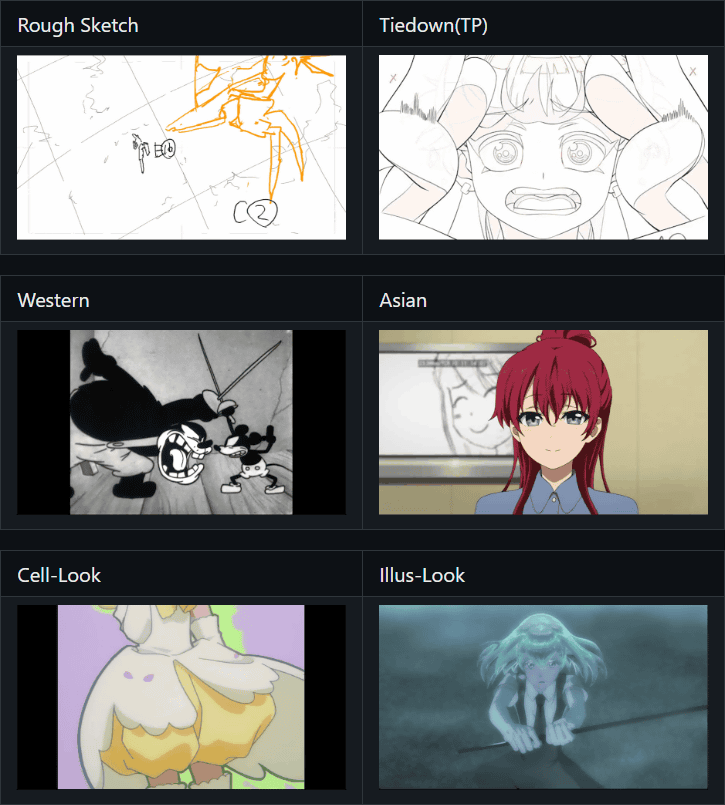
コンテンツ分類の一例が以下。ラフ画や西洋風、アジア風、セルルック、イラスト調などでアニメーションのタイプ別に分類されています。
この他、「金髪、赤髪、茶髪の女の子たちがアイドル衣装を着てステージ上で一列に並んで踊っている」といった具合に、動画内容を説明するための文章も含まれています。

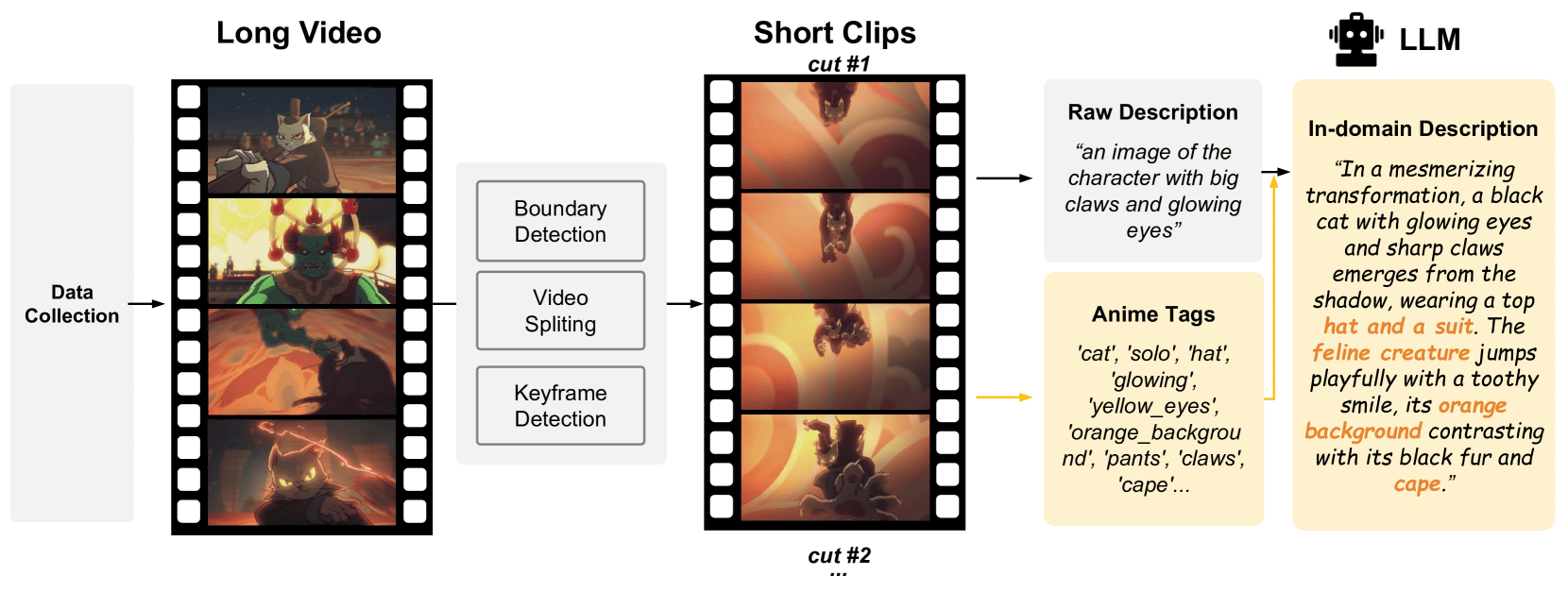
なお、研究チームはSakuga-42M用のデータとして収集したアニメーションの長尺動画を「境界検出」「動画分割」「キーフレーム検出」技術を用いて短尺動画に分割。そして、短尺動画の説明を大規模言語モデル(LLM)を使って自動で出力することで、AIモデルのトレーニングに使用できる情報量を増やしているそうです。
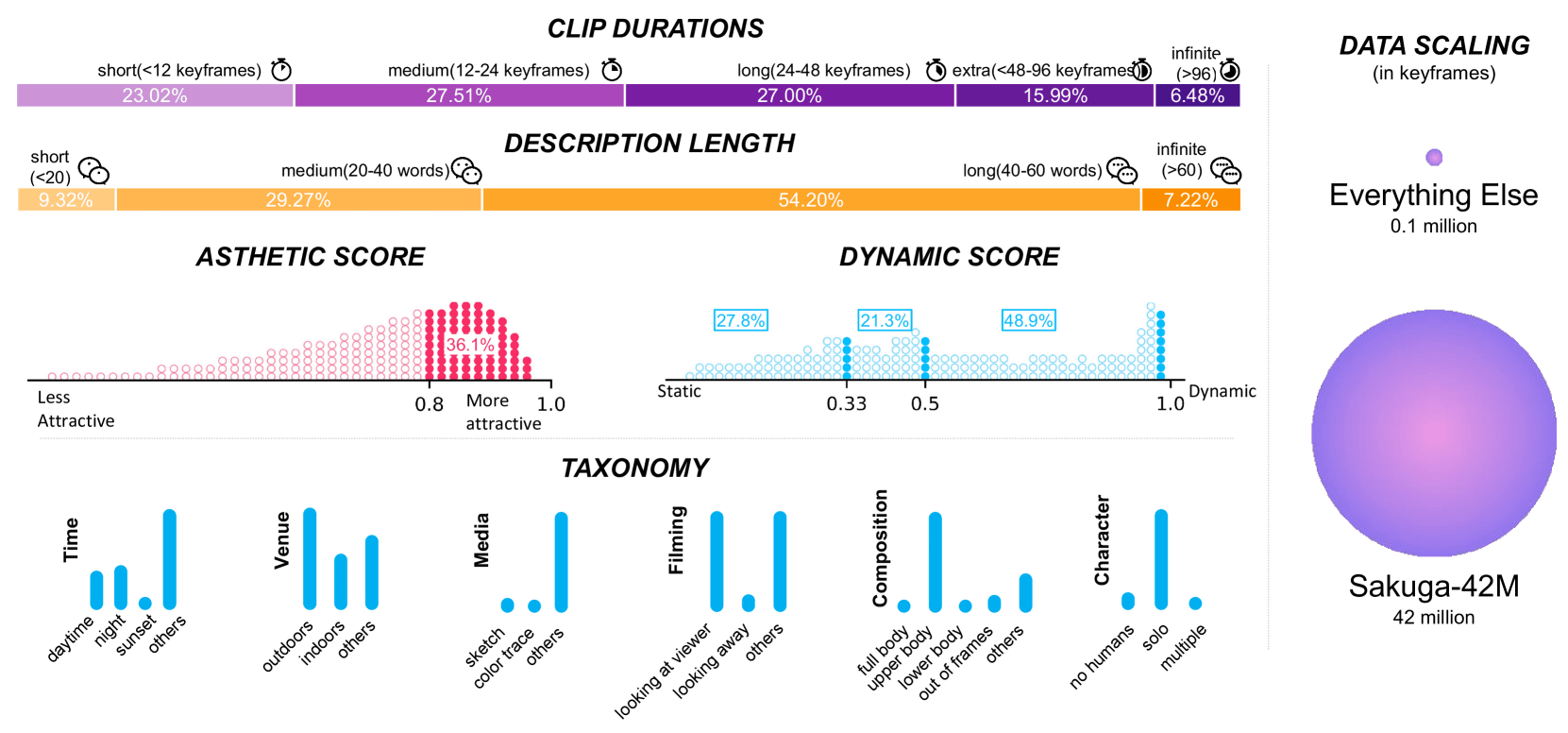
以下はSakuga-42Mに含まれるデータの内訳をまとめた図。「CLIP DURATIONS」(動画の長さ)はショート(キーフレーム数が12以下)が「23.02%」、ミディアム(キーフレーム数が12~24)が「27.51%」、ロング(キーフレーム数が24~48)が「27.00%」、エクストラ(キーフレーム数が48~96)が「15.99%」、インフィニット(キーフレーム数が96以上)が「6.48%」です。「DESCRIPTION LENGTH」(説明文の長さ)はショート(20単語未満)が「9.32%」、ミディアム(20~40単語)が「29.27%」、ロング(40~60単語)が「54.20%」、インフィニット(60単語以上)が「7.22%」です。この他、「ASTHETIC SCORE」(美的スコア)、「DYNAMIC SCORE」(動的スコア)、「TAXONOMY」(分類)に関するデータも含まれています。なお、研究チームによるとSakuga-42Mは既存のあらゆるアニメーション関連データセットを合わせたサイズを超えるデータセットとなっているそうです。
Pan氏らはSakuga-42Mを作成した動機を、「アニメーション研究に大規模スケールを導入し、将来のアニメーションアプリケーションにおける一般化と頑健性を促進すること」と説明しており、さらに「この研究分野で研究者を長年悩ませてきたデータ不足問題が何らかの形で軽減され、より堅牢で移植可能なアプリケーションの登場につながる大規模モデルやアプローチの導入につながり、最終的にアニメーターの創作に役立つようになることを願っています」と述べました。
なお、Sakuga-42MはCreative Commons 4.0の表示-非営利-継承ライセンスのもとGitHubで公開されています。また、学術研究目的でのみ利用可能であり、データセットに含まれる画像や動画の著作権はそれぞれの作者に帰属するという免責事項もあります。
GitHub - zhenglinpan/SakugaDataset: Official Repository for Sakuga-42M Dataset
https://github.com/zhenglinpan/SakugaDataset
・関連記事
2026年までにAIのトレーニングに使うデータが枯渇する「データ不足問題」とは? - GIGAZINE
たった1枚の画像から高品質なアニメーションを作成できる技術が登場、人型のイラストや写真が1枚あれば自由自在に振付を付与できる - GIGAZINE
Appleがプロンプトを入力するだけで静止画をアニメーション化してくれるAIツール「Keyframer」を発表 - GIGAZINE
畳み込みニューラルネットワークの処理についてアニメーションで解説する「Animated AI」 - GIGAZINE
AI成果物が急増したことで「AI生成コンテンツをAIが学習するループ」が発生し「モデルの崩壊」が起きつつあると研究者が警告 - GIGAZINE
OpenAIが動画生成AI「Sora」でどんな動画を作れるか示す作例を大量公開 - GIGAZINE
・関連コンテンツ







in AI, ソフトウェア, Posted by logu_ii
You can read the machine translated English article Introducing 'Sakuga-42M,' an animation-f….