




写真やイラストをリアルに歌わせたりしゃべらせたりできるAIシステム「EMO」が登場

中国のテクノロジー企業・Alibabaのインテリジェント・コンピューティング研究所のチームが、写真や画像をアニメ化してリアルに話したり歌を歌ったりしているように動く映像を生成できるAIシステム「Emote Portrait Alive(EMO)」を発表しました。
EMO
https://humanaigc.github.io/emote-portrait-alive/
Alibaba's new AI system 'EMO' creates realistic talking and singing videos from photos | VentureBeat
https://venturebeat.com/ai/alibabas-new-ai-system-emo-creates-realistic-talking-and-singing-videos-from-photos/
今回、Alibabaの研究者らがプレプリントサーバー・arXivで発表した「EMO」は、入力したオーディオトラックに一致するように、滑らかで表現力豊かな表情と頭の動きを生成することができます。
以下のムービーを再生すると、EMOによって生成された映像を実際に見ることができます。
EMO-Emote Portrait Alive - YouTube
ムービーの冒頭では、オードリー・ヘップバーンのモノクロ写真が歌を歌っています。

インタビュー映像のように話をさせることも可能です。

EMOには拡散モデルと呼ばれるAI技術が使われてています。また、研究者らはモデルをトレーニングするにあたり、合計250時間以上のスピーチ、映画、テレビ番組、歌唱の映像を使用しました。
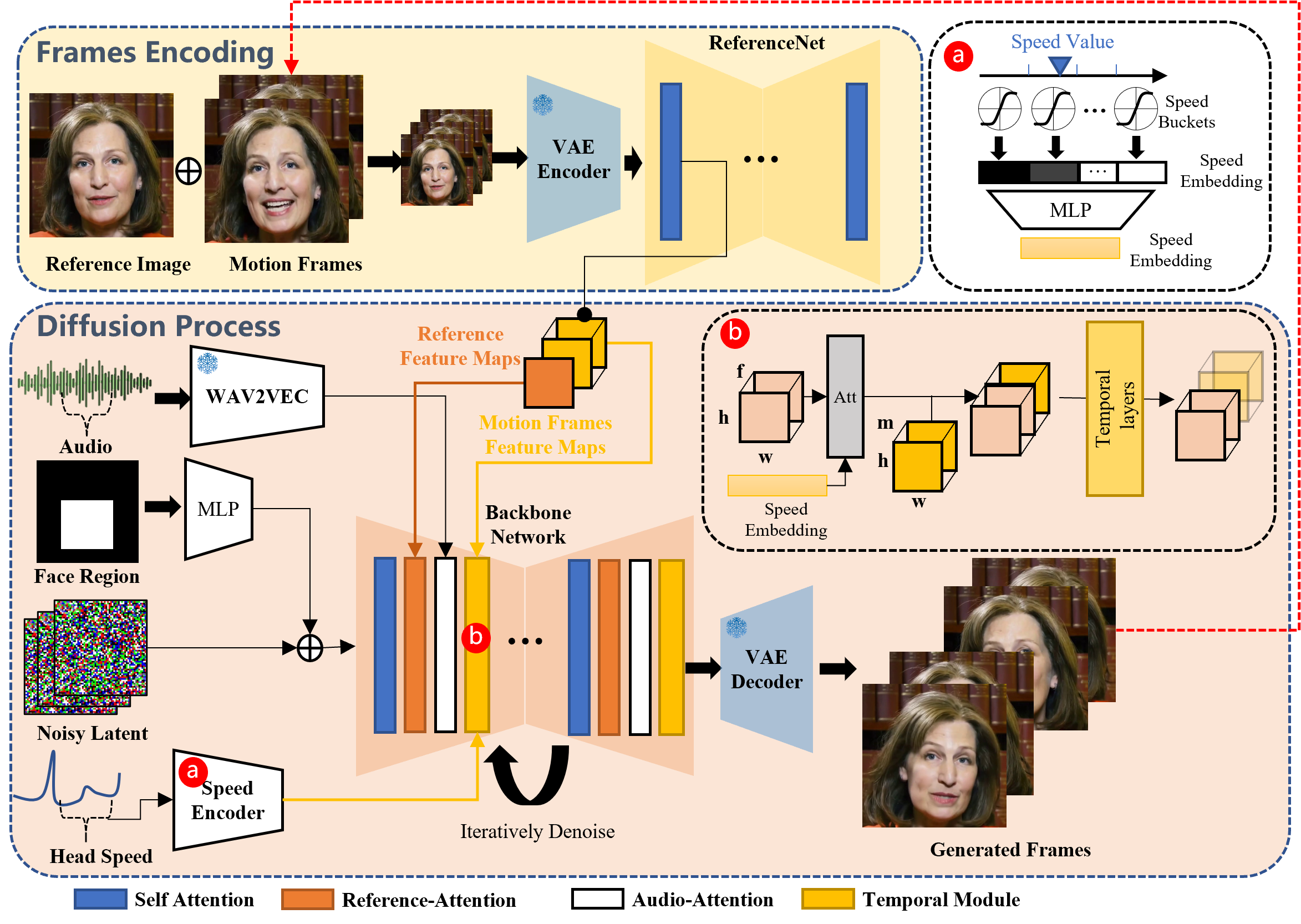
こうして開発されたEMOは、3Dの顔モデルや輪郭の合成に依存して顔の動きを模倣していた従来の方法とは異なり、入力された音声から直接映像を生成します。これにより、歌唱や発話に伴う微妙な動きや固有の癖を捉えて自然な映像を出力することができるようになりました。

歌う映像の出力に必要なのは、1枚の画像と音声だけです。

ラップのように口が激しく動くような歌でも問題ありません。

話す映像も生成可能です。

論文によると、EMOはビデオ品質、アイデンティティの保持、表現力を測定する指標で、これまでの最先端の手法を大幅に上回るスコアを示したとのこと。

研究チームは論文の中で「従来の技術では、人間の表情の全領域を捉えることができないことが多く、また、個々の顔のスタイルの独自性を捉えることができないという限界があります。これらの問題に対処するため、中間3Dモデルや顔のランドマークの指定の必要性を回避し、音声から映像への直接合成アプローチを利用する新しいフレームワークであるEMOを提案します」と述べました。

この技術を使うと、画像と音声を用意するだけでリアルな映像を容易に作成することができます。そのため、モノクロ写真やイラストを歌わせるだけならともかく、実在の人物の顔や声を同意なしに使用したディープフェイク映像などが作成された場合は、重大な問題に発展することが懸念されます。

この技術が誤情報の拡散やなりすましに悪用されるような問題に対応するため、研究者らは合成映像を検出する方法を検討する予定だとしています。
・関連記事
Microsoftがわずか数秒のサンプルから会話や歌声を再現できる音声合成AI「NaturalSpeech 2」を発表 - GIGAZINE
Microsoftがたった3秒のサンプルから人の声を再現できる音声合成AI「VALL-E」を発表 - GIGAZINE
ディープラーニングでリアルタイムに声をボカロのものに変換する試み - GIGAZINE
日本語・英語・中国語でたった3秒の音声から人の声を再現可能なMicrosoftの「VALL-E-X」を独自にトレーニングしたゼロショットモデルが公開中 - GIGAZINE
ディープラーニングで人間と同じトーン・スピード・抑揚を再現して自然な音声を出力する「WaveNet」をDeepMindが開発 - GIGAZINE
YouTubeが「ミュージシャンの声を使った動画を作成するためのAIツール」のリリースに向けてメジャーレーベルと協議を進めている - GIGAZINE
・関連コンテンツ







