A zero-shot model that independently trained Microsoft's ``VALL-EX'' that can reproduce human voices from only 3 seconds of voice in Japanese, English, and Chinese is on sale
'
GitHub - Plachtaa/VALL-EX: An open source implementation of Microsoft's VALL-E X zero-shot TTS model. Demo is available in https://plachtaa.github.io
https://github.com/Plachtaa/VALL-EX
You can see what kind of AI VALL-E is by reading the following article.
Microsoft announces speech synthesis AI ``VALL-E'' that can reproduce human voice from a sample of only 3 seconds - GIGAZINE

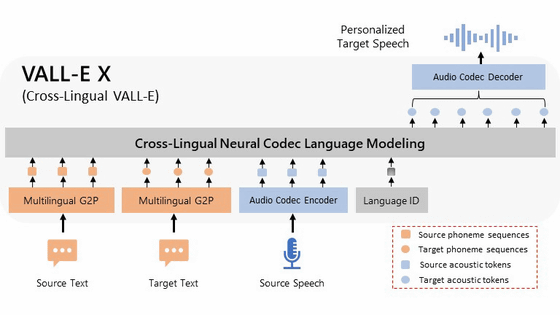
VALL-E X is an extension of VALL-E that uses both source language speech and target language text as prompts. For example, by inputting 'speech spoken in English' and 'sentences in Chinese,' it is possible to have the reproduced speech read out Chinese.
For VALL-EX, Microsoft has published a (PDF file) research paper and an overview of the model, but has not released the source code or pre-trained model. A team led by Songting Liu ( Plachta ), a student at Nanyang Technological University 's Faculty of Electrical and Electronic Engineering, has trained a unique model that reproduces this VALL-EX from scratch and has released the source code and model.
Microsoft's VALL-E X supported only English and Chinese, but Plachta's VALL-E X is also compatible with Japanese. You can experience Mr. Plachta's VALL-EX demo on Hugging Face below.
VALL EX - a Hugging Face Space by Plachta
https://huggingface.co/spaces/Plachta/VALL-EX
When you access the demo page of Hugging Face, it looks like this.
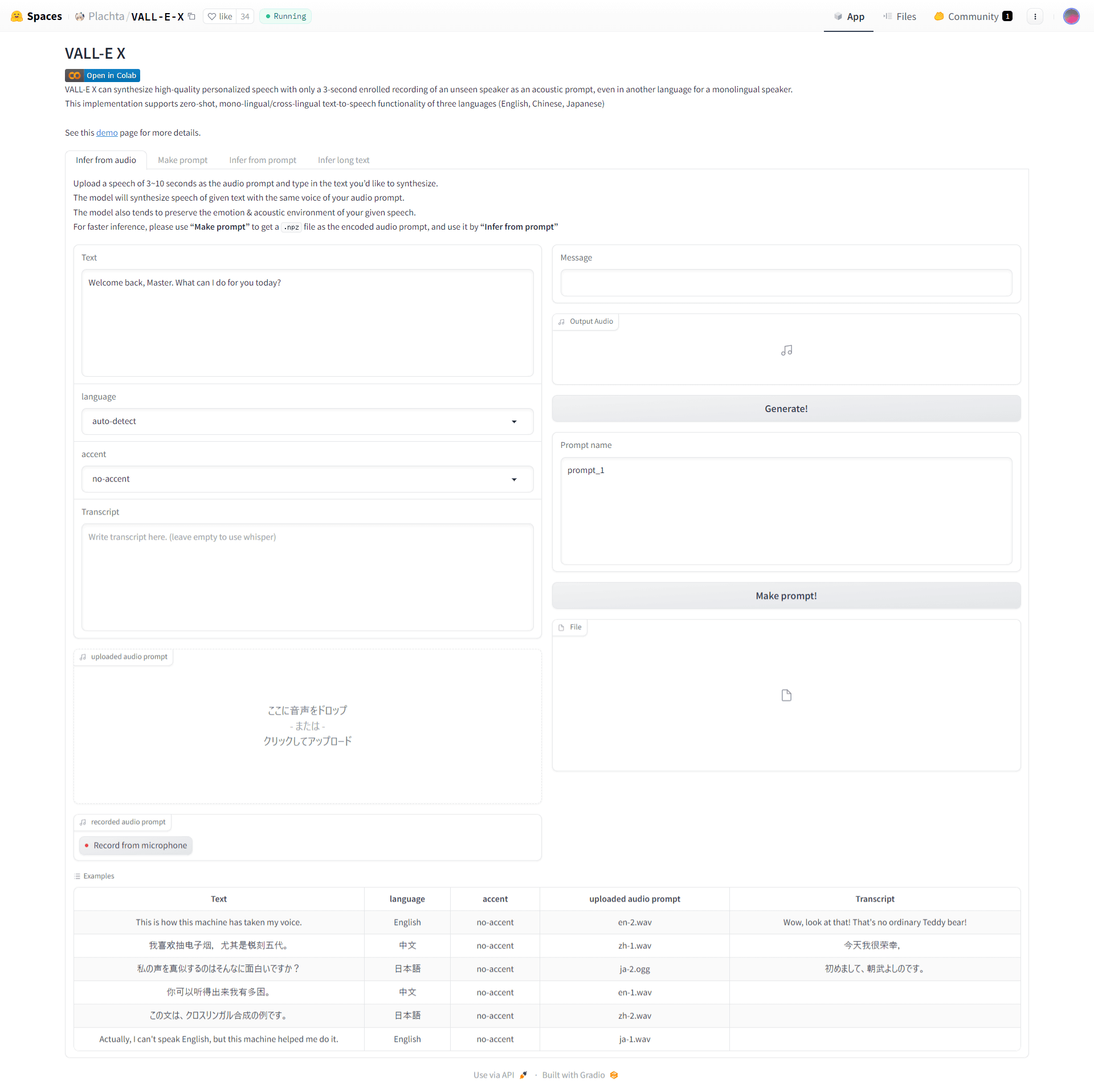
This time, read the news in English Let's read the following audio file and generate a greeting voice in Japanese.
Load the text you want to read to 'Text', the language of Text to 'language', the original voice to 'uploaded audio plompt', and click 'Generate!'
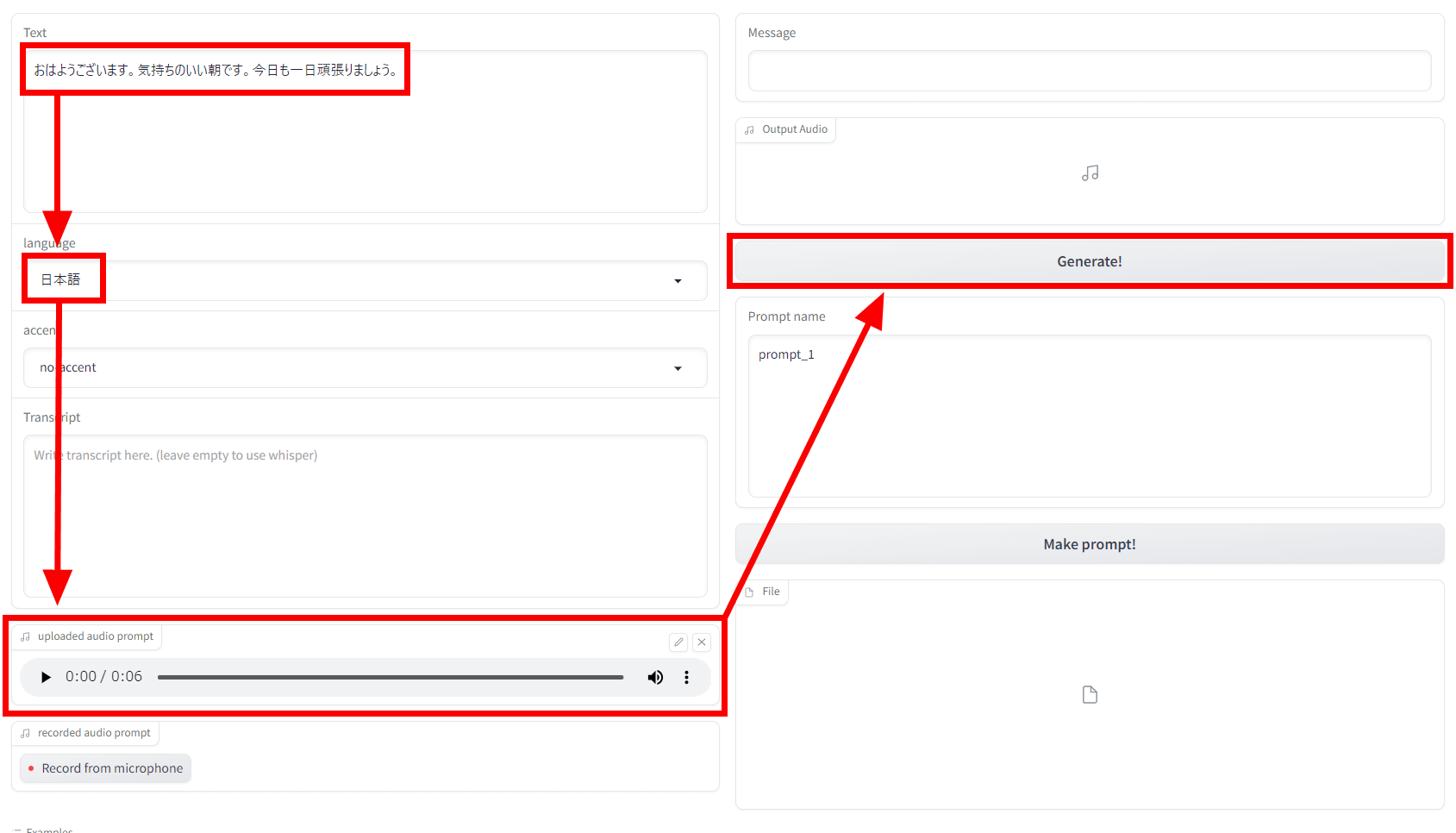
After waiting for about 3 minutes, the generated content and the generated sound were displayed in the upper right.
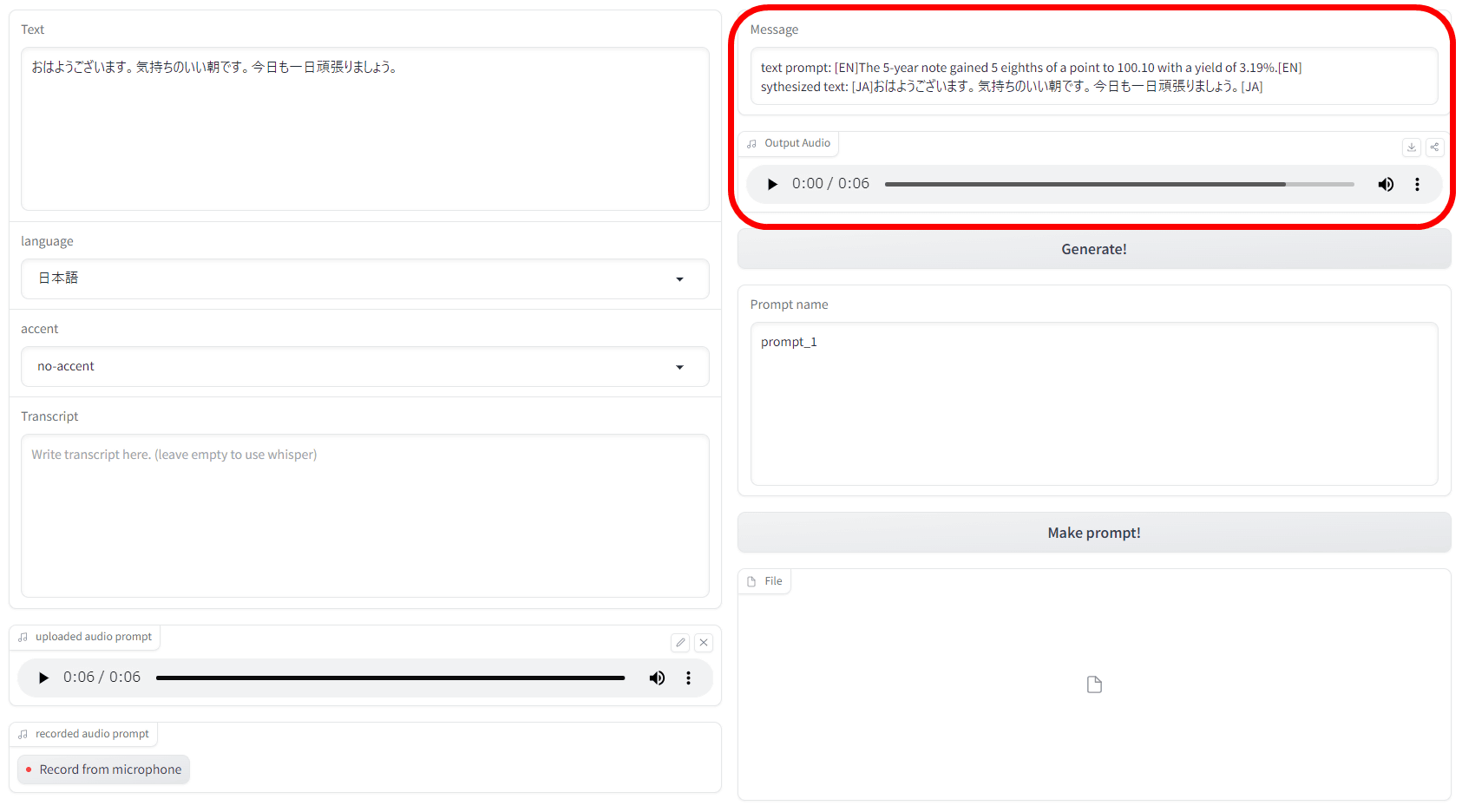
The sound actually generated is like this. Since the original voice is only a few seconds short, although there is a slight distortion, the tone is close to the original voice.
An example of the voice generated by Mr. Plachta's VALL-EX is also available on the demo page below.
VALL-E
https://plachtaa.github.io/
Related Posts:







in Software, Web Service, Review, Posted by log1i_yk