




Microsoftがたった3秒のサンプルから人の声を再現できる音声合成AI「VALL-E」を発表

2023年1月5日にMicrosoftが新しい音声合成AIモデル「VALL-E」を発表しました。VALL-Eはたった3秒間の音声サンプルで人の声を忠実にシミュレートできる他、一度学習したデータからは、その人の声色だけではなく感情のトーンや録音環境も再現した合成音声を作成することが可能になっています。
VALL-E
https://valle-demo.github.io/
[2301.02111] Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
https://doi.org/10.48550/arXiv.2301.02111
Microsoft’s new AI can simulate anyone’s voice with 3 seconds of audio | Ars Technica
https://arstechnica.com/information-technology/2023/01/microsofts-new-ai-can-simulate-anyones-voice-with-3-seconds-of-audio/
Microsoftが発表した新しい音声合成AI「VALL-E」は、3秒間の音声サンプルを与えるだけで、元のサンプルの声を忠実に再現したテキスト読み上げモデルを作成することができます。VALL-Eの開発者によると、VALL-Eは高品質の音声合成アプリケーションとして用いることができるだけではなく、録音したスピーチをテキスト原稿から変更して「もともと発言していない内容を話すスピーチ」に音声を編集したり、他のAIモデルと組み合わせることでオーディオコンテンツを作成したりといった用途に使用できるとのこと。
MicrosoftはVALL-Eを「ニューラルコーデック言語モデル」と呼んでいます。一般的な音声合成モデルの「波形を操作して音声を合成する」という手法とは異なり、VALL-Eは「テキストと音響プロンプトから、個別の音声コーデックコードを生成する」という仕組みを採用しています。これはMetaが2022年10月に発表したEnCodecという技術をベースにしており、人の声を分析した情報をEnCodecによって「トークン」と呼ばれる個別の要素に分解し、その声が3秒間の音声サンプル以外のフレーズを話した場合にどう聞こえるかを学習データを使って一致させていく、という流れになっています。
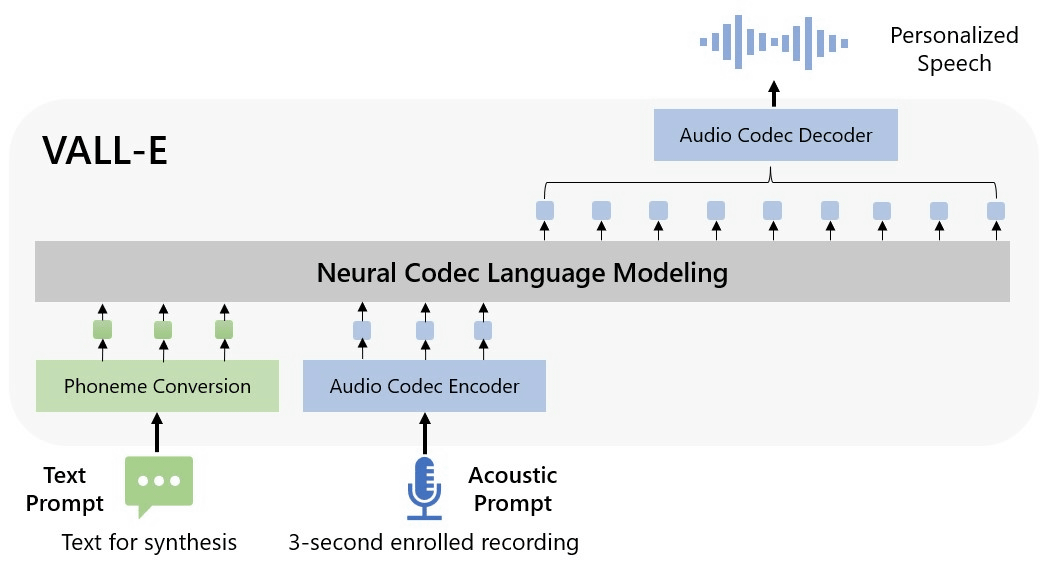
また、MicrosoftはVALL-Eの論文で「VALL-Eは3秒間の録音と音素プロンプトの音響トークンをトリガーとして、対応する音響トークンを生成します。このトークンが話者とコンテンツの情報を規定するものとなり、生成された音響トークンを用いて最終波形を合成します」と説明しています。この音声合成機能にはMetaのLibri-Lightという音声ライブラリが重要になっており、Libri-Lightに収録されている7000人以上の話者による6万時間に及ぶ英語の音声の中から3秒間のサンプル音声に近いものが発見されることで、VALL-Eの結果もより優れたものになるそうです。
VALL-Eのデモページでは、実際に生成された音声を聞くことができます。以下の画像の「Speaker Prompt」はVALL-Eが学習するサンプル用の音声で、左に記されたテキストとは全く異なる内容をごく短い時間だけ話しています。「Ground Truth」の音声は、サンプル音声と同じ人が左に書かれたテキストを読み上げたもので、これが目標となる「正解の音声」となります。「Baseline」が従来のAIモデルで作成した合成音声で、「VALL-E」がVALL-Eで作成した合成音声になります。実際に聴き比べてみると「Baseline」と「VALL-E」の差は歴然で、「Baseline」はノイズが入ったような音声になっている一方で、「VALL-E」は「Ground Truth」と聴き比べても違和感のない音声であることに加えて、音声によっては息継ぎのタイミングなども「Ground Truth」と一致していたものまでありました。

また、VALL-Eは話者の声色や感情表現を再現するだけでなく、サンプルとなった音声の「音響環境」も模倣することが可能とのこと。例として、サンプル音声が電話の音声であった場合は、合成された音声も電話の音響特性や周波数特性をシミュレートして、電話で話している声に聞こえます。
音声合成AIを用いたなりすましや詐欺などの悪用の危険性について、Microsoftは論文で「VALL-Eは話者の同一性を保ったまま音声を合成できるため、偽装やなりすましなど、誤った使い方による潜在的なリスクを抱え込む可能性があります。そうしたリスクを軽減するために、音声クリップがVALL-Eで合成されたものかどうかを判別する検出モデルを構築することも可能です。また、モデルのさらなる開発にあたっては、Microsoftが定めた『責任あるAIの基本原則』を実践していく予定です」と述べています。
・関連記事
AIを使った音声圧縮で従来の圧縮を超えた圧縮率と圧縮速度を「Encodec」が実現 - GIGAZINE
ローマ教皇がMicrosoftやIBMと共同で発表した「AIの倫理に関する呼びかけ」とは? - GIGAZINE
ダース・ベイダーの声をAIが引き継ぐことに - GIGAZINE
無料でさまざまな音声合成エンジンや音声ライブラリを扱える汎用合成音声エディタ「ユニコエ」が登場 - GIGAZINE
マイクで録音するだけで誰でも「結月ゆかり」や「琴葉 茜・葵」の声になれるAI音声合成ソフト「Seiren Voice」を使ってみた - GIGAZINE
まるで本物の人間のように表現力豊かに発話できるAIをNVIDIAが開発中 - GIGAZINE
・関連コンテンツ







in AI, ソフトウェア, Posted by log1e_dh
You can read the machine translated English article Microsoft announces speech synthesis AI ….