NVIDIA is developing an AI that can speak expressively like a real human being
NVIDIA Shares Speech Synthesis Research at Interspeech | NVIDIA Blog
https://blogs.nvidia.com/blog/2021/08/31/conversational-ai-research-speech-synthesis-interspeech/
Synthetic voice has evolved from mechanical voice in automatic guidance service voices and guidance in old car navigation systems to something quite human and sophisticated in virtual assistants installed in smartphones and smart speakers.
Still, there is still a big difference between real human conversation voice and synthetic voice, and it is easy to tell whether it is a real human voice or an AI synthetic voice. According to NVIDIA, it is difficult for AI to completely imitate the complex rhythms and intonations contained in the human voice.
Humans have traditionally been the narrators in the footage of NVIDIA introducing new products and technologies. This is because conventional speech synthesis models have limited control over the tempo and pitch of the speech that can be synthesized, making it impossible to speak in a way that stimulates the viewer's emotions like a human narrator.

However, since NVIDIA's speech synthesis research team developed the text-to-speech synthesis technology '(PDF file)
You can see what the voice synthesis by 'NVIDIA NeMo' actually looks like by watching the following movie.
All the Feels: NVIDIA Shares Expressive Speech Synthesis Research at Interspeech --YouTube
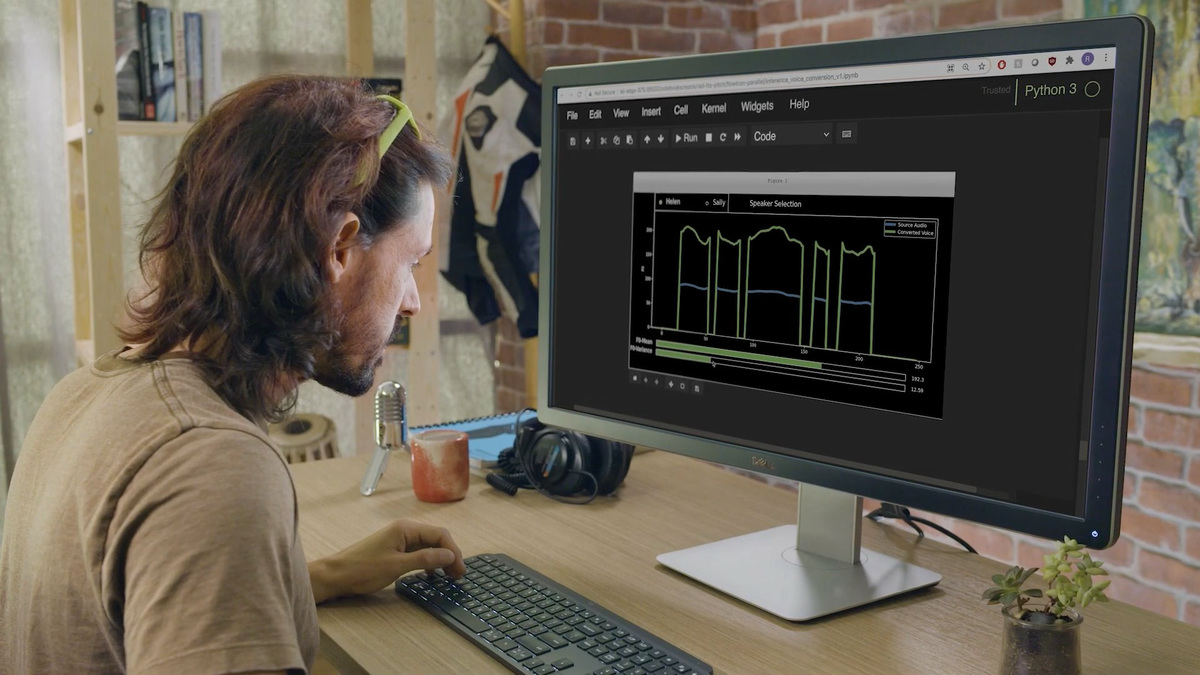
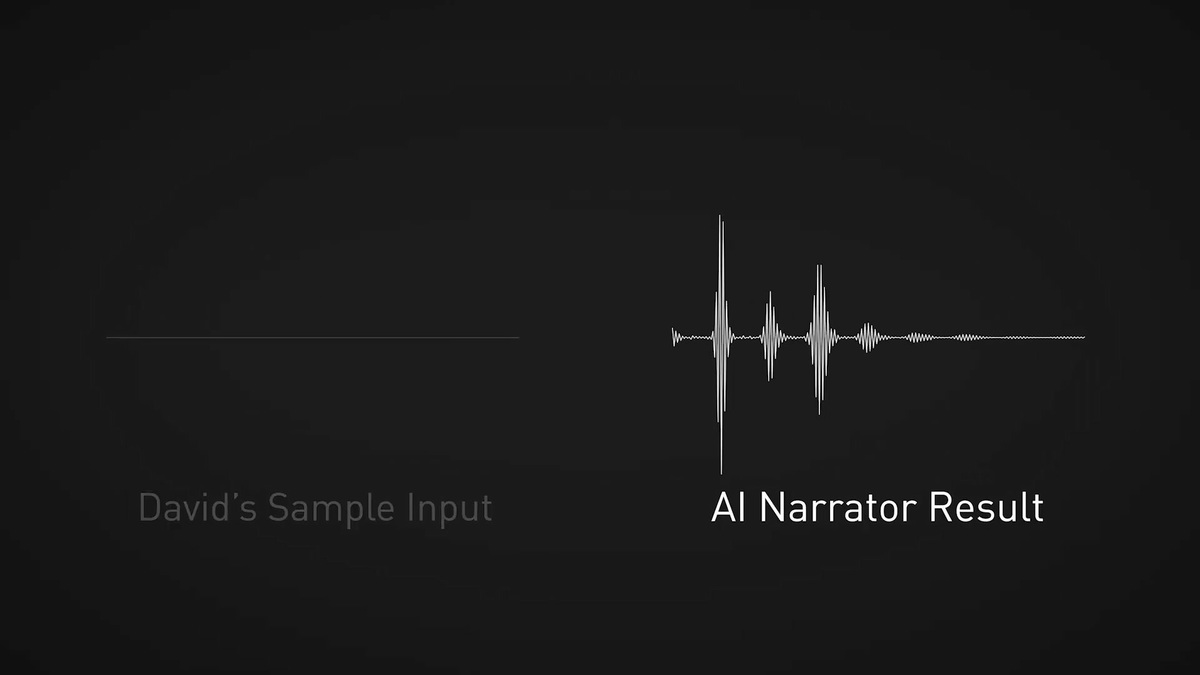
NVIDIA-affiliated video creator David Weissman reads the lines into the microphone.

Engineers use AI models to convert voice.
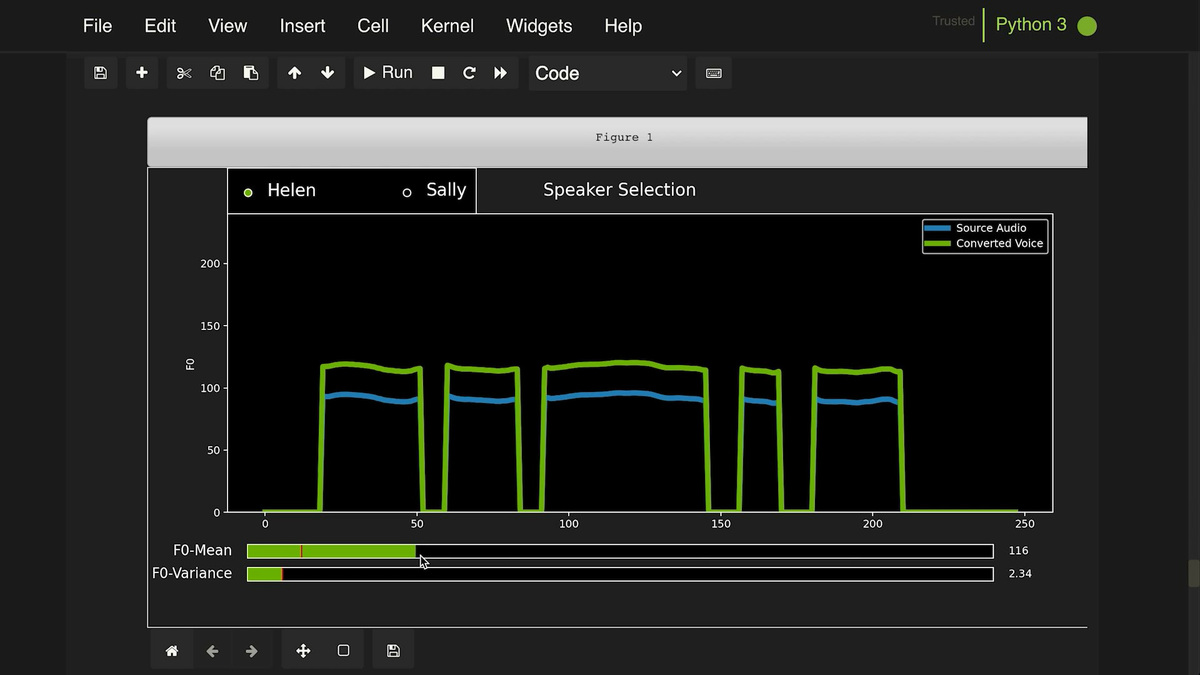
Weissman's narration has been translated into the voice of a female narrator. Normally, the machine voice has a peculiar intonation and often feels strange, but the voice converted to this female narrator does not feel strange at all and is reproduced very smoothly. It is also possible to adjust the voice synthesized on the AI side to emphasize a specific word, or change the speed of narration to match it with the video. It seems that the voice synthesized or converted by this NVIDIA NeMo is basically used for the narration of the movie released recently by NVIDIA.
Speech synthesis is useful not only for narration but also for music production. For example, when creating a song, the chorus part must record and superimpose the singing voices of multiple people. However, by using synthetic speech, it is possible to record chorus parts without collecting multiple people.

The AI models included in NVIDIA NeMo have been trained on NVIDIA DGX systems with tens of thousands of hours of audio data and run on the Tensor core of NVIDIA GPUs. In addition, NVIDIA NeMo also provides a model learned with Mozilla Common Voice, which is a dataset containing about 14,000 hours of voice data in 76 languages. 'With the world's largest open voice dataset, we aim to democratize voice technology,' commented NVIDIA.
The source of NVIDIA NeMo is available on GitHub.
GitHub --NVIDIA / NeMo: NeMo: a toolkit for conversational AI
https://github.com/NVIDIA/NeMo/tree/main/docs
Related Posts: