Introducing the AI system 'EMO' that can make photos and illustrations sing and talk in a realistic way

A team at Chinese technology company Alibaba's Intelligent Computing Research Institute has developed an AI system, Emote Portrait Alive (EMO )” was announced.
EMO
Alibaba's new AI system 'EMO' creates realistic talking and singing videos from photos | VentureBeat
https://venturebeat.com/ai/alibabas-new-ai-system-emo-creates-realistic-talking-and-singing-videos-from-photos/
EMO, announced by Alibaba researchers on the preprint server arXiv, can generate smooth and expressive facial expressions and head movements to match the input audio track.
By playing the movie below, you can actually see the video generated by EMO.
EMO-Emote Portrait Alive - YouTube
At the beginning of the movie, a black and white photo of Audrey Hepburn sings a song.

It is also possible to have the user talk like an interview video.

EMO uses an AI technology called
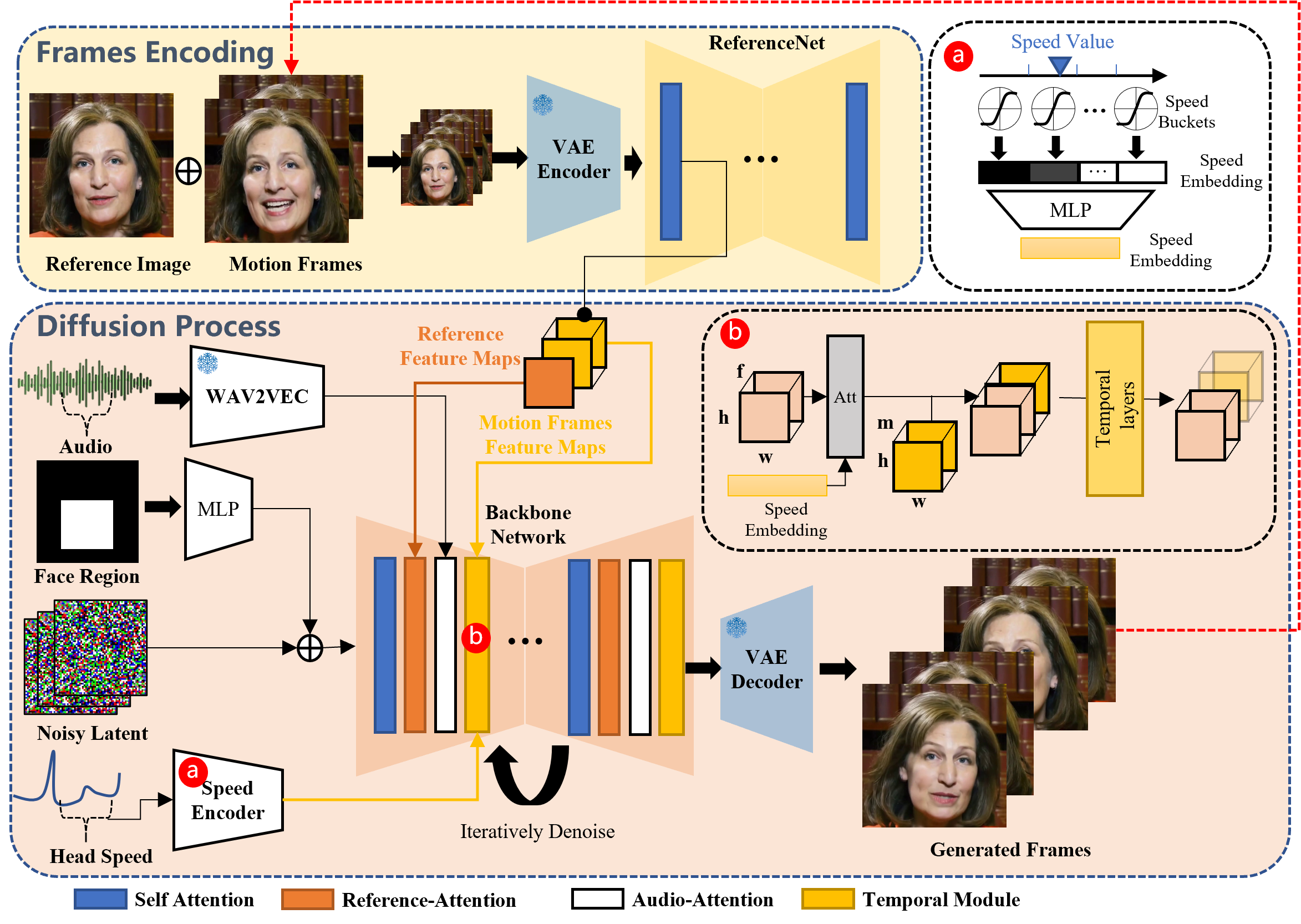
The developed EMO generates images directly from input audio, unlike traditional methods that rely on 3D facial models and contour synthesis to mimic facial movements. This makes it possible to output natural-looking images by capturing the subtle movements and unique habits associated with singing and speaking.

All you need to output a singing video is one image and audio.

There is no problem with songs where the mouth moves violently, such as rap.

It is also possible to generate speaking videos.

According to the paper, EMO significantly outperformed previous state-of-the-art methods on metrics that measure video quality, identity preservation, and expressiveness.

In their paper, the research team says, ``Conventional techniques often cannot capture the full range of human expressions, and they also have limitations in that they cannot capture the uniqueness of individual facial styles.'' To address the problem, we propose EMO, a novel framework that bypasses the need for intermediate 3D models and facial landmark specifications and utilizes a direct audio-to-video synthesis approach.'

Using this technology, you can easily create realistic videos just by preparing images and audio. Therefore, if a deepfake video is created that uses the face or voice of a real person without their consent, there is a concern that it could develop into a serious problem, even if it is just a monochrome photo or illustration.

In order to address the issue of this technology being misused for the spread of false information and spoofing, researchers plan to consider ways to detect synthetic videos.
Related Posts:







