A system that reads the signal of the brain and converts it into 'understandable conversation voice by listening with ears'

by rawpixel
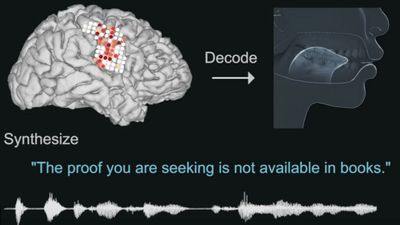
At Columbia University neuro-engineering Nima Mesugarani Associate Professor to study has created a system for converting a signal of the brain to "intelligible conversation voice heard in the ears". With this system you can understand what you are thinking about just by reading the signal of the brain without putting it out.
Towards reconstructing intelligible speech from the human auditory cortex | Scientific Reports
https://www.nature.com/articles/s41598-018-37359-z
Columbia Engineers Translate Brain Signals Directly into Speech | Zuckerman Institute
https://zuckermaninstitute.columbia.edu/columbia-engineers-translate-brain-signals-directly-speech
Associate Professor Masugarani developed a system to convert brain waves directly into conversational speech using computer. This system is capable of generating human spoken words from EEG at an unprecedented level so far. The system utilizes the speech synthesizer and artificial intelligence, and expectation is gathered as a technology leading to a new way for computers to communicate directly with the brain.
The system of Associate Professor Masugarani, such as amyotrophic lateral sclerosis (ALS) patients and those who recovered from stroke, those who are functioning but can not speak well can not regain communication ability with the outside world It may be of help. The research result of Associate Professor Masugarani is published in Scientific Reports of scientific journal.

by Daniel Sandvik
Associate professor Mosgarani who served as a leader in research to convert brain waves to conversational speech that can be understood directly, said, "Our voice is useful for connecting with surrounding friends, family members and people all over the world, It is a very sad thing that my voice can not be output due to injury or illness, but with this research, we have found a way to regain that power (to say a voice) With the right technology I could show that people who can not speak once will be able to conduct conversations that can be understood again by listeners. " I am talking about the significance of research.
From research over the past decades, it has become clear that a clear activity pattern appears in the human brain, even when human beings utter a word or even imagine talking about something. Also, when listening to someone's story or imagining hearing it, a clearly recognizable signal pattern appears in the brain. Research that records these patterns and deciphers the contents has been done so far.
Associate Professor Masugarani also researched to decipher the contents which he was trying to talk about from the brain signal in the same way, early research in the field analyzed the signal recorded from the primary auditory cortex of the brain, and the content of conversation We are creating a computer model to reconstruct. However, with this approach it was difficult to generate easy-to-understand conversational speech, so research teams such as Associate Professor Masugarani will challenge another method. The method was a vocoder approach using "analyzing the content of conversation from a signal with a computer algorithm trained using human conversational speech and expressing speech voice with synthetic speech".
by rawpixel
Associate Professor Masugarani et al. Researchers and team members Ashesh Dinesh Mehta and others who are neurosurgeons working at the Great Neck Neuroscience Laboratory and coauthors of research papers to teach the vocoder about brain activity patterns I am assembling. Mr. Mehta is a person who has been treating epilepsy patients, and it seems that some of the patients had the problem of having to undergo surgery on a regular basis.
The research team conducted a survey to measure patterns of brain activity while listening to conversation for epilepsy patients already undergoing brain surgery operations. By having the vocoder learn the brain activity pattern recorded at this time, I trained to predict "what conversation contents are imaged" from the brain activity.
Subsequently, the researchers asked the subject "a voice counting numbers from 0 to 9", and the brain activity pattern recorded at that time was input to the vocoder. Then, the vocoder succeeds in outputting original synthesized speech from the brain activity pattern which occurred when hearing "voice counting numbers from 0 to 9". This sound is analyzed by a kind of artificial intelligence neural network that mimics the neuron structure in the brain biologically, and it is the following voice that we have processed to the level that can be heard by humans.
By clicking the image below, you can play "voice generated by analyzing brain activity pattern" by the system developed by Associate Professor Masugarani et al. Although it is hard to hear it, you can see that he reads the numbers 0 to 9 in English.
As a result of the experiment, it seems that the probability that the system can correctly generate conversation contents from brain wave was 75%. This is a remarkably excellent accuracy among similar attempts in the past, and the easiness to understand of the generated speech was incorrect even compared with the results of previous research by Masugarani. Regarding the experimental results, Associate Professor Mosgarani said, "By combining a sensitive vocoder and a powerful neural network, we were able to generate the sound the patient was listening with amazing accuracy."
In the future, the research team plans to conduct similar tests with more complex words and sentences. Also, rather than generating conversation speech from "brain signal when listening to the story", it seems that it is also considered to conduct experiments to generate speech sounds from "brain signals when trying to talk" is. As a final goal, the research team cites the development of implant technology for epileptic patients to express their own ideas directly as language.
In addition, Associate Professor Masugarani says, "This system will bring about major change, because it gives us new opportunities to connect with the world again for those who have lost the ability to talk whether they are injured or sick It is because it is.
Related Posts: