Google develops "technology to extract only a specific single voice from mixed sounds of multiple sounds" using deep learning
A phenomenon that many people can hear stories of their names and interests naturally even though many people are talking about like a party venue where many people gather.Cocktail party effectIt is called a representative example of human ability "selective attention". Google researchers have learned the technology to separate automatically mixed sounds on computers by using deep learning and succeeded in acquiring a cocktail party effect on a computer.
[1804.03619] Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation
https://arxiv.org/abs/1804.03619
Research Blog: Looking to Listen: Audio-Visual Speech Separation
https://research.googleblog.com/2018/04/looking-to-listen-audio-visual-speech.html
While it is possible for humans to process multiple sounds unconsciously and selectively listen to the sounds they want to listen to, it was considered a difficult task for computers. Google researchers used deep learning and cocktail party effects created an audiovisual model that separates a single audio signal from mixed sounds of other people's voices and background noise.
In the model that Google has built, by selecting the face of a person who wants to listen to only this person's voice from among a plurality of people in a movie having a single audio track, words that the person emits It is possible to suppress other sounds by emphasizing only. This function is thought to be useful in improving speech images, movie conferences, hearing aids, etc. in the presence of a large audience, and may be applied to a wide range of applications.
You can see how this technology named "Looking to Listen" is used for one movie by seeing the following movie.
Looking to Listen: Stand-up
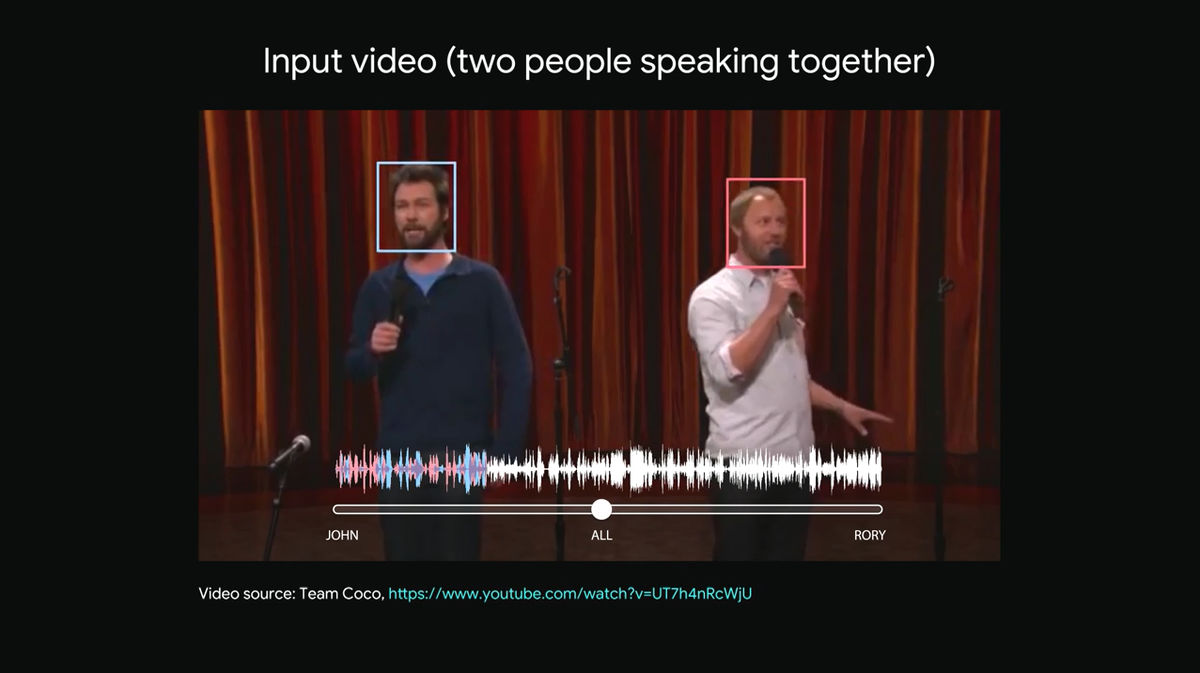
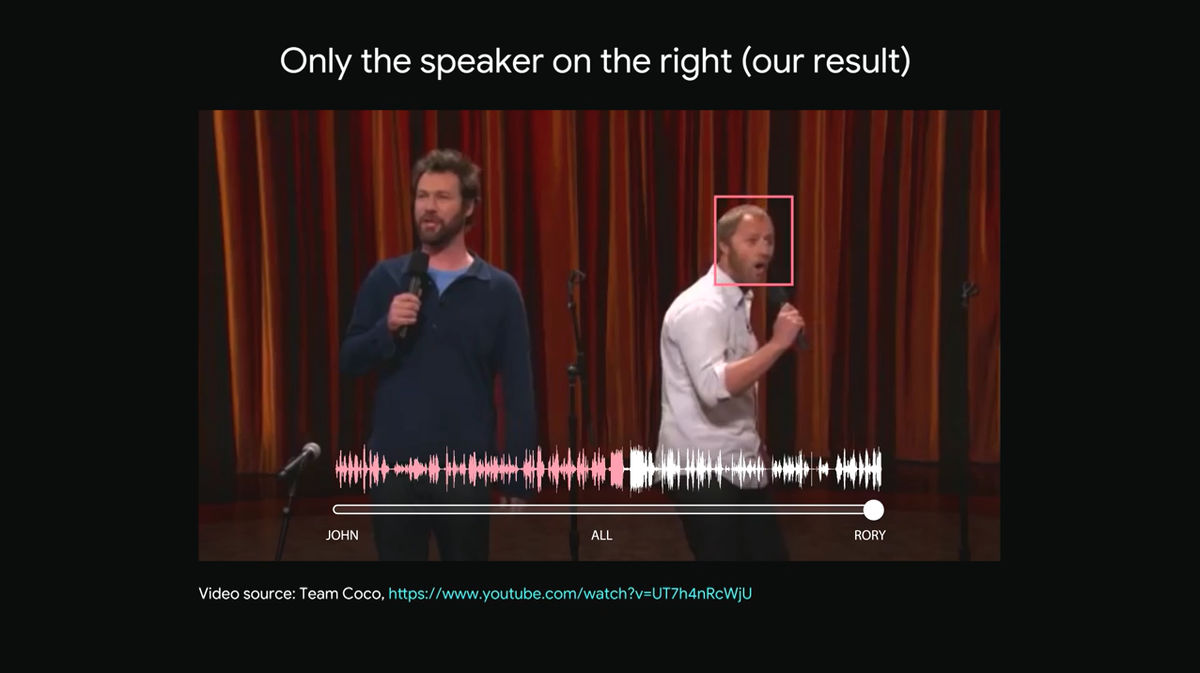
Although two people are talking on the stage, I speak completely different things to pieces and I do not know what they are talking about because the audience's laughter and noise are also anxious.

The face of the two men who are talking has a rectangular frame, the man standing on the left side is light blue, the man standing on the right side is pink. The waveform representing the bottom sound represents the voice each male speaks, the words (light blue wave) spoken by a light blue man and the word spoken by a pink man (pink color) are cluttered It is understood that it is mixed with.
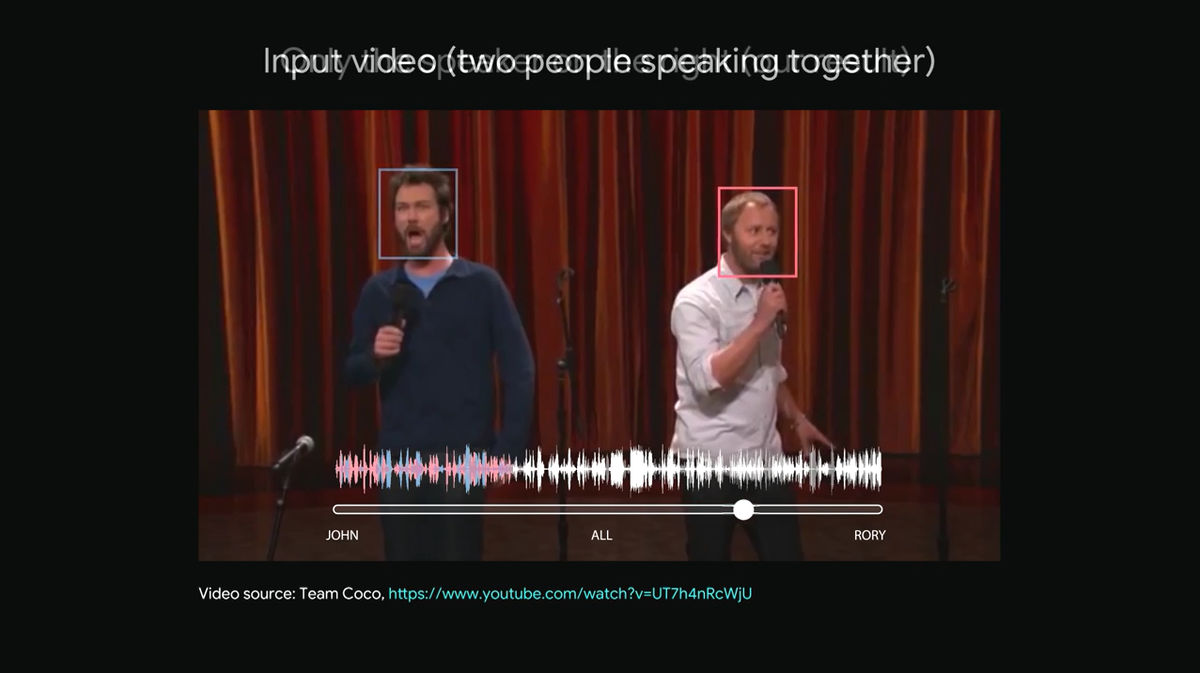
Here sliding the lower slider to the right ... ...
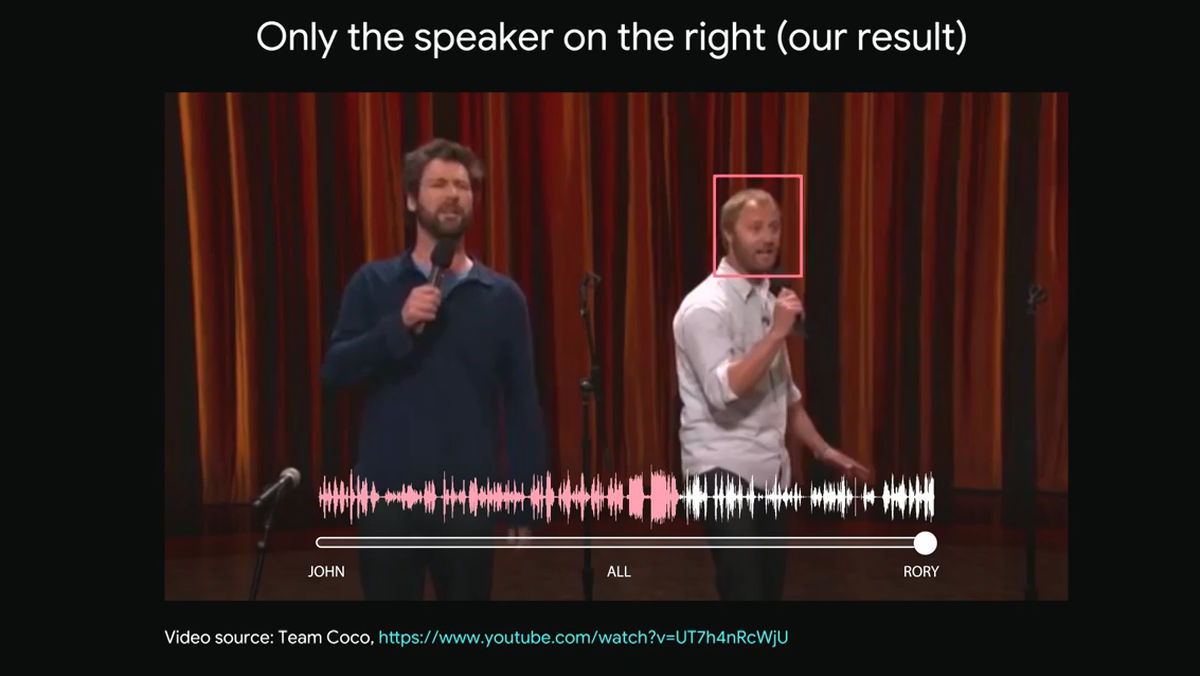
You will be able to hear only the male pink-colored waveforms standing on the right side.
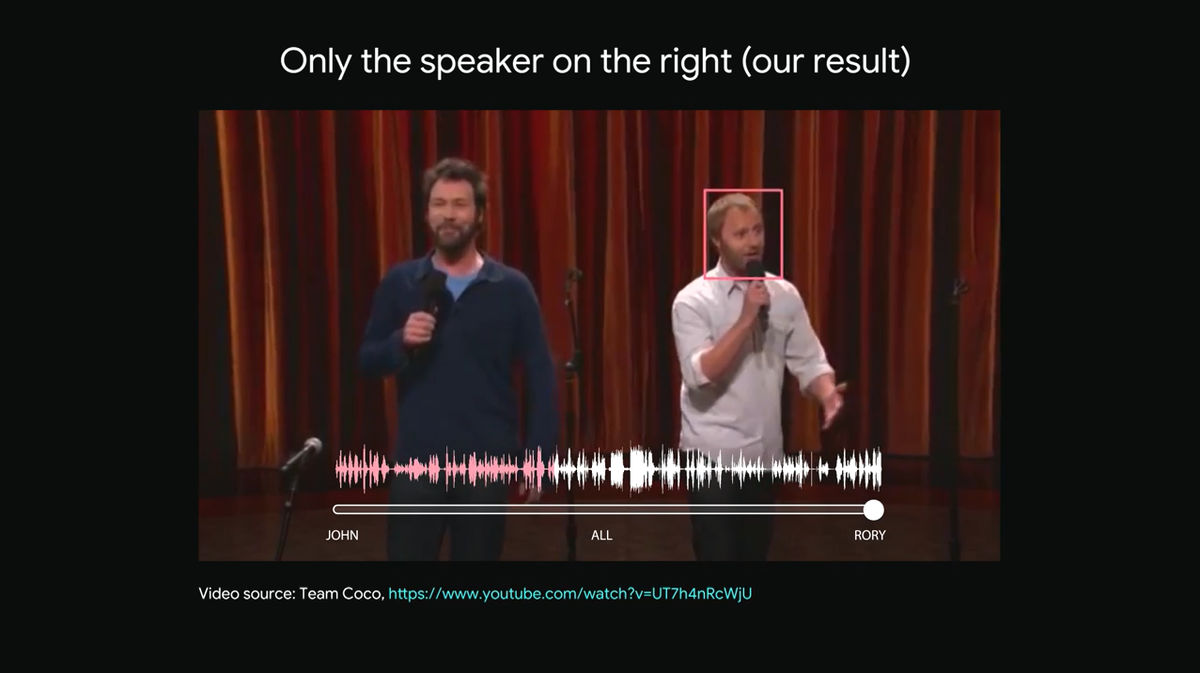
I can tell from the video that the man standing on the left also continues talking, but since the artificial intelligence selectively hears only the voice of the male on the right, he can not hear the voice of the man on the left side.
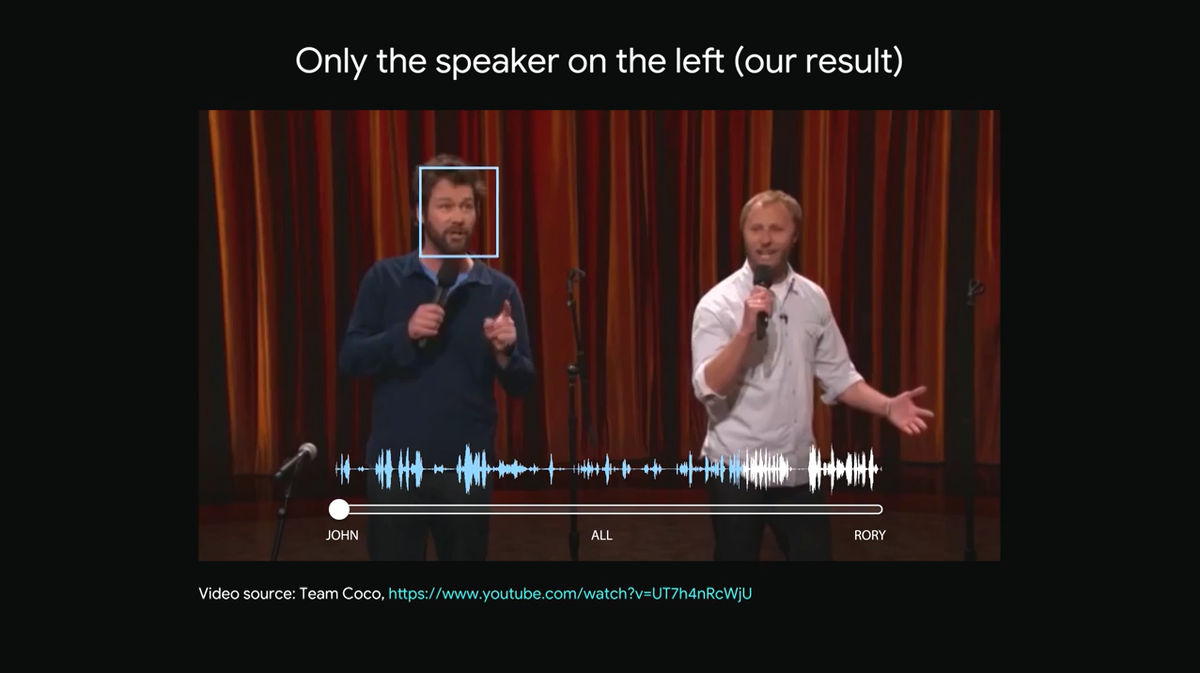
Next time I will slide the slider to the left.
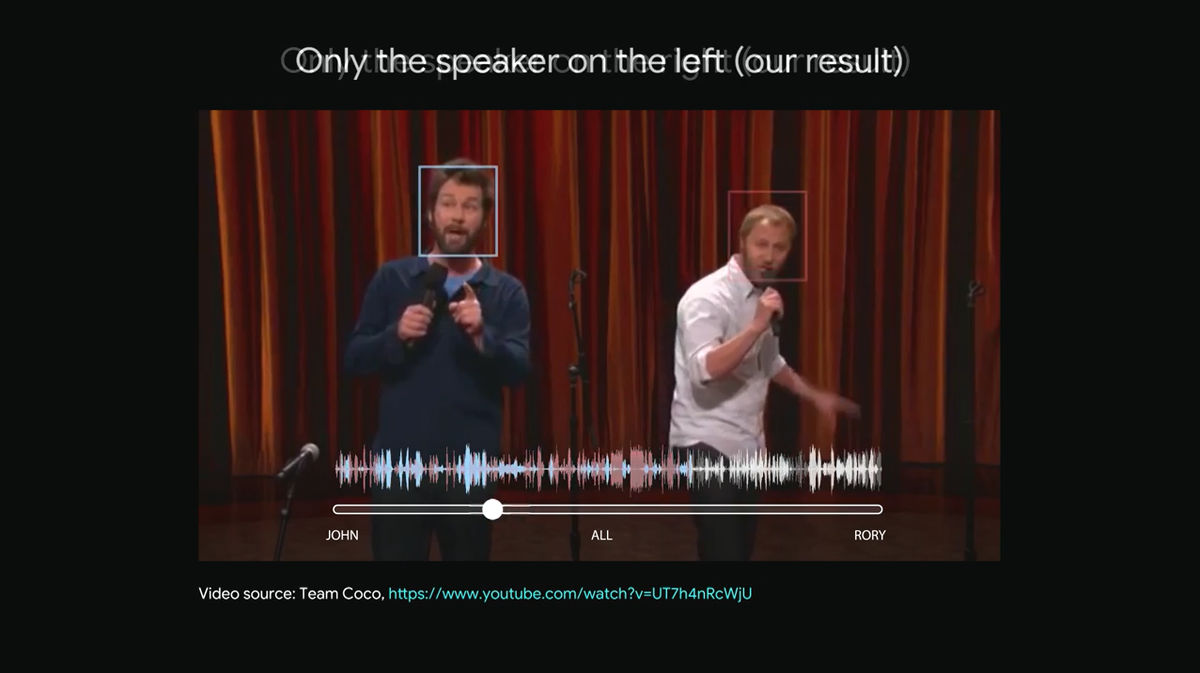
Then, only the sound represented by the light blue waveform that the man on the left speaks can be selectively heard.
The characteristic feature of Google's "Looking to Listen" technology is that it integrates both the auditory and visual signals of the movie to separate the sound. Movement and gesture of a person's mouth correlates with the voice the person speaks and it helps to identify the voice the person speaks. Compared with speech separation technology using only auditory signals, when using visual signals together, it is possible to greatly improve speech separation quality.
As a teaching material of deep learning, Google's research team gathered 100,000 lectures and lecture movies from YouTube, there are no background noise or other people's talking out of it, only one talker is shown in the movie "Clean voice and video" was extracted for about 2000 hours. After combining these clean voices and images, the research team created an "artificial cocktail party" and made artificial intelligence learn. As a result, it seems that it became possible to emphasize the voice that the selected person speaks and suppress unrelated sounds.

Even when the same person reflects in the same movie and tells a totally different thing, we succeeded in separating the sound by making learning using visual signals. Being Google CEOThunder PichaiIn the following movie synthesizing his speech, you can see that artificial intelligence can selectively separate speech despite the mixture of utterances by the same person.
Looking to Listen: Double Sundar
Google is assuming a wide range of applications using "Looking to Listen" technology, of which "Looking to Listen" may be applied to our neighborhood.
Related Posts:







