Google announces AI 'VLOGGER' that generates 'realistic video talking with gestures' from just one photo and voice

Google's research team has announced `` VLOGGER ,'' an AI framework that can generate ``realistic videos of people speaking with gestures in time with the audio'' by inputting a single photo and audio.
VLOGGER
Google researchers unveil 'VLOGGER', an AI that can bring still photos to life | VentureBeat
https://venturebeat.com/ai/google-researchers-unveil-vlogger-an-ai-that-can-bring-still-photos-to-life/
Google researchers unite to create Vlogger | Cybernews
https://cybernews.com/tech/google-researchers-create-vlogger/
A research team led by Enric Corona, who researches human 3D and generative AI at Google Research, developed VLOGGER by utilizing a type of machine learning model called a diffusion model .
What you need to generate a video with VLOGGER is the base image data and audio data to match it. In the first network, 'body motion controls' consisting of the person's line of sight, facial expression, and pose are created based on the waveform data obtained from the audio data. The next network extends a large-scale image diffusion model to generate frames corresponding to body motion control from input images.
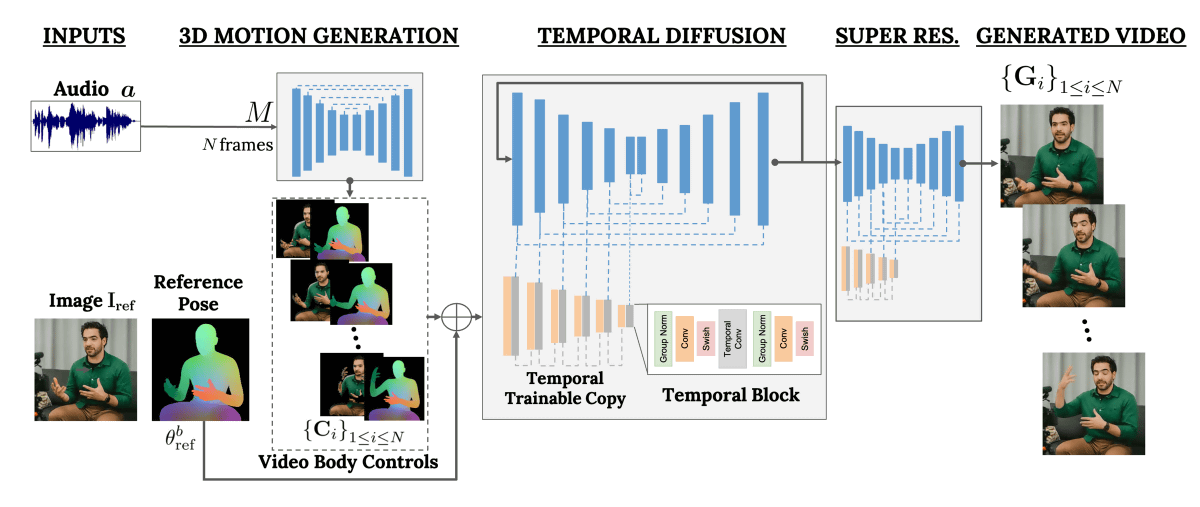
The key to the development of VLOGGER was a dataset called MENTOR, which contains over 800,000 diverse identities and a total of over 2,200 hours of video. By training with this highly accurate and huge data set, VLOGGER is now able to generate videos of various ethnicities, ages, clothing, poses, and surrounding environments without mixing bias.
The person's mouth, facial expressions, hands, etc. move in accordance with the flowing audio data.

Below is an example of VLOGGER video generation shown by the research team.
The videos that can be generated are short and have some awkward parts if you look closely. However, the research team says, ``Evaluation of VLOGGER on three different benchmarks shows that the proposed model outperforms other state-of-the-art methods in image quality, identity preservation, and temporal consistency.'' He insisted.
The research team also stated, ``In contrast to previous studies, our method does not require training for each individual, does not rely on face detection or cropping, and generates complete images that include more than just the face and lips. 'We take into account a wide range of scenarios (visible torsos and diverse subject identities) that are important for correctly synthesizing communicating humans.'
Technology media VentureBeat describes VLOGGER as, ``Actors can obtain detailed 3D models of themselves for new performances,'' ``It can be used to create photorealistic avatars for VR and games,'' and ``It's attractive and expressive.'' He claims that it has the potential to be used to create virtual assistants. On the other hand, he points out that there is a risk of it being misused for things like deepfakes, saying, ``As AI-generated videos like this become more realistic and easier to create, the challenges surrounding fake news and fabrication of digital content will increase.'' It could get worse,” he warned.
Related Posts:







