Google explains the current state of voice generation AI, can generate 40 seconds of conversational audio in just one second, but humans say it sounds 'eerie'

Google posted a blog post about the current capabilities of its voice generation AI.
Pushing the frontiers of audio generation - Google DeepMind

In September 2024, Google released ' Illuminate ,' which summarizes the contents of papers and books and converts them into podcast-style conversational audio, and added a feature to its AI-based note-taking app 'NotebookLM' that provides an overview in conversational audio .
It is thanks to many years of research that it has become possible to generate speech with such characteristics as 'more than tens of seconds,' 'multiple speakers,' and 'natural conversation.' The SoundStream technique, which appeared in August 2021, makes it possible to reconstruct speech while maintaining information such as prosody and timbre, and the AudioLM technique, which appeared in October 2022, makes it possible to treat the speech generation task as a language modeling task that generates acoustic tokens.
Then, in June 2023, SoundStorm demonstrated the ability to generate natural 30-second conversations with multiple speakers. As of October 2024, it will be possible to generate two minutes of audio. The TPU v5e chip takes less than three seconds to generate two minutes of audio, which is more than 40 times faster than actual recording.
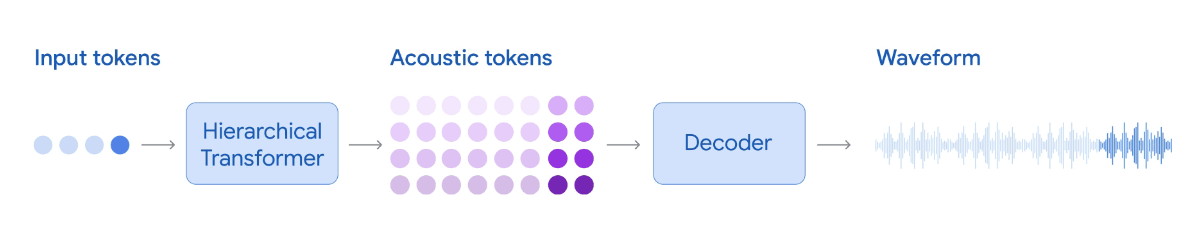
An example of an actual generated voice looks like this: 'Hey, have you heard about Google DeepMind's speech generation achievements?' 'No, I missed it.'
To improve its ability to generate realistic conversations with multiple speakers, the model was pre-trained on hundreds of thousands of hours of audio data, and then fine-tuned on a smaller dataset consisting of unscripted conversations by a large number of voice actors and audio data containing fillers such as 'ah' and 'uh.' This allows the model to reliably switch speakers during a conversation and output speech with appropriate pauses and tones.
Although the editorial staff, whose first language is Japanese, found it difficult to distinguish from native speaker speech, native English speakers found the generated dialogue unnatural, with comments such as ' it's very frustrating to listen to ' and ' it sounds like they're reading a prepared script .'
Related Posts:







in Free Member, AI, Software, Posted by log1d_ts