Google announces the revolutionary system 'Translatotron' which translates while keeping the voice of the speaker by voice translation

by
Google unveiled the details of ' Translatotron ', which translates speeches of people while maintaining their voices. It is an innovative system that uses an end-to-end model different from the conventional model, and is considered to open up the future of speech translation.
Google AI Blog: Introducing Translatotron: An End-to-End Speech-to-Speech Translation Model
https://ai.googleblog.com/2019/05/introducing-translatotron-end-to-end.html
In the past speech translation, first, the content spoken by the speaker was awakened as a sentence by automatic speech recognition, from which the speech was output through machine translation. While the “cascade model” combining different translation methods such as speech-text-speech has been the conventional method, Translatotron has adopted an end-to-end approach that completes speech translation from the beginning to the end. It is a feature. Because the process is simple, it can translate faster than conventional methods.
'As far as I know, Translatotron is the first model to translate voice directly from one language to another. Translatotron can also keep the speaker's voice in the translated voice,' said Google. The researchers say.

by
The accuracy of the Translatotron indicated by the BLEU score, which is a quality evaluation method for machine translation, is slightly lower than that of the cascade system, but seems to be more accurate than the standard value of the translation of the cascade model.
The end-to-end model of machine translation was first presented in a paper in 2016 and has been studied since then. The end-to-end model is proven in 2017 to be superior to the cascade model.
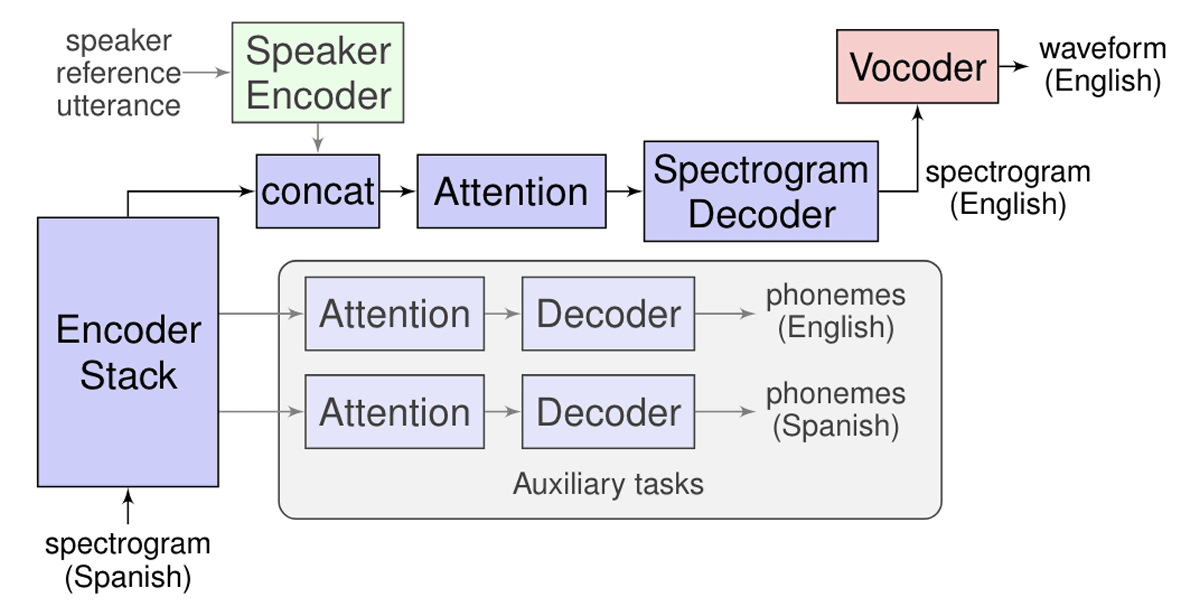
Translatotron takes as input the information of the spectrogram as input and is based on the network of Sequence to Sequence that produces the translation content of the target language as the spectrogram. It also uses a 'neural vocoder ' that changes the output spectrogram into a time domain waveform, and uses a 'speaker encoder' that maintains the speaker's speech and synthesizes the translated speech. Is also a feature.
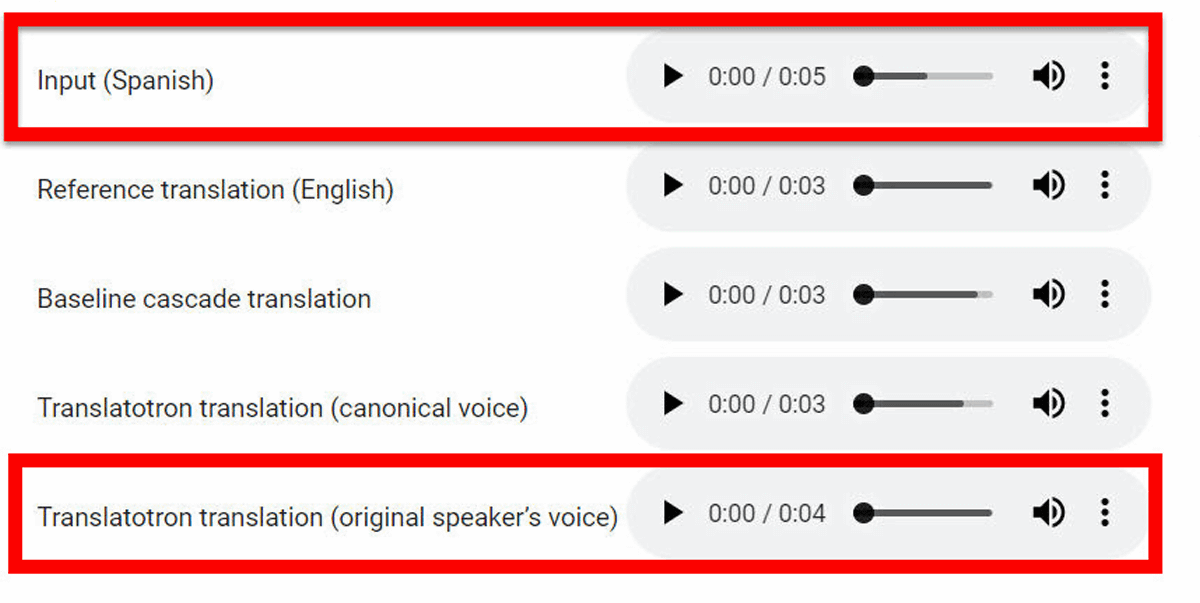
The actual voice translation by Translatotron can be checked from the following page. 'Input (Spanish)' is the voice before translation, 'Translatotron translation (original speaker's voice)' is the voice translated while maintaining the tone of the voice.
Besides this, you can listen to Translatotron's voice translation from here .
Related Posts:








in Software, Posted by darkhorse_log