Microsoft announces speech synthesis AI 'NaturalSpeech 2' that can reproduce conversations and singing voices from samples of just a few seconds

On April 18, 2023, a research team led by Kai Shen of
[2304.09116] NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers
https://doi.org/10.48550/arXiv.2304.09116

Natural Speech 2
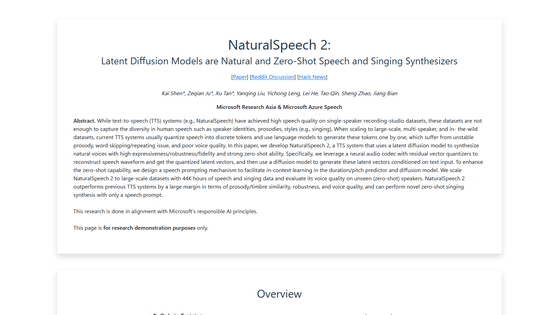
Conventional TTS systems have achieved high speech quality on single-speaker recording datasets, but these datasets are incapable of capturing the diversity of human identities and styles such as accents. . Also, when scaling to large, multi-person datasets, current TTS systems typically quantize speech into discrete tokens and use language models to generate tokens one-by-one, resulting in instability. Problems with prosody, skipping and repeating words, and poor voice quality are problems.
However, in 'NaturalSpeech 2' developed by Shen et al.'s research team, by using a latent diffusion model, it has high expressive power and reproducibility, and creates a text-to-speech model that faithfully reproduces the voice of the sample. is possible.
NaturalSpeech 2 reconstructs the waveform of the input speech using
A paper published by Shen et al.'s research team actually presents an example of speech synthesis using NaturalSpeech 2. The following was learned using
The voice of 'Ground Truth' is a text read aloud by the same person as the sample voice, and this is the target 'correct voice'.
“Baseline” below is a synthesized voice created with a conventional AI model. There is no intonation, it is somewhat unnatural and mechanical, but it outputs a voice close to humans.
The audio output using NaturalSpeech 2 is below. It can be confirmed that the level of voice output is comparable to that of ``human voice'' in terms of breathing and accent.
Below is an example of learning using ' VCTK ' by a research team at the University of Edinburgh. To generate the speech 'We will turn the corner.', we first input an unrelated speech.
Below is the audio for 'Ground Truth'.
The audio output in 'Baseline' is as follows.
The following is the voice of 'Turn the corner' output using NaturalSpeech 2.
The research team is also comparing with the speech synthesis AI model ' VALL-E ' developed by Microsoft. 'Thus did this humane and right-hearted father comfort his unfortunate daughter, and his mother embraced her again, and did all she could to make her feel better.' Minded father comfort his unhappy daughter, and her mother embracing her again, did all she could to soothe her feelings.)” below is the audio output by VALL-E.
Below is the audio output using NaturalSpeech 2.
NaturalSpeech 2 can also input and output singing voice. Below is an example of singing with the lyrics 'So listen very carefully.' First, enter irrelevant sentences.
Then, it will be output as a singing voice with intonation and rhythm.
NaturalSpeech 2 can also input from singing voice. In the example below, the same ' BINGO ' is sung.
In the example below, it is shown that even if singing input is performed, singing voice will be output as well.
Microsoft's research team warns that ``NaturalSppech 2 is capable of faithful expression, and there is a risk of being abused by imitation or impersonation of the speaker.'' Also, in order to avoid these ethical and potential problems, the research team ``appeals to developers not to abuse this technology and to develop countermeasure tools to detect voice synthesized by AI. I am,” he claims. ``When developing such AI models, we always adhere to Microsoft's responsible AI principles, '' he said.
The source code of NaturalSpeech 2 is published on GitHub.
GitHub - lucidrains/naturalspeech2-pytorch: Implementation of Natural Speech 2, Zero-shot Speech and Singing Synthesizer, in Pytorch
https://github.com/lucidrains/naturalspeech2-pytorch
Related Posts:







in Software, Posted by log1r_ut