Meta releases Spirit LM, the first open source multimodal language model that can integrate text and speech input and output

On October 18, 2024, Meta released Spirit LM , an AI model that can accept both text and voice input and output voice with emotional expressions.
SPIRIT-LM: Interleaved Spoken and Written Language Model
(PDF file)
Sharing new research, models, and datasets from Meta FAIR
https://ai.meta.com/blog/fair-news-segment-anything-2-1-meta-spirit-lm-layer-skip-salsa-lingua/

Spirit LM Interleaved Spoken and Written Language Model
Open science is how we continue to push technology forward and today at Meta FAIR we're sharing eight new AI research artifacts including new models, datasets and code to inspire innovation in the community. More in the video from @jpineau1 .
— AI at Meta (@AIatMeta) October 18, 2024
This work is another important step… pic.twitter.com/o43wgMZmzK
On October 18, 2024, Meta's Fundamental AI Research (FAIR) team published its latest research results and new AI models toward realizing advanced machine intelligence (AMI), reporting the release of Segment Anything Model 2.1 (SAM 2.1), an updated version of the image and video segmentation model Segment Anything Model 2 (SAM 2), and the sharing of SALSA , code necessary for research into the security of post-quantum cryptography standards.
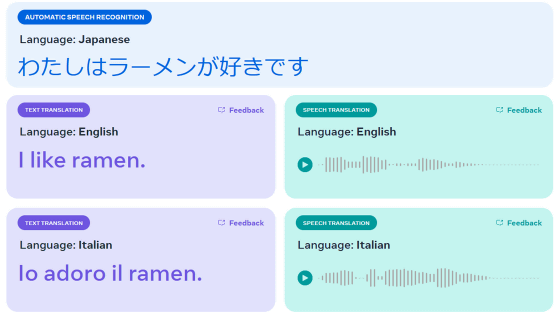
Among them, Meta announced 'Spirit LM', an open source language model that can seamlessly integrate voice and text. According to Meta, the conventional 'AI that can converse by voice' transcribes the input voice using automatic speech recognition (ASR), generates text using a large-scale language model based on the transcription data, and finally converts it into voice using text-to-speech software (TTS). However, the conventional process impairs the expressive aspects of the generated voice. Meta's newly developed Spirit LM can process text and voice in a single model, enabling voice conversation without ASR transcription or voice conversion by TTS.
Here's a demo of Spirit LM in action: In the example below, Spirit LM listens to the text '1 2 3 4 5' and outputs the numbers that follow.
Additionally, in response to a text prompt like 'The largest country in the world is,' Spirit LM can output a voice output with more detailed information.
It can also generate human-like emotional voices based on given prompts. The following is a voice following a text prompt: 'I can't believe she's gone. I don't know how to cope without her. The pain of losing her is overwhelming. I feel so lost without her.'
Below is the result of outputting the text prompt 'Did you hear that? What is that sound? I'm really scared. It's so dark, and that noise... it sounds so creepy.'
Spirit LM can also respond to voice input with text. When you type 'abcde' into Spirit LM by voice, the text 'fghijklmnopqrstuvwxyz' is returned. You can check the voice input into Spirit LM from the following.
According to Meta, Spirit LM is trained with word-level interleaved learning on speech and text datasets, enabling cross-modality generation of speech input and output. To achieve this, Meta developed 'Spirit LM Base', which uses speech tokens to model speech, and 'Spirit LM Expressive', which uses pitch and style tokens to capture information about tones such as excitement, anger, and surprise, and can generate speech that matches that tone.
'Spirit LM is able to produce more natural-sounding speech and has the ability to learn new tasks across modalities, including automatic speech recognition, text-to-speech, and speech classification. We hope our work will inspire the larger research community to continue to advance speech-text integration,' Meta said.
You can request to download the model data from the following page.
Spirit LM access request form - Meta AI
https://ai.meta.com/resources/models-and-libraries/spirit-lm-downloads/
In addition, the source code of Spirit LM can be downloaded from the following GitHub page.
GitHub - facebookresearch/spiritlm: Inference code for the paper 'Spirit-LM Interleaved Spoken and Written Language Model'.
https://github.com/facebookresearch/spiritlm
Related Posts:






in Software, Posted by log1r_ut