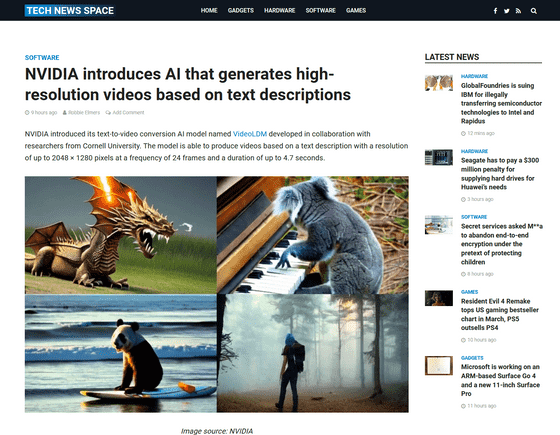
NVIDIA announces AI model 'VideoLDM' that generates high-resolution video from text

NVIDIA announced the AI model ' Video Latent Diffusion Model (VideoLDM)' jointly developed with Cornell University in the United States. VideoLDM can generate up to 2048 x 1280 pixel resolution, 24fps video up to 4.7 seconds based on a textual description.
Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
NVIDIA Introduces AI That Generates High-resolution Videos Based On Text Descriptions - Tech News Space
VideoLDM announced by NVIDIA has a maximum of 4.1 billion parameters, of which 2.7 billion are videos used for training. This is a fairly modest level by the standards of AI development, but NVIDIA is able to create high-resolution, temporally consistent, and diverse videos thanks to its efficient Latent Diffusion Model (LDM). I have successfully developed the model.
Below is an example of a video generated by VideoLDM. Prompt 'A teddy bear is playing the electric guitar, high definition, 4k' to generate a high-definition teddy bear animation with a claymation-like feel. I was able to do.
VideoLDM has two major features. The first is the generation of personalized videos. VideoLDM can perform personalized “text-to-video synthesis” by adjusting a specific image with a method called “
For example, let's say you used a cat image like this:

After that, if you instruct to generate a video of a cat playing in the grass, a video with a cat that looks exactly like the original image will be generated as shown below.
The other is Convolutional-in-Time Synthesis. This makes it possible to create 174 frames at 24fps, or 7.3 seconds long, at the cost of slightly lower image quality.
Furthermore, if it is a driving video, it is also possible to generate a video with a resolution of 1024 × 512 pixels and a length of 5 minutes. When you play the following video, you can see that driving images of various situations such as driving in the city, suburbs, daytime and late night driving are generated.
Driving video generated by NVIDIA's video generation AI 'VideoLDM' - YouTube
VideoLDM is scheduled to be announced at the technical conference 'Machine Vision and Pattern Recognition Conference' to be held in Vancouver, Canada from June 18, 2023. Since it is still in the research project stage, it is unknown at the time of writing how this will be deployed to NVIDIA's services and products.
Related Posts:







