AI will be developed that analyzes the `` emotion '' contained in the voice and automatically generates the speaker's face with animation

by pxhere
The voice of the person who speaks shows the identity of the speaker, such as gender, age, and ethnicity. With the advance of artificial intelligence (AI) technology, AI that predicts the face of a person speaking from a human voice and generates an image has also
Animating Face using Disentangled Audio Representations
https://arxiv.org/pdf/1910.00726.pdf
Microsoft's AI generates high-quality talking heads from audio | VentureBeat
https://venturebeat.com/2019/10/07/microsofts-ai-generates-high-quality-talking-heads-from-audio/
Until now, many of the data sets used in research to analyze conversational voices with AI have been “conversational voices that are very easy to hear and speak quietly”. However, the situation where humans actually talk is a lot of noise in the surroundings, and the voice of the speaker and various habits ride on the voice.

by pixabay
“As we all know, conversational speech is so diverse. If different people speak the same word in different contexts, the speed, pitch, and tone will change. In addition, conversational voices contain aspirational information about the speaker's emotional state, gender, age, ethnicity, and personality, '' using a variational auto-encoder (VAE). Analyzed.
The research data set includes over 1000 recordings provided by 34 speakers, 7442 videos spoken by 91 ethnically diverse people, and more than 100,000 voices obtained from speech movies. Used to learn VAE.
VAE analyzes the input speech waveform and analyzes the content of the speech, the emotions of the speaker, and various other factors.
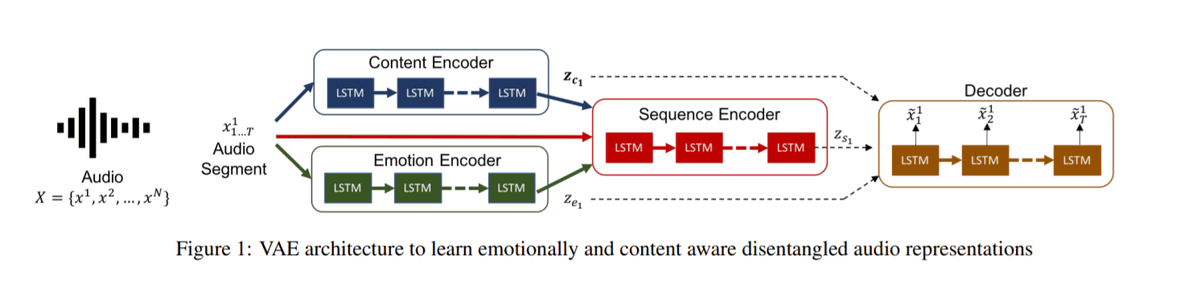
Then, the input face image and analysis results are sent to the video generator to create an animation.

The research team said, “Our research is the first approach to improve AI performance from the perspective of speech expression learning.” “We tested this model by testing with noisy and emotional conversational speech, The approach has shown that it is more accurate than state-of-the-art technology. '
Related Posts:




in Software, Posted by log1i_yk