Microsoft releases 'VASA-1,' an AI model that can create realistic speaking videos from face photos and audio files

Microsoft Research, a research institute of Microsoft, has announced ' VASA-1 ', an AI model that can generate a 'realistic talking face' from a single face photo and audio file. VASA-1 can
VASA-1 - Microsoft Research
https://www.microsoft.com/en-us/research/project/vasa-1/
Cool or creepy? Microsoft's VASA-1 is a new AI model that turns photos into 'talking faces' | Tom's Guide
https://www.tomsguide.com/ai/ai-image-video/microsoft-wants-your-photos-to-talk-vasa-1-is-a-new-ai-model-to-turn-images-into-talking-faces
VASA-1 is an AI model that can generate a realistic video in which the face photo reads the contents of the audio file by simply importing a single face photo and audio file. At the time of writing, VASA-1 is a research preview version, so only the Microsoft Research research team can try out the model. However, Microsoft Research has released a demonstration video of VASA-1, and you can see what kind of AI model it is just by watching this.
A demonstration video of Microsoft's AI model 'VASA-1' that can create realistic talking face images from face photos and audio files - YouTube
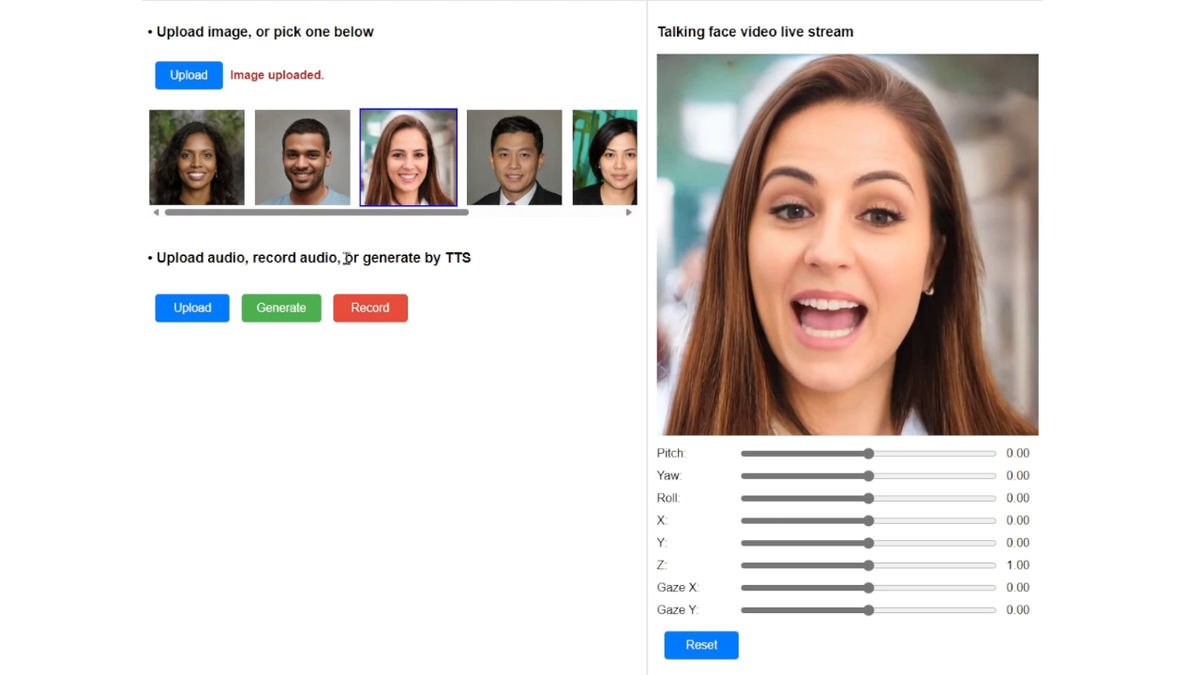
First, select the face photo you want to use.
Next, select the audio file you want to have read over the photo of your face.
Then, the photo of the face started speaking naturally. The movement of the mouth was very natural.
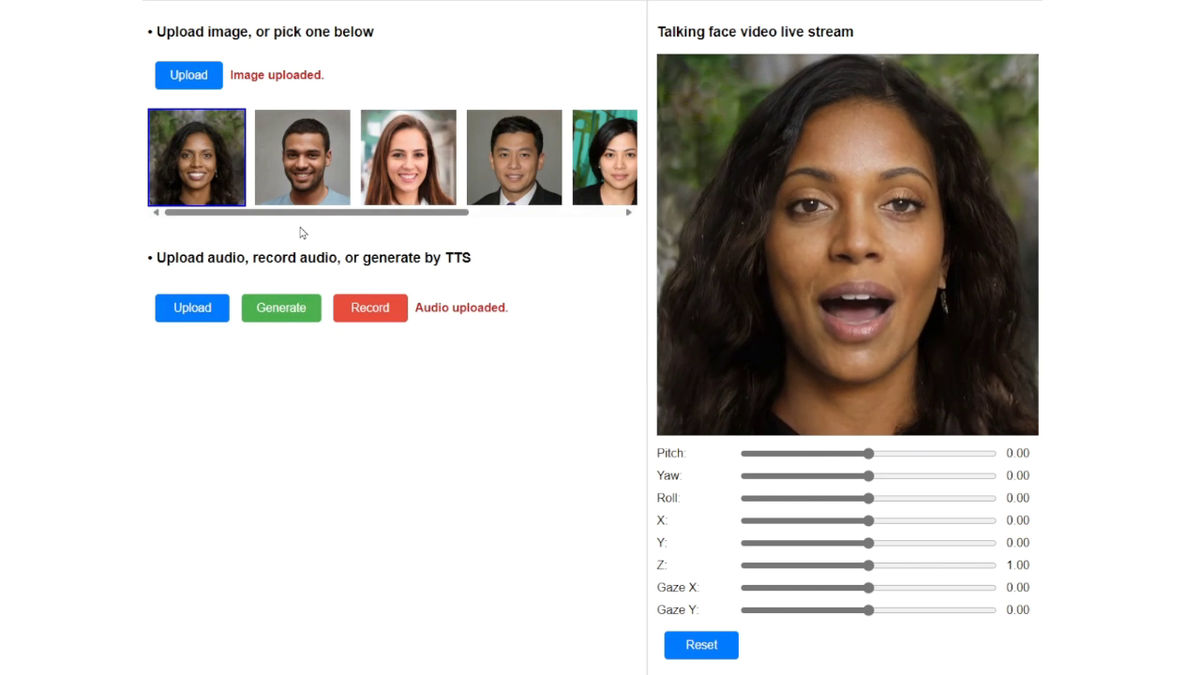
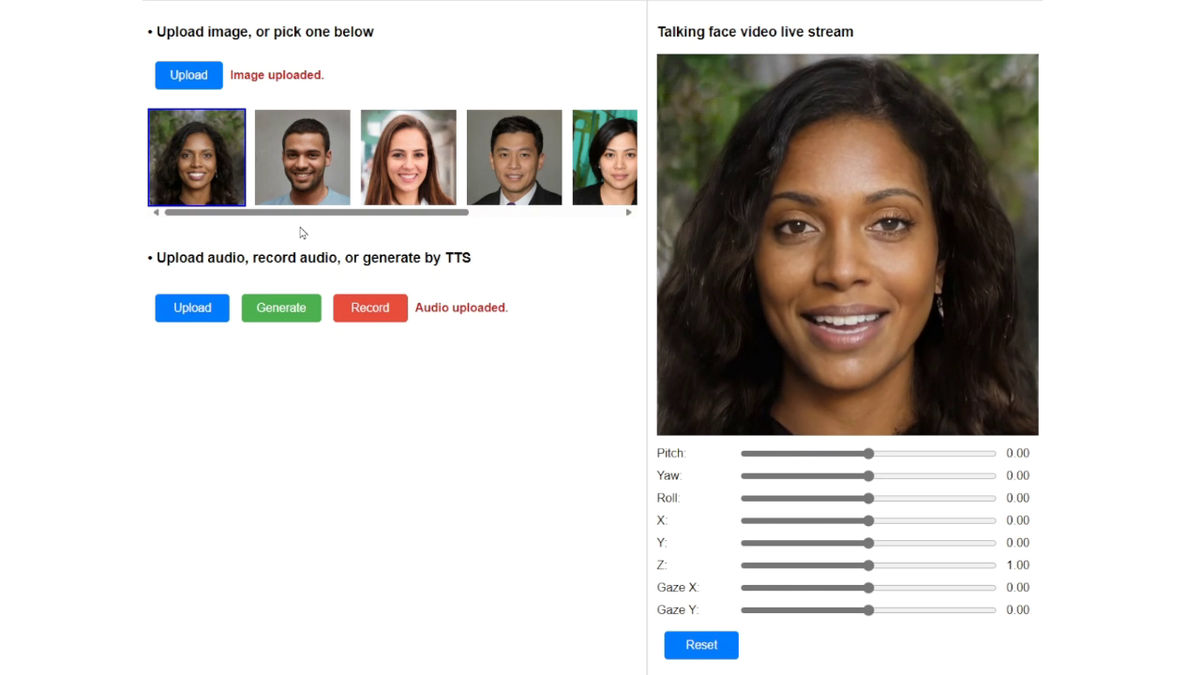
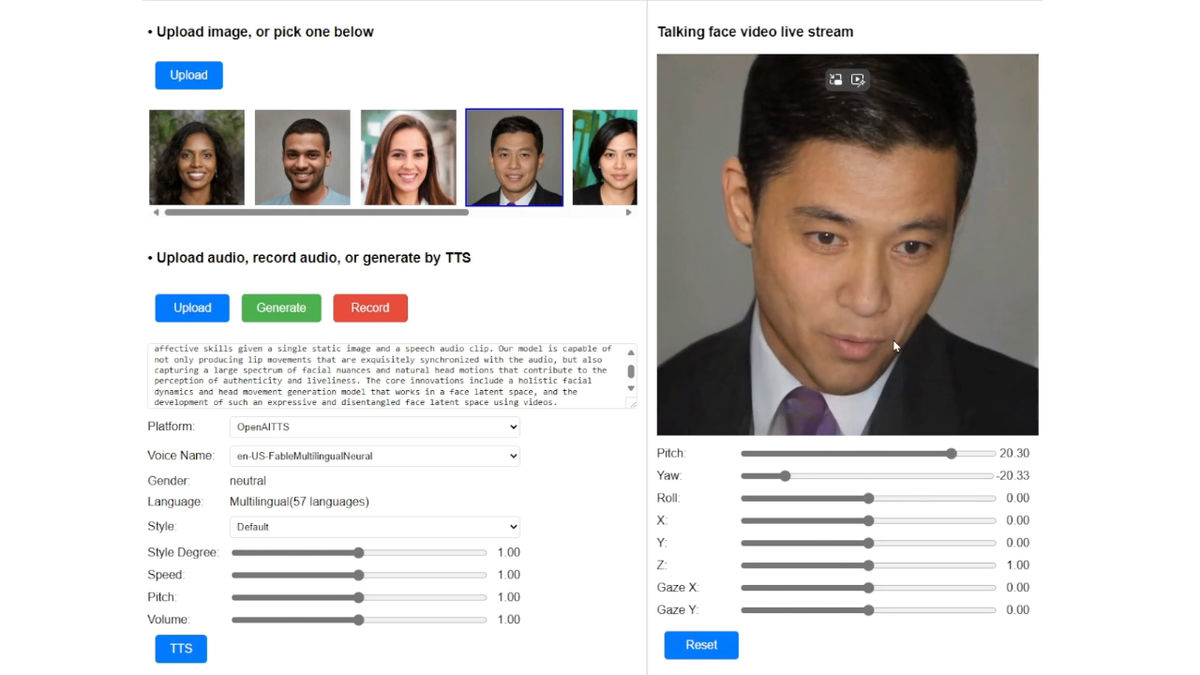
When speaking, the person has a lot of facial expressions, not only moving their mouth but also blinking and making small movements of their head from side to side.
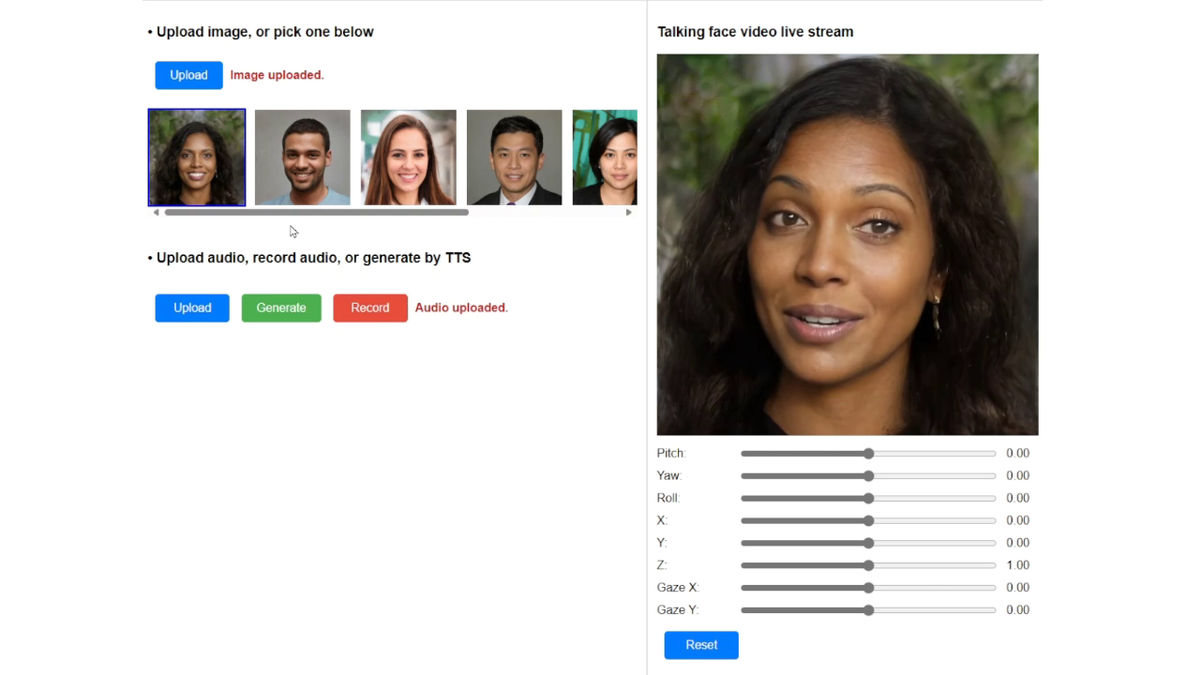
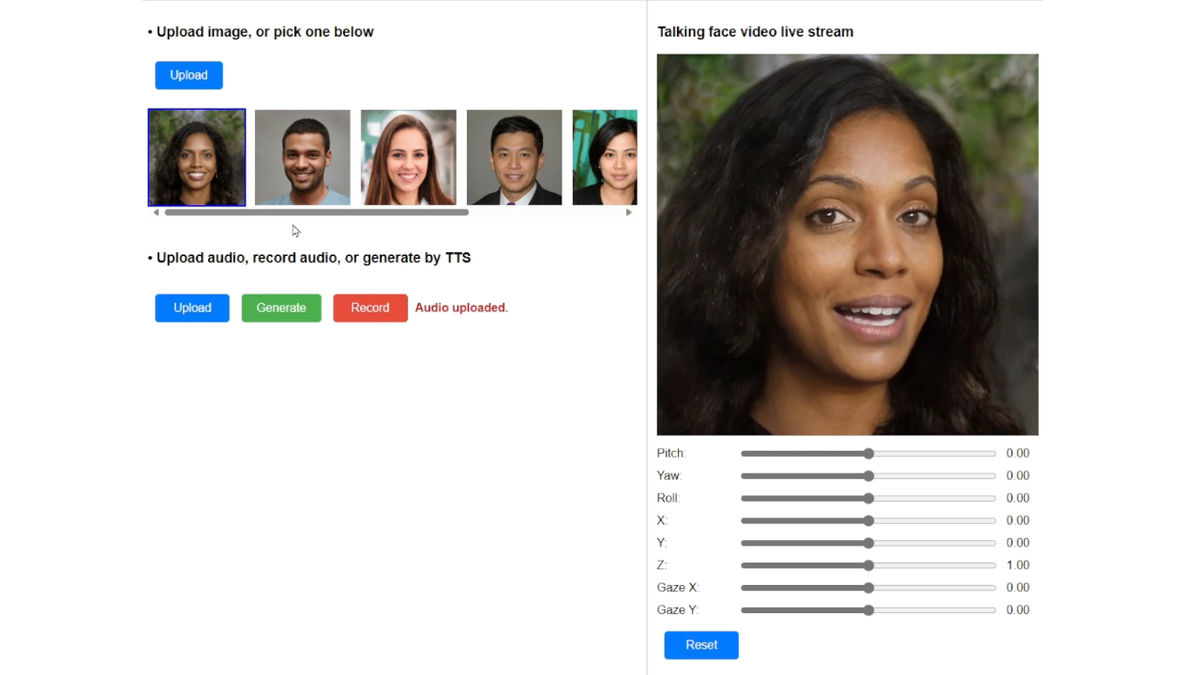
Realistic talking faces can be generated regardless of gender or race.
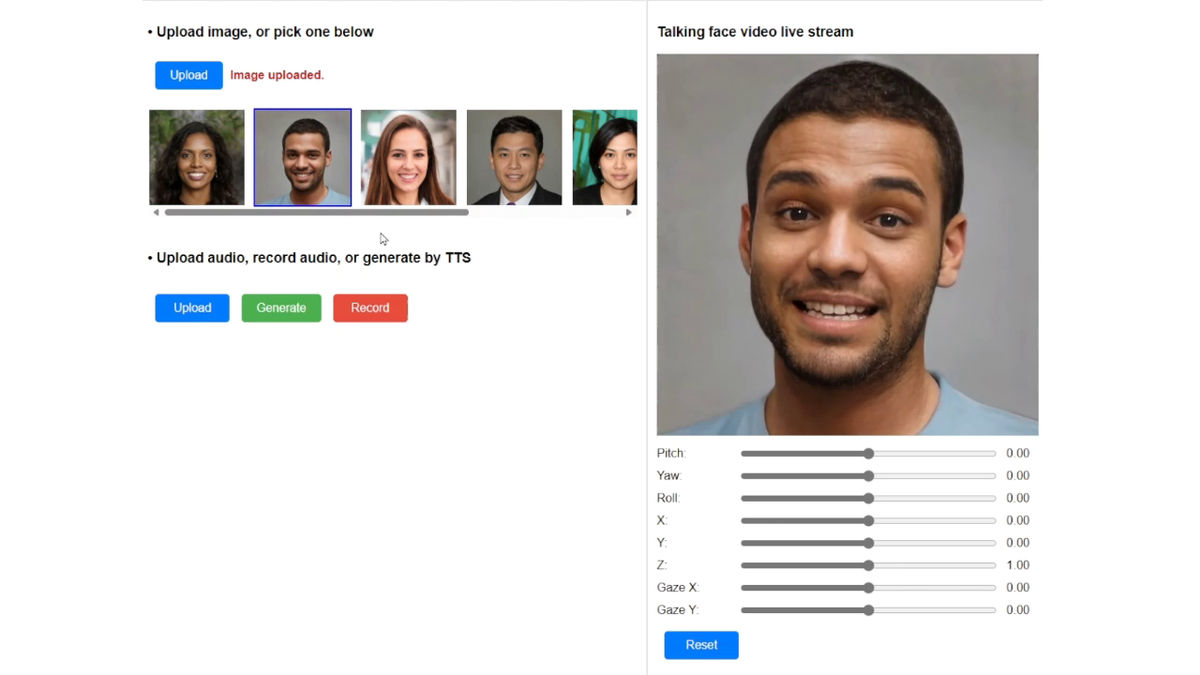
In addition, even though the video is generated from just one photo of your face, there is no sense of incongruity even when you change the direction of your face.
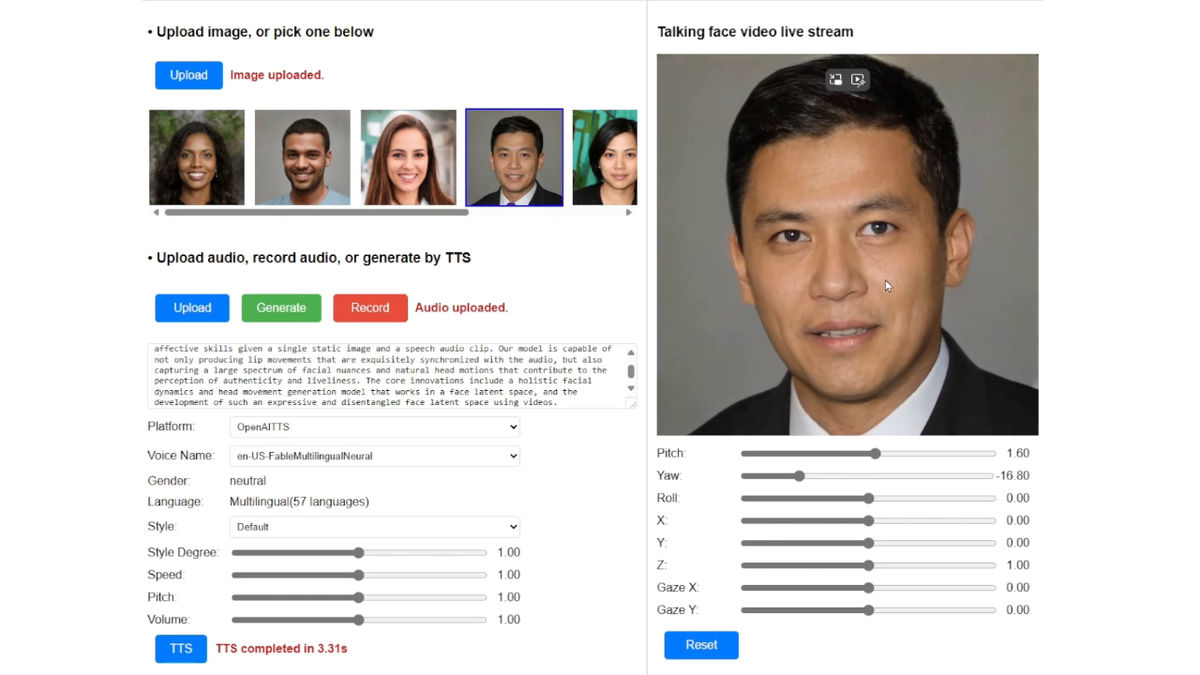
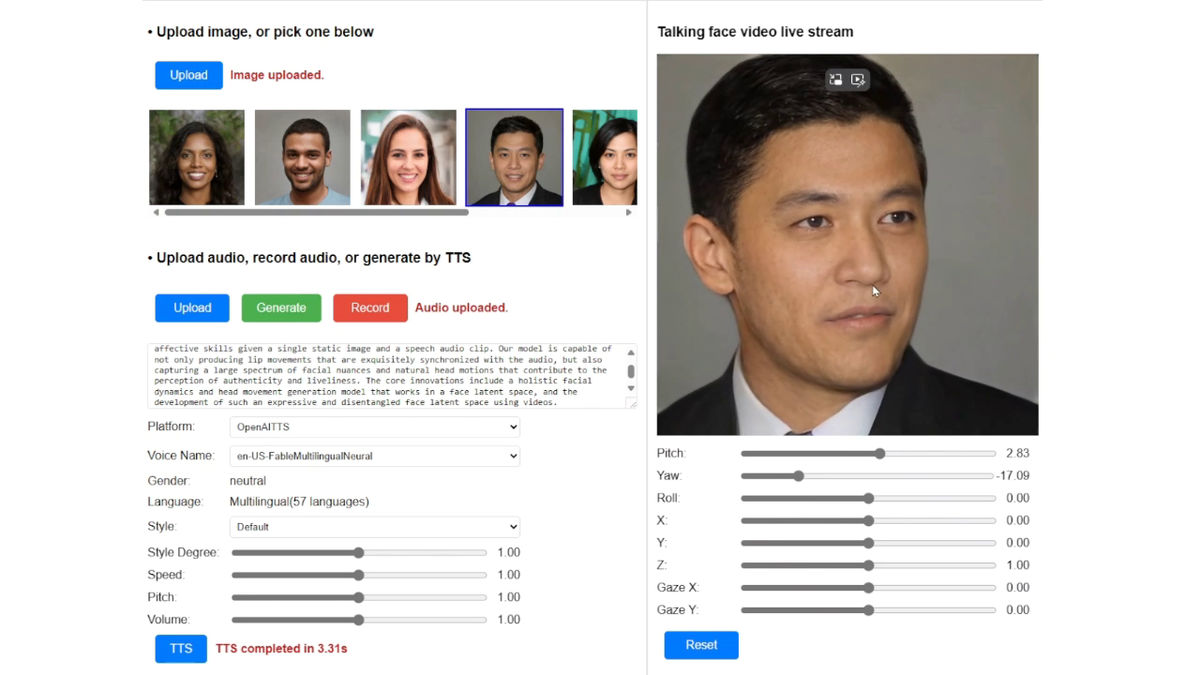
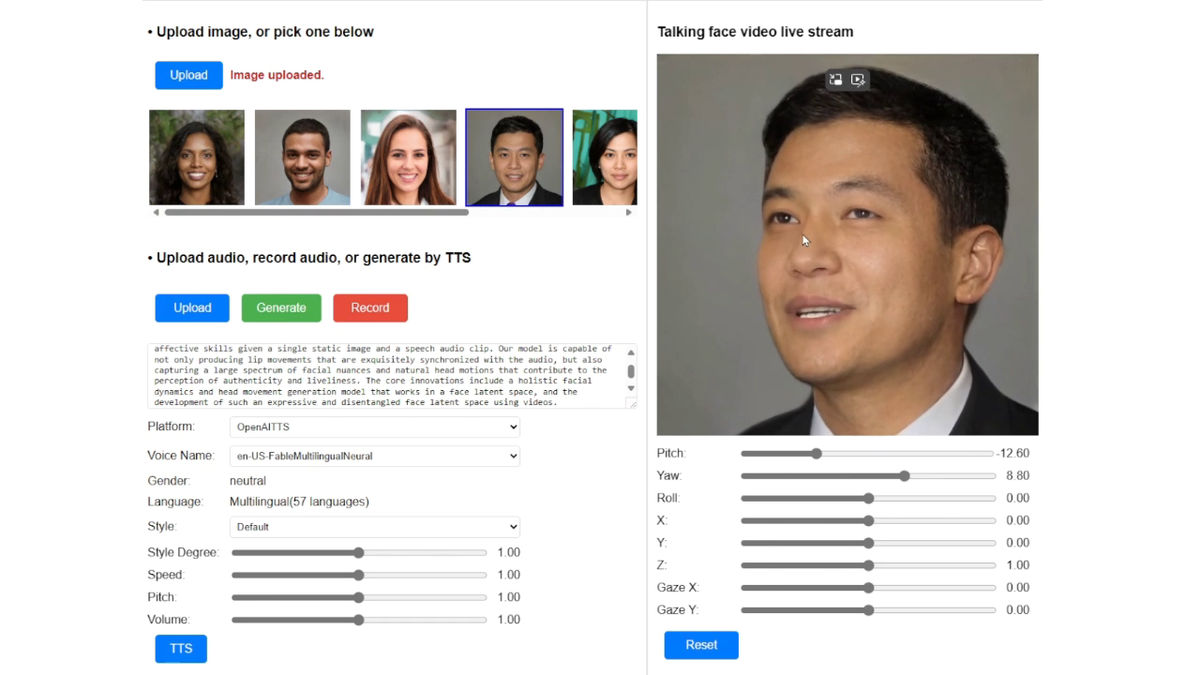
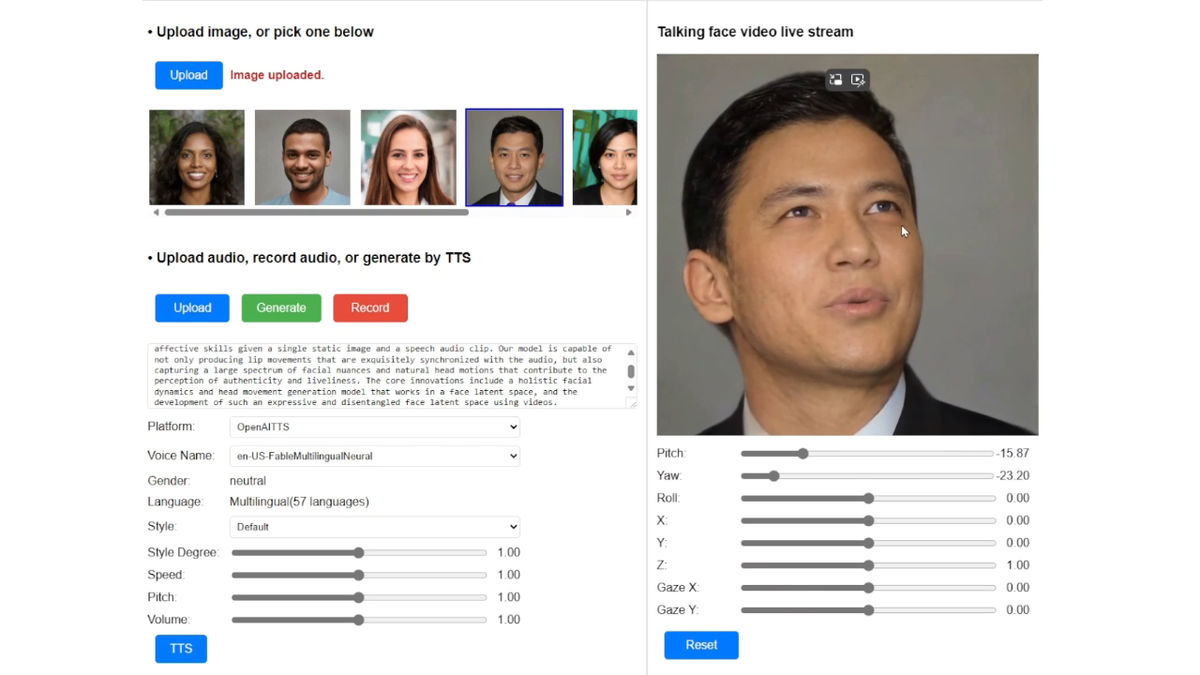
In addition, by using a desktop PC equipped with NVIDIA's RTX 4090, it is possible to generate a 'talking face video' with a frame rate of 45 fps and a resolution of 512 x 512 pixels in about 2 minutes.
AI models that generate realistic talking faces have already been released by Runway and NVIDIA, but VASA-1 is far more accurate in terms of quality and realism, with 'reduced artifacts around the mouth,' according to technology media Tom's Guide.
According to Microsoft, VASA-1 was created with the aim of animating virtual characters, and all of the sample facial images were 'fictional facial images' created using OpenAI's DALL-E image generation AI.
Tom's Guide states that 'VASA-1 is capable of advanced lip syncing, so if you can create AI-driven NPCs by accurately synchronizing the character's lip movements with their voice, it could bring about a major revolution in the immersiveness of games,' and mentions the possibility that VASA-1's advanced lip syncing could be useful for game development.
However, Microsoft Research states that VASA-1 is merely a research demonstration and has no plans to release it to the public or commercialize it for developers.
The research team explained that they were surprised that VASA-1 managed to perfectly lip-sync songs, even though the training dataset did not contain any music.
Related Posts:







