NVIDIA announces 'Fugatto,' an AI audio generator that can create 'never-before-heard sounds' from text and voice

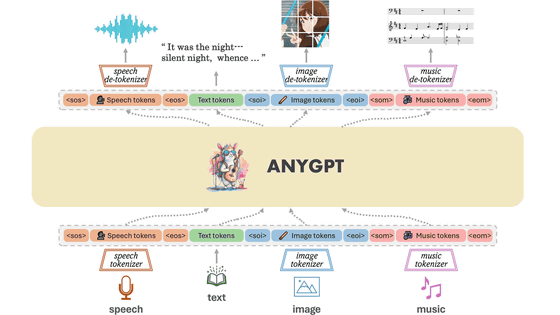
NVIDIA has announced Fugatto (Foundational Generative Audio Transformer Opus 1), an AI that generates speech from text and speech. AI that generates music has existed in the past, but Fugatto's unique feature is that it can extract a part from an existing song based on input text or speech, change the accent or emotion of the voice, and generate sounds that have never been heard before.
fugatto.github.io
Fugatto 1 Foundational Generative Audio Transformer Opus 1
(PDF file) https://openreview.net/pdf?id=B2Fqu7Y2cd
Fugatto, World's Most Flexible Sound Machine, Debuts | NVIDIA Blog
https://blogs.nvidia.com/blog/fugatto-gen-ai-sound-model/
You can see what kind of AI Fugatto is in one shot by watching the movie below.
Audio AI Fugatto Generates Sound from Text | NVIDIA Research - YouTube
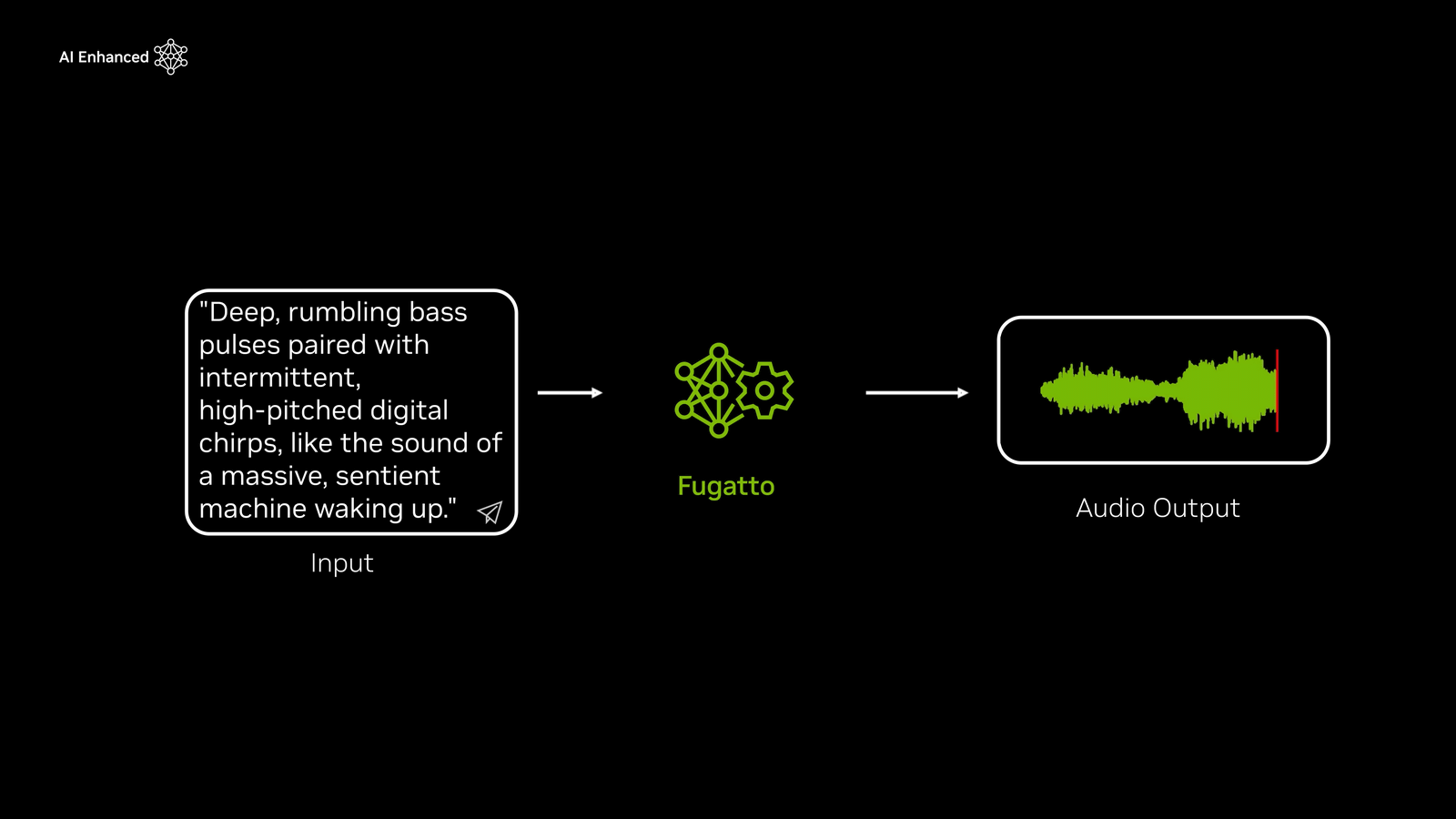
In the movie, you can hear the sound when the text prompt is specified as 'a deep, thunderous bass pulse combined with intermittent high-pitched digital chirps, like a giant intelligent machine waking up.' Although it's a pretty original expression, 'a sound like a giant intelligent machine waking up,' Fugatto generates a sound that sounds like it.
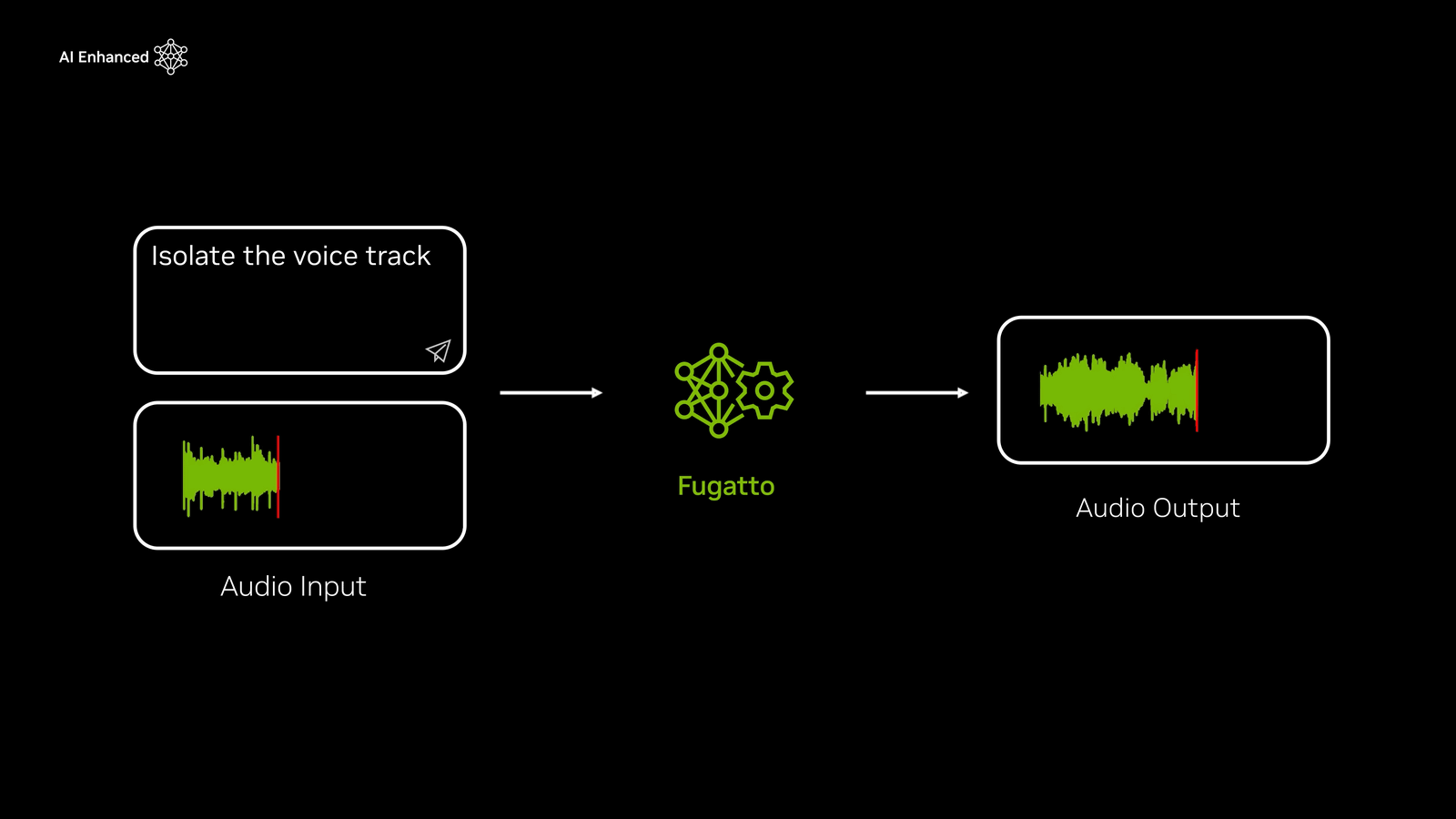
It is also possible to extract only the vocals from the input audio.
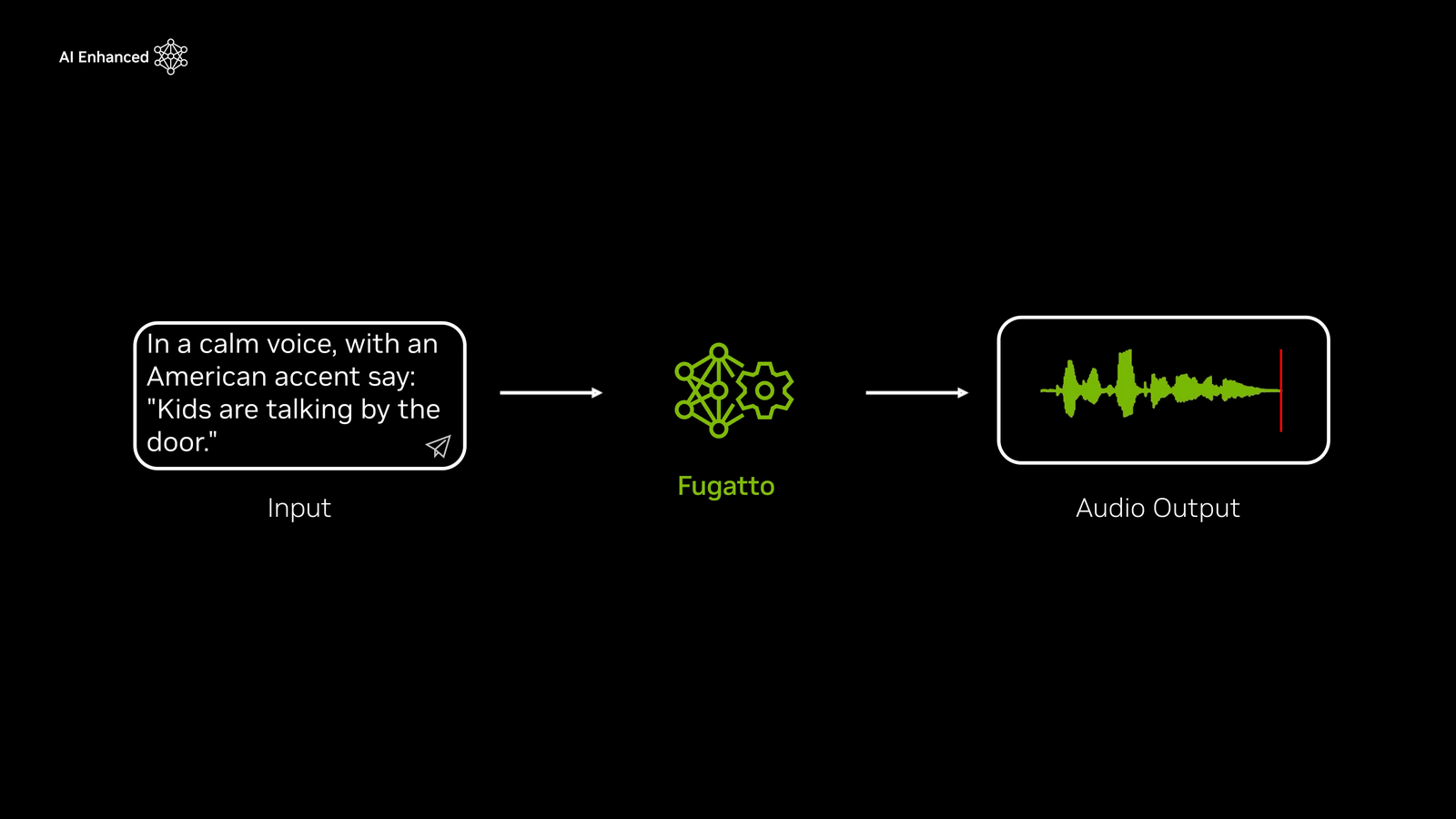
When I specified 'a calm voice with an American accent saying 'children talking near the door,'' a fairly natural speaking voice was generated.
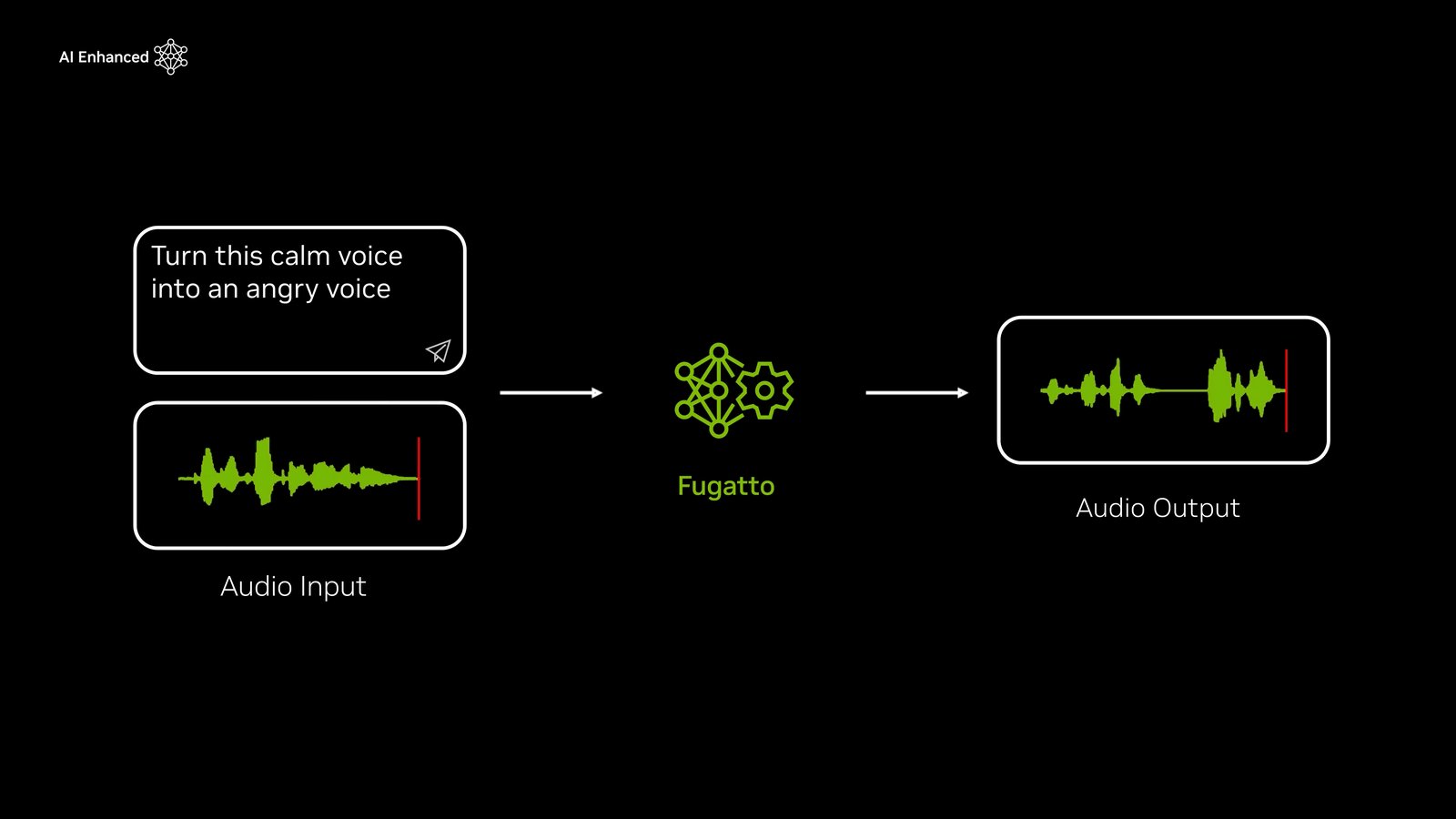
Furthermore, if you select 'from calm to angry,' the emotion of the voice will change drastically, transforming it into a slightly rougher male voice.
Simply input the music you've created and ask it to 'add drums and synthesizers,' and it will automatically add the parts.
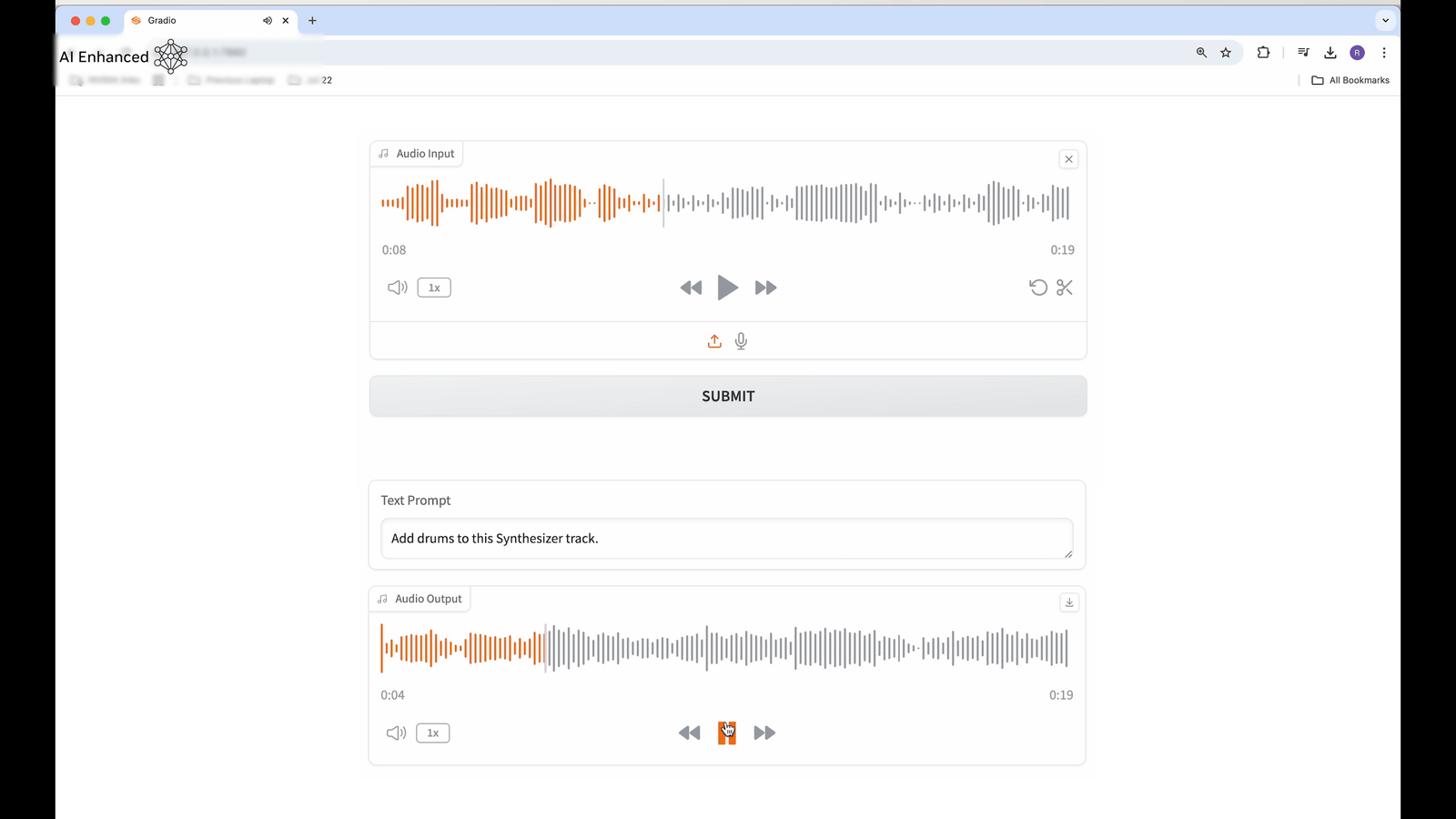
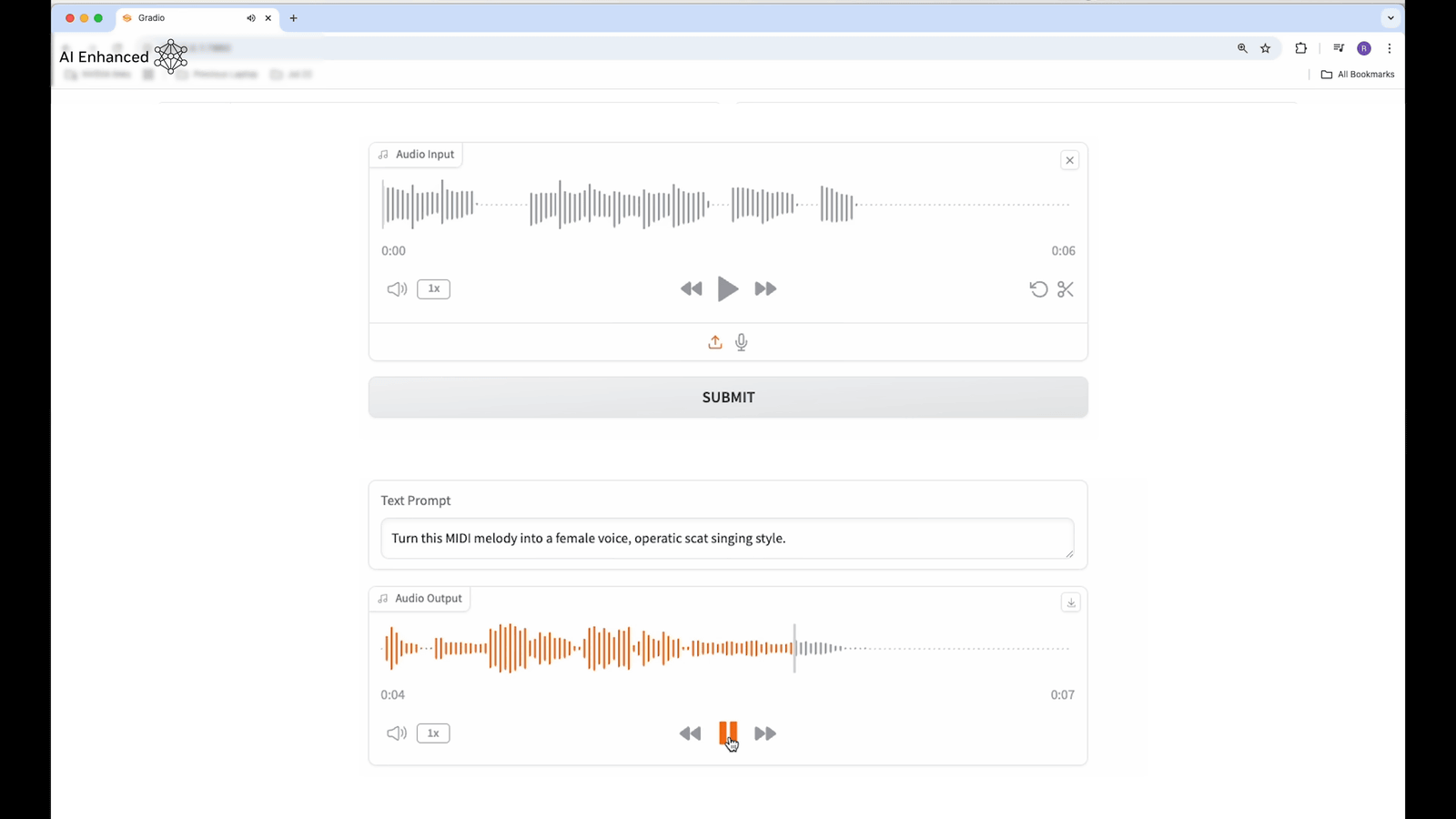
Also, when I input MIDI audio and specified 'to make it sound like an opera-style scat,' it was properly converted to sound like a female opera singer singing scat.
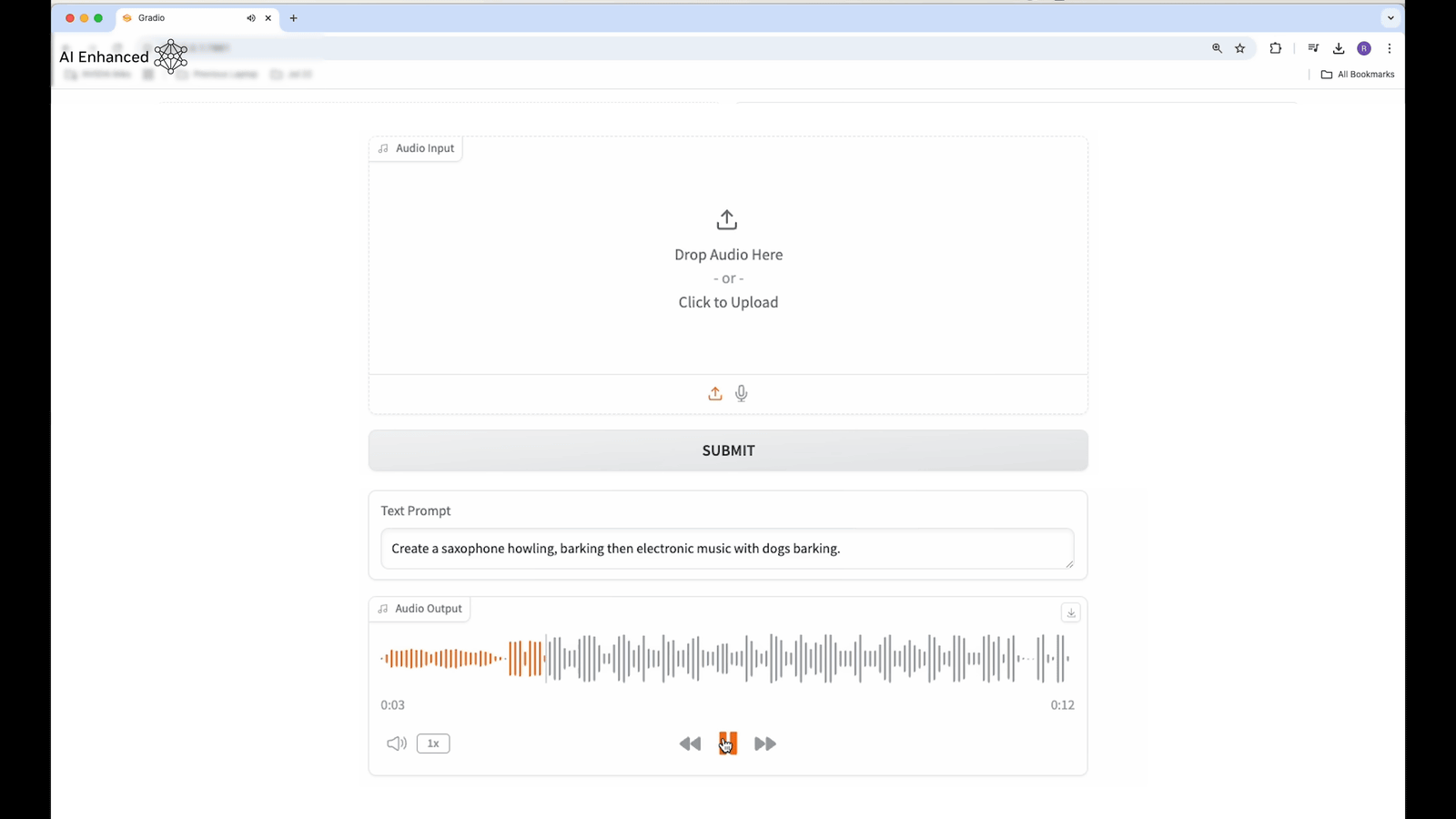
The voice was also generated with the instruction, 'Create a sound that starts with a saxophone howl and then combines dog barking and electronic music.' NVIDIA appeals that the ability to create a new acoustic experience with elements that are not usually combined, such as saxophone, dog barking, and electronic music, is a feature that shows Fugatto's flexibility and creativity.
Fugatto is based on the T5-based Transformer architecture and combines a text encoder and an audio encoder. The text encoder uses a ByT5 language model, and the audio processing uses a relatively shallow trainable Transformer encoder.
Fugatto's model size can be expanded up to 2.5 billion parameters, and it is trained on a large dataset consisting of more than 50,000 hours of speech data. This allows a single model to be versatile enough to handle a variety of speech synthesis tasks. To maintain the quality of the speech, it uses a pre-trained universal vocoder called BigVGAN V2 to generate waveforms from mel spectrograms.
The core feature is the adoption of a technique called 'optimal transport conditional flow matching.' This technology allows smooth control of the voice generation process, enabling high-quality voice synthesis, the NVIDIA research team said. Another major feature of Fugatto is 'ComposableART,' which allows multiple instructions to be combined, interpolated, or negated. This is a technology used during inference, which allows for fine control, such as gradually changing different voice effects or excluding certain elements.
'We wanted to create a model that can understand and generate sound in the same way that humans do,' said Rafael Valle, manager of applied audio research at NVIDIA. 'Fugatto is the first step toward a future where the scale of data and models enables unsupervised multitask learning in speech synthesis and conversion.'
Related Posts: