An attempt to convert a voice to a vocaloid one in real time with deep learning

byisrael palacio
Using my artificial intelligence (AI) to realize my own voice with VOCALOID "Yuitsuki YukariThe programmer's success in converting it toHihoMr. You can tell what it is all about by watching the following movies.
I tried to voice Yukari Yukari with the power of deep learning - YouTube
I tried to get the voice of Yuzuki as a voice of Deep Learning by Hiko Nico Nico Technical Department / Movie - Nico Nico Douga
The movie starts from a sudden question "Do not want to become Yukari obsessed?"

He seems to have used deep learning to realize this goal.

That's why the commentary on how to do it starts from here.

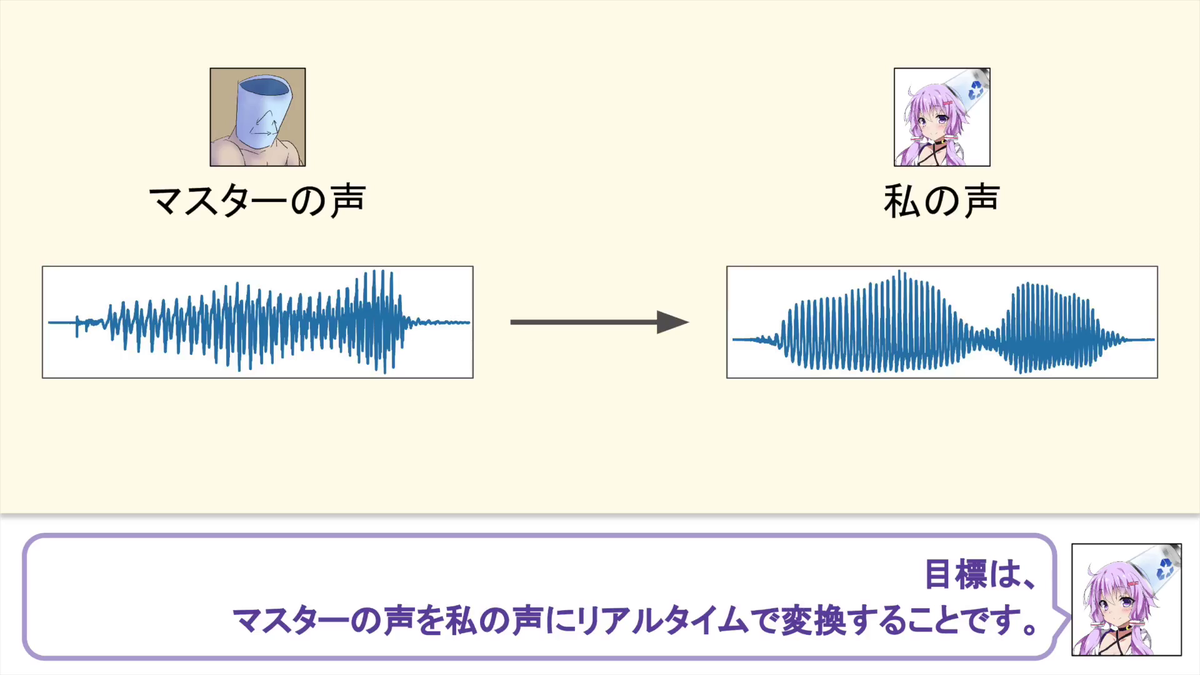
The goal is to convert the voice of Master (Hiroshi) to the voice of I (Yukari Yukari) in real time.
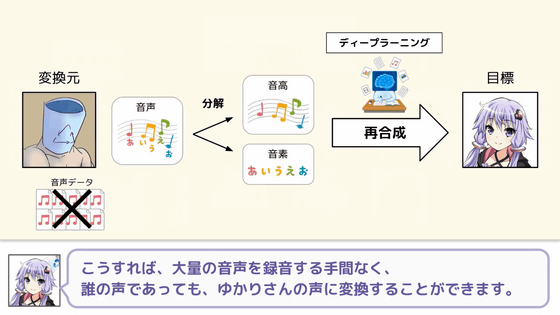
The process of common speech conversion is a technique to convert a voice into a sentence using speech recognition as follows and let it be read by voice synthesis software such as VOCALOID.
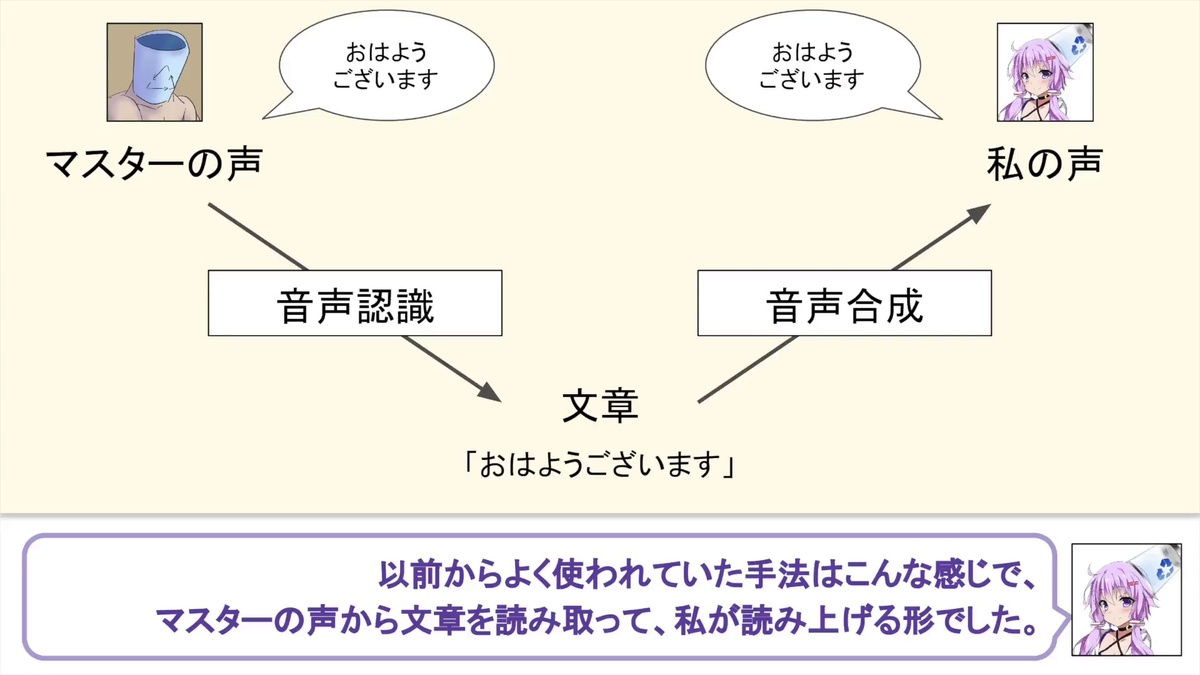
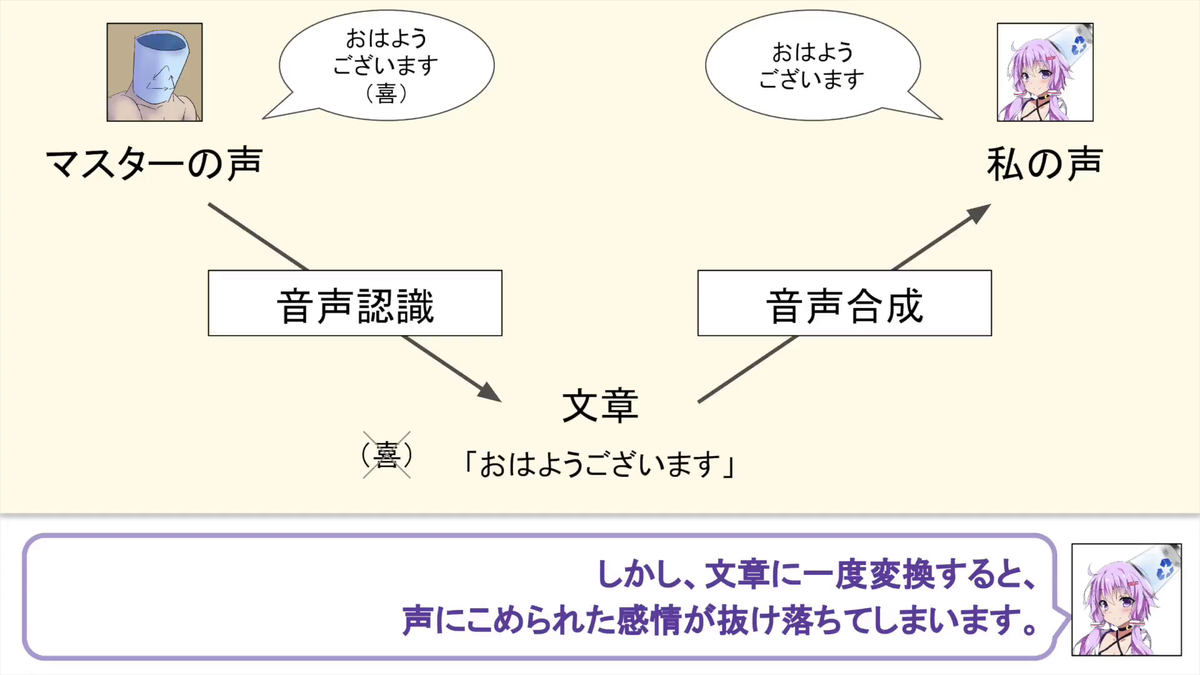
Even with this method, you can be the voice of Yuuki Yukari, but I can not tell you the emotions contained in the voice.
That's why I tried to convert the voice in real time.
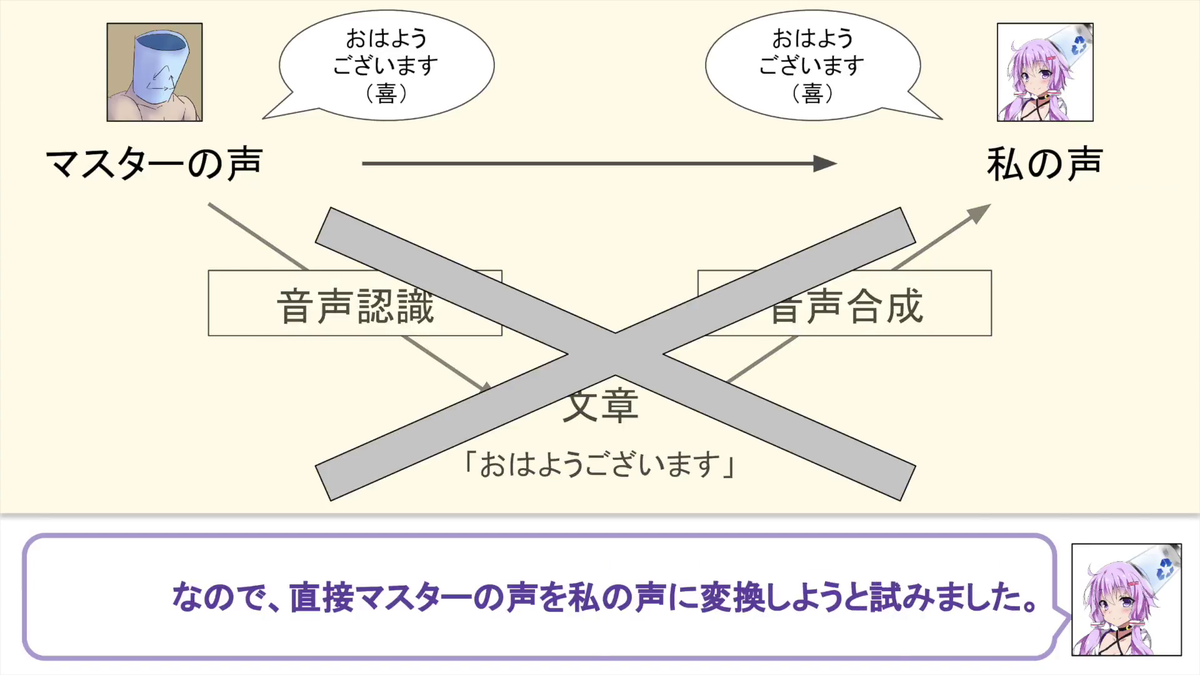
I used one of the machine learning methods "Deep learning".

That's why the demonstration will flow right away. The voice of the contributor flows to the left ear and the voice converted to Yuzuki Yukari flows to the right ear. Although it is not perfect when listening, it seems that emotions remain in the voice rather than normal speech conversion.

And for this technical details of the method "I tried to voice Yukari Yukari using AI" is written on Mr. Hiyoh's blog.
I tried becoming voice of Yuzuki by the power of deep learning | Hiho's Blog
https://hiroshiba.github.io/blog/became-yuduki-yukari-with-deep-learning-power/

With the development of CG and motion capture technology, the number of people converting the figure to a virtual girl is increasing, but there are many problems to be heard about voice. The problem seems to have used deep learning aiming at low delay, high quality sound quality conversion that solved these problems, such as "delay" "sound quality" "multiple speakers". Mr. Hiho pointed out that "I used a model that was good in the image deep learning field", "I divided the voice quality conversion into the" low voice quality conversion "part and the" high sound quality "part", " Conversion is one-dimensionalpix2pix model, And 2-dimensional pix 2 pix model was used for conversion of spectrogram ". On the blog, input voice and converted voice that can actually take a glimpse of the process of voice quality conversion are embedded, so you can check the process of voice quality conversion with your ear.
The code used to become the voice of Yuzuki by the power of deep learning is published below, so if anyone learns the voice with deep learning, everyone can become interested in the fare.
GitHub - Hiroshiba / become - yukarin: repository which becomes voice of Yuzuki by the power of deep learning

Related Posts: