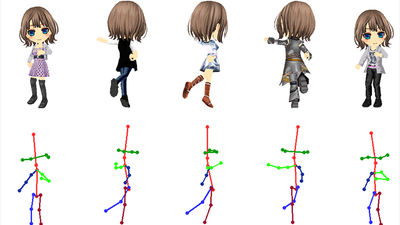
A Google engineer announces a system that anyone can become a VTuber with just one character image and webcam

Pramook Khungurn, a software engineer at Google Japan, has announced a system that enables natural movement as a
Talking Head Anime from a Single Image
https://pkhungurn.github.io/talking-head-anime/
You can see how the VTuber system actually developed by Mr. Khungurn looks like by watching the following movie.
I tried to make a system that can become VT Tube without modeling with one character image-Nico Nico Douga
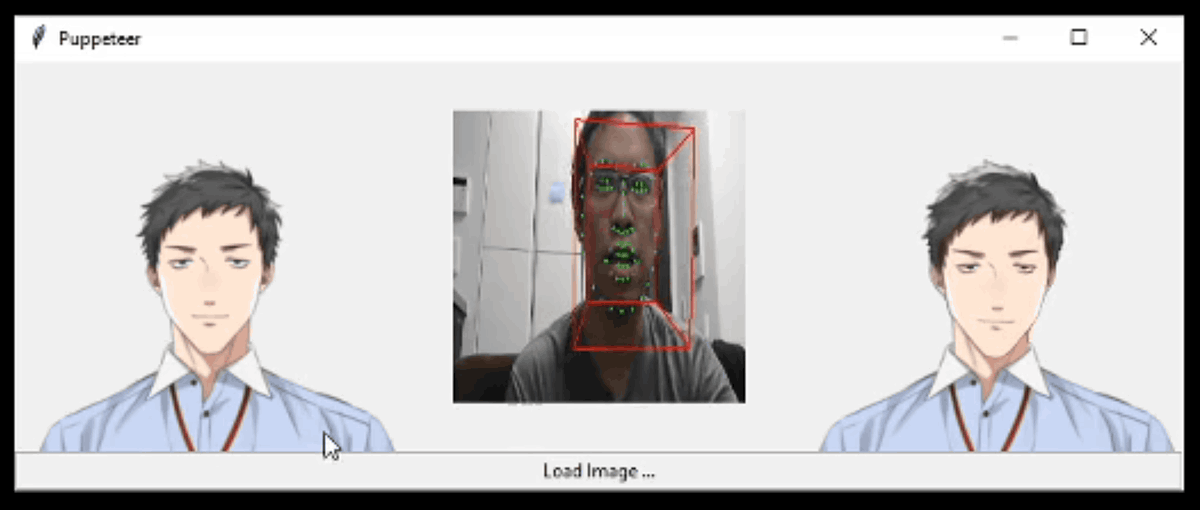
For example, rainbow disaster affiliation of fairy original KoRyo of the Standing picture reads the (left), and Mr. Khungurn is superimposed a result of the face recognition in the video taken by a web camera (center), Ya slope of the neck of Mr. Khungurn You can see the face and mouth of the standing picture move according to the movement of the mouth and eyes.
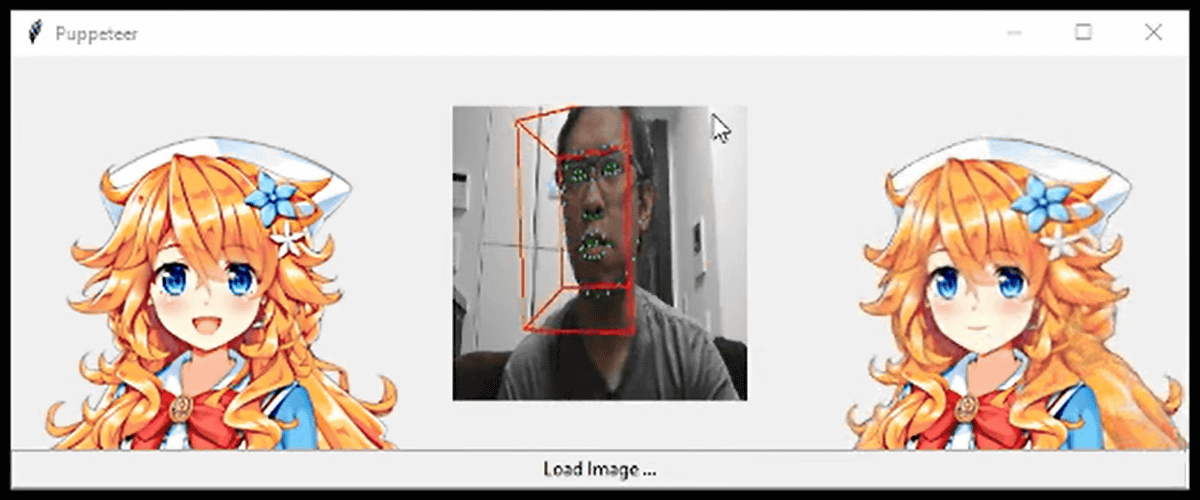
However, if the mouth is not open at the time of standing picture, it is a specification that can not handle the opening and closing of the mouth automatically. In the following example, closing the mouth at the falling picture
While a debut planned as a rainbow disaster of belonging Vtuber, in the article creates the time has not yet come out into the world
Khungurn's system can be applied not only to 2D standing pictures but also to 3D model images. Actually, in the movie, a test that moves like a pseudo 3D model using the image of that 3D model when it is a VTuber belonging to Holo Live is performed.

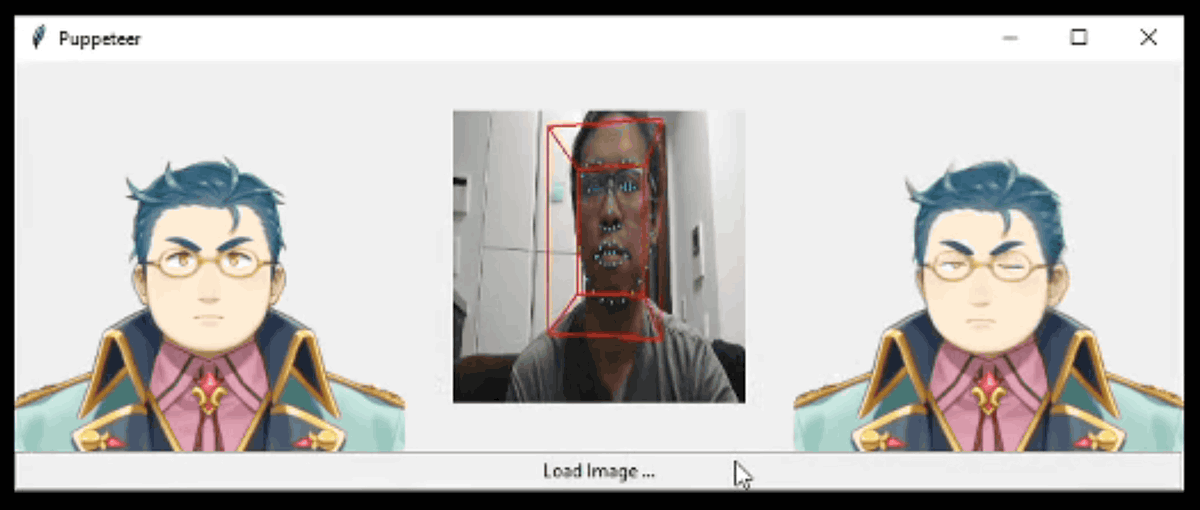
Khungurn's system is designed to respond to hairstyles properly, so the unique hairstyle and long elf-specific ears that are described as “like a

Even in the 2D model, the eyes of
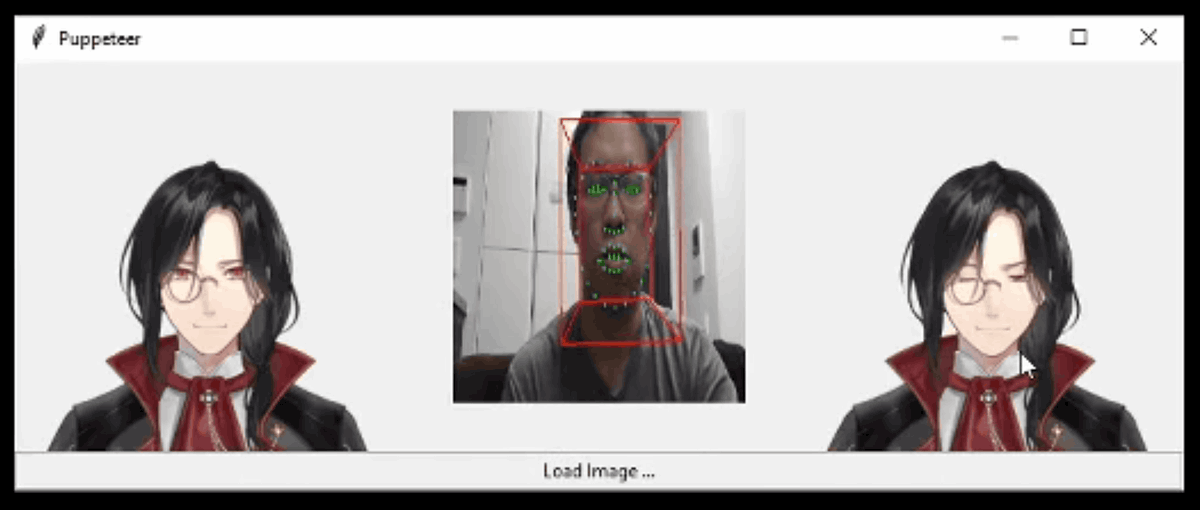

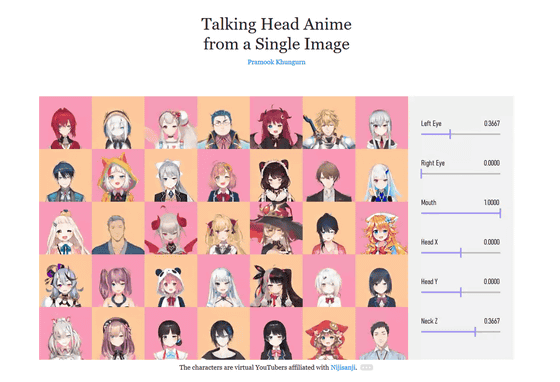
Khungurn developed the VTuber system using this deep neural network because he was fascinated by the Japanese VTuber boom. Khungurn first inputs the facial image of the anime character into the algorithm, and adjusts the 'head movement', 'eye movement', and 'mouth movement' with the sliders, and a system that outputs the changed facial image accordingly. Developed. You can see what kind of system it is in one shot by watching the following movie.
A tool for animating faces of anime characters from single images.- YouTube
And by connecting this system with a face tracker, one picture can move by imitating the movement of the face captured by the camera. Of course, you can transfer facial motion from existing video as well as webcam. Mr. Khungurn is as a demonstration, Obama former president to address fairy original KoRyo-Takamiya Rion- Waifu Labs to the girl that was randomly generated by the server beauty meat has published the manner in which was in the movie.
Transfer Barack Obama's motion to anime characters-YouTube
Khungurn says there are still some limitations, but if this system is applied, conversation animation can be generated without creating a character model, which can greatly reduce the cost of VTuber and animation production. In addition, he insisted on the advantage of being easy to use because it can receive character images as direct input and control the characters intuitively.
In addition, the development of this system has nothing to do with the work Khungurn is engaged in Google, and he said that he does not use any Google resources. Khungurn said that he would acquire the software copyright through Google's internal review process and formally publish it as a paper.
Related Posts: