Microsoft announces speech synthesis AI ``VALL-E'' that can reproduce human voice from a sample of only 3 seconds

On January 5, 2023, Microsoft announced a new speech synthesis AI model ' VALL-E '. VALL-E can faithfully simulate human voices with only 3 seconds of voice samples, and from once learned data, it can create synthetic voice that reproduces not only the tone of voice of the person, but also the emotional tone and recording environment. It is now possible.
VALL-E
[2301.02111] Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
https://doi.org/10.48550/arXiv.2301.02111
Microsoft's new AI can simulate anyone's voice with 3 seconds of audio | Ars Technica
https://arstechnica.com/information-technology/2023/01/microsofts-new-ai-can-simulate-anyones-voice-with-3-seconds-of-audio/
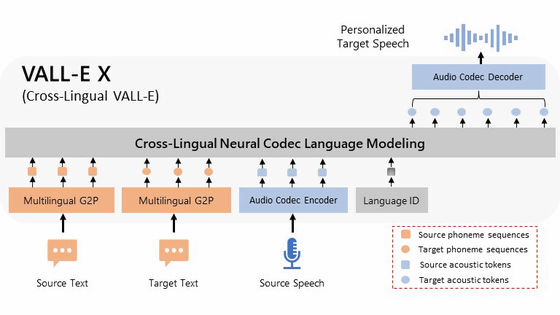
The new speech synthesis AI ``VALL-E'' announced by Microsoft can create a text-to-speech model that faithfully reproduces the voice of the original sample by simply giving a 3-second speech sample. According to VALL-E's developer, VALL-E can not only be used as a high-quality speech synthesis application, but it can also convert recorded speech from text manuscripts into 'speech that speaks what was not originally said'. It can be used for purposes such as editing and creating audio content by combining with other AI models.
Microsoft calls VALL-E a 'neural codec language model'. Unlike the general speech synthesis model, which ``manipulates the waveform to synthesize speech'', VALL-E adopts a mechanism of ``generating individual speech codec codes from text and acoustic prompts''. increase. This is based on the technology called EnCodec announced by Meta in October 2022, and the information obtained by analyzing the human voice is decomposed into individual elements called 'tokens' by EnCodec, and the voice is a 3-second audio sample. The flow is to use learning data to match how it sounds when you speak other phrases.
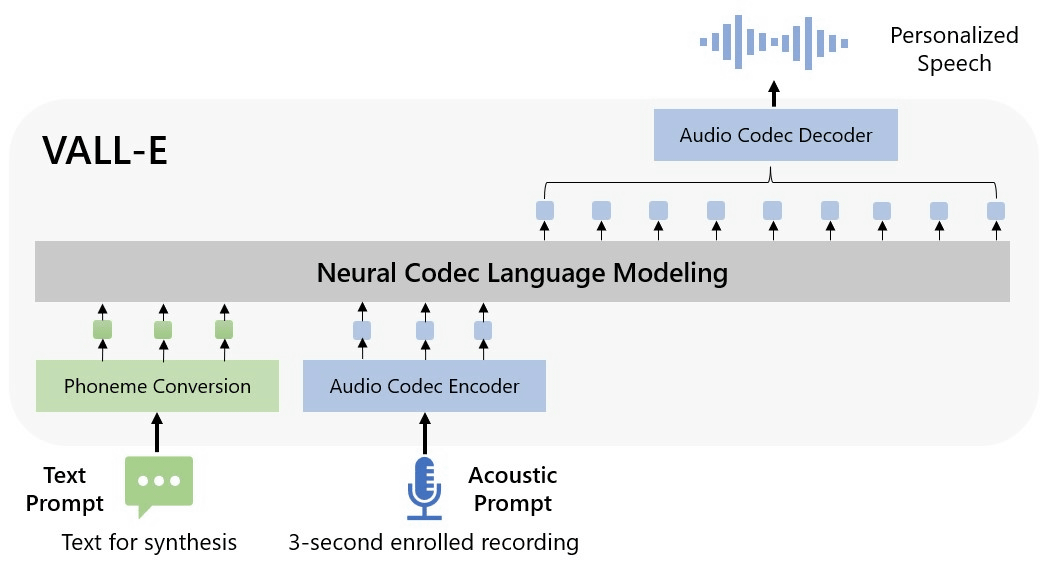
In addition, Microsoft stated in the VALL-E paper, ``VALL-E triggers a 3-second recording and an acoustic token of a phoneme prompt to generate a corresponding acoustic token. This token defines the speaker and content information. It becomes a thing and uses the generated acoustic tokens to synthesize the final waveform.” Meta's
You can listen to the actual generated sound on the VALL-E demo page . 'Speaker Prompt' in the image below is a sample voice for VALL-E to learn, and speaks completely different content from the text on the left for a very short time. The voice of 'Ground Truth' is the same person as the sample voice reading the text written on the left, and this is the target 'correct voice'. 'Baseline' is the synthesized voice created by the conventional AI model, and 'VALL-E' is the synthesized voice created by VALL-E. When you actually compare them, the difference between 'Baseline' and 'VALL-E' is obvious. 'Baseline' sounds like noise, while 'VALL-E' sounds like 'Ground Truth'. In addition to being a sound that does not feel uncomfortable even if you compare it with , depending on the sound, there were even times when the timing of breathing was consistent with 'Ground Truth'.

In addition, VALL-E can not only reproduce the voice tone and emotional expression of the speaker, but also imitate the 'acoustic environment' of the sampled voice. As an example, if the sample voice was a phone voice, the synthesized voice would also simulate the acoustic and frequency characteristics of the phone and sound like someone speaking on the phone.
Regarding the dangers of misuse such as impersonation and fraud using speech synthesis AI, Microsoft said in a paper, ``Since VALL-E can synthesize speech while maintaining the identity of the speaker, To mitigate such risks, it is possible to build a detection model to determine whether an audio clip was synthesized with VALL-E. In development, we plan to practice the 'Basic Principles of Responsible AI' defined by Microsoft.'
Related Posts: