Adobe announces audio version Photoshop "VoCo" to rewrite human remarks freely
Developer meeting held by Adobe in San Diego, USA "Adobe MAX 2016"By cutting and pasting text or entering text as text, you can change the voice of the speaker freely"VoCoWe announced. For Photoshop which can modify and change "image" freely, it is finished to say "audio version Photoshop" which can modify / change freely "audio".
You can understand what kind of technology VoCo is in a single shot by looking at the following movie.
VoCo. Adobe MAX 2016 (Sneak Peeks) | Adobe Creative Cloud - YouTube
It is Zeyu Jin (Jieu Jin) who announces VoCo.

Use Michael 's voice sitting on the left edge of the video as a sample.
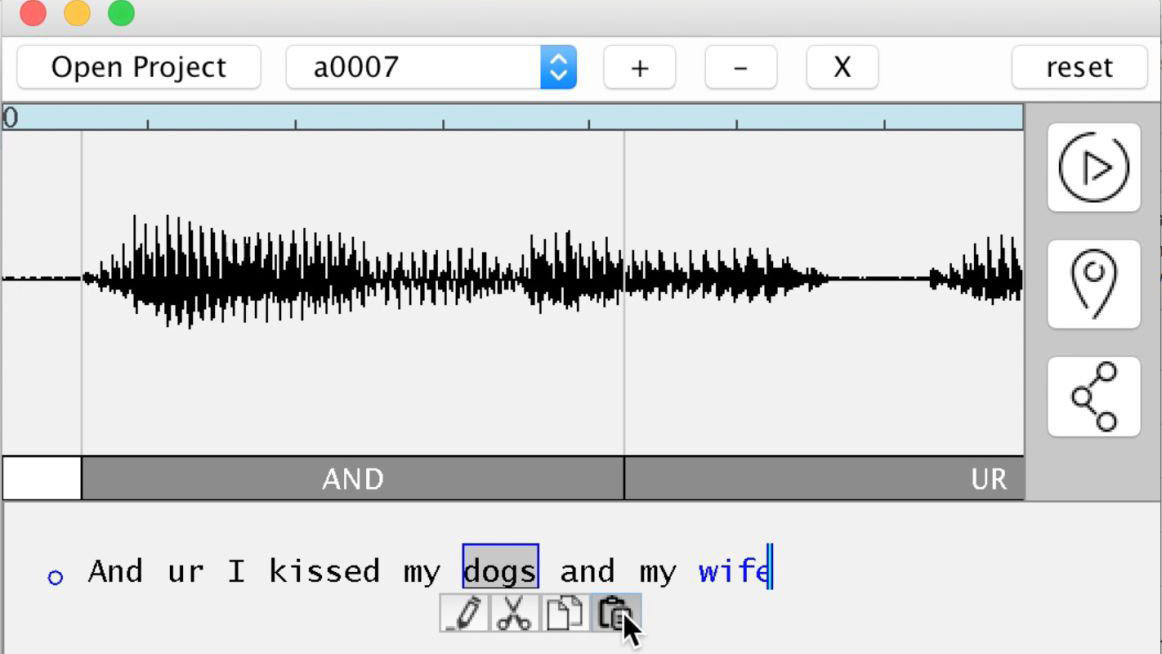
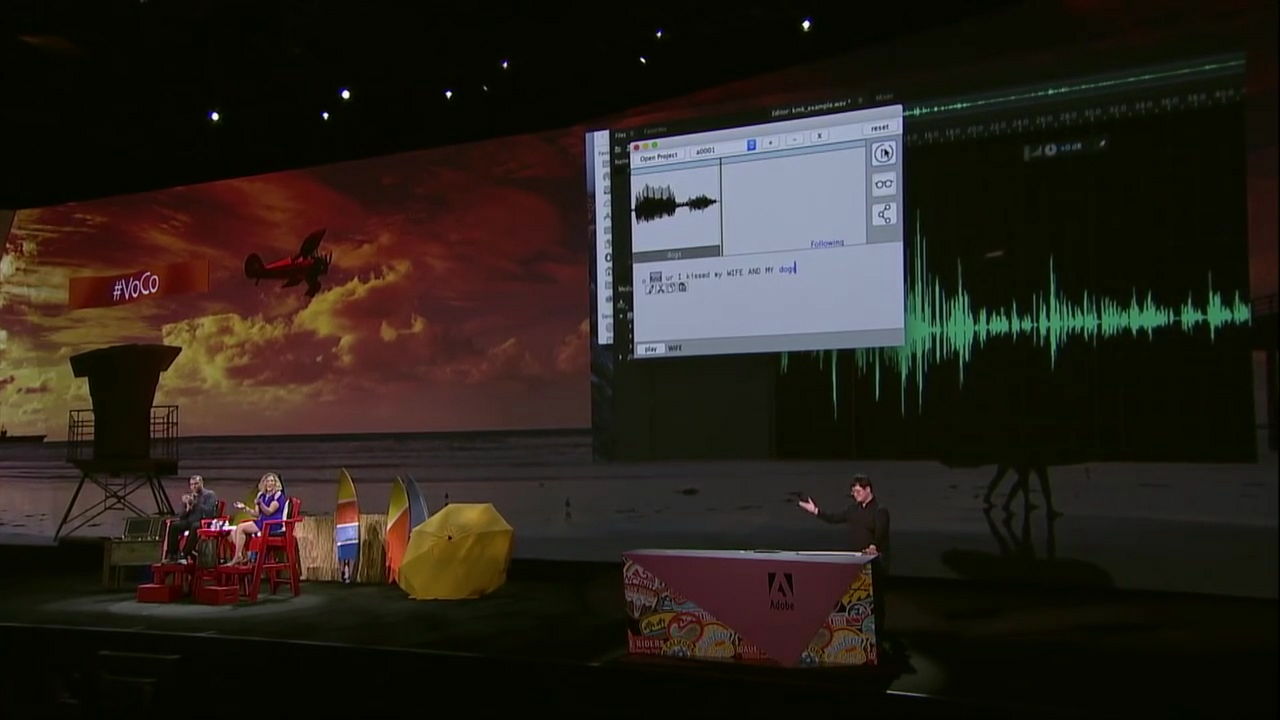
From the conversation with Mr. Michael, when taking out the joke part "I kiss my wife after kissing my dog", the contents of this remark was displayed in text with voice waveform on a separate window.
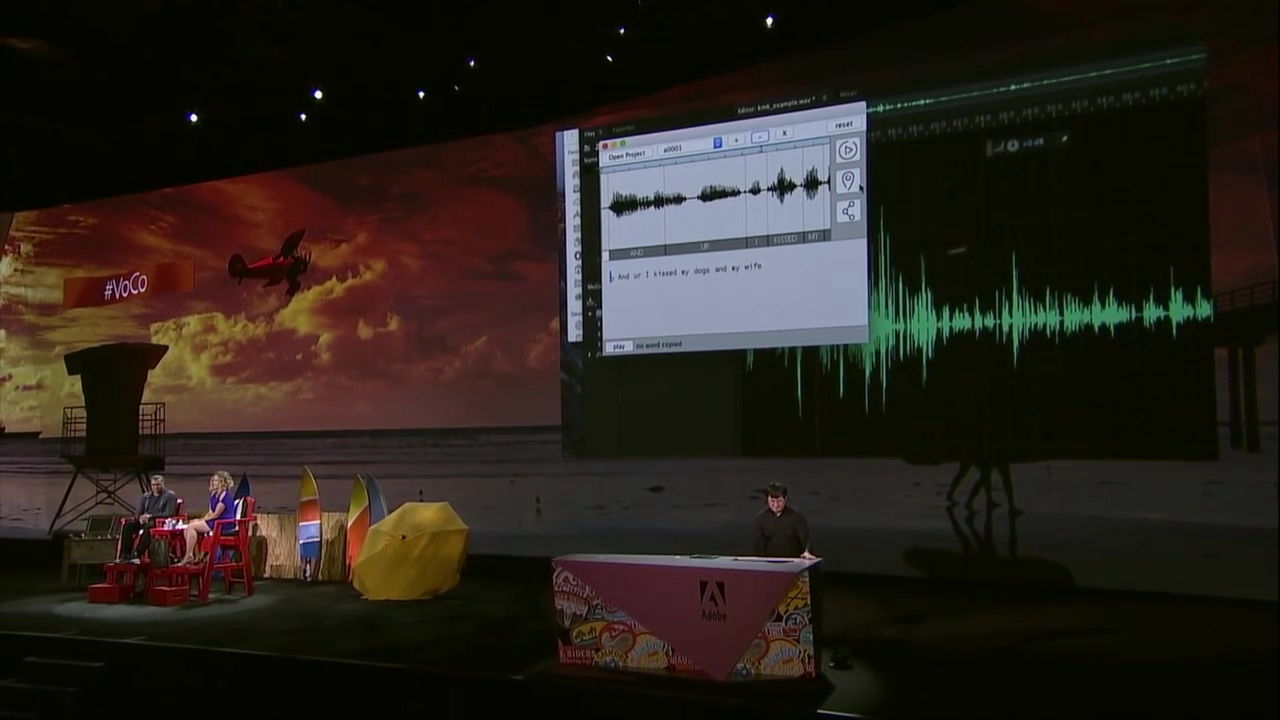
The function of VoCo is more than just speech to text. Copy the text part "wife" and paste it on the part called "dog (dog)" and play the sound ...
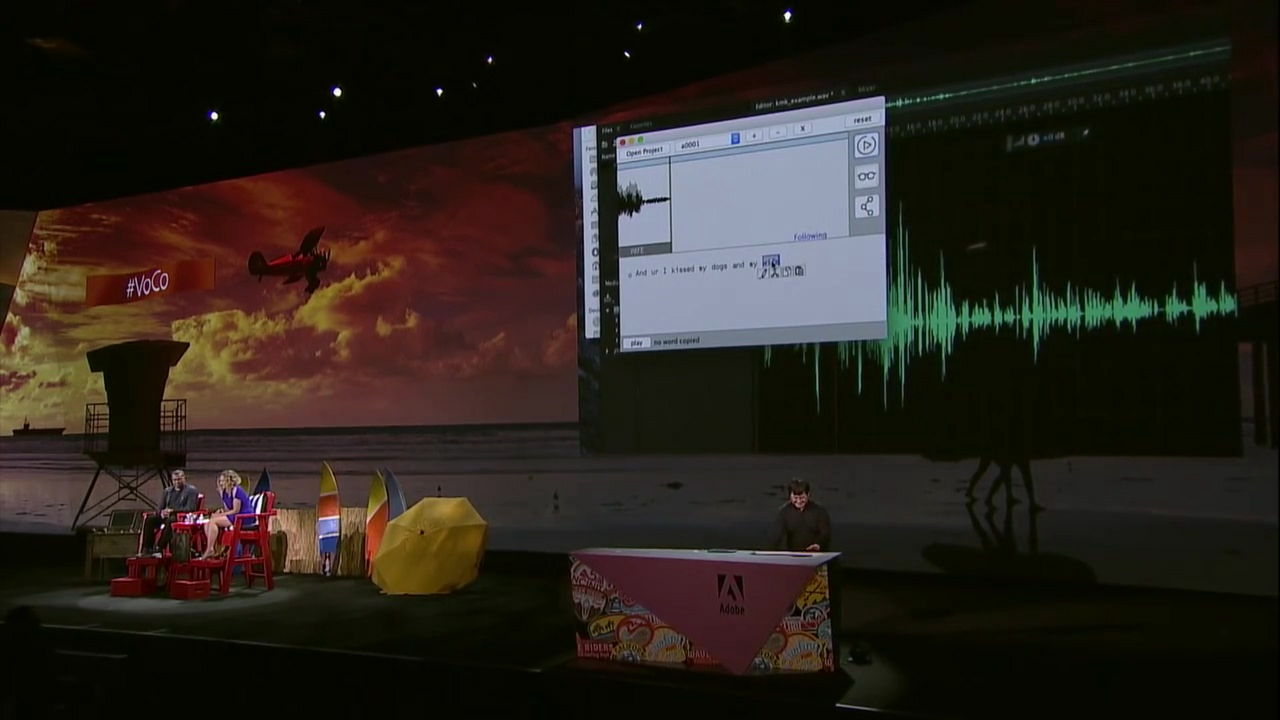
"I kiss my wife after kissing my wife," replacing the "dog" part with "wife", and the remarks that undermine my wife changed all over to a loving rubbish remark. Michael also laughs hard at this.
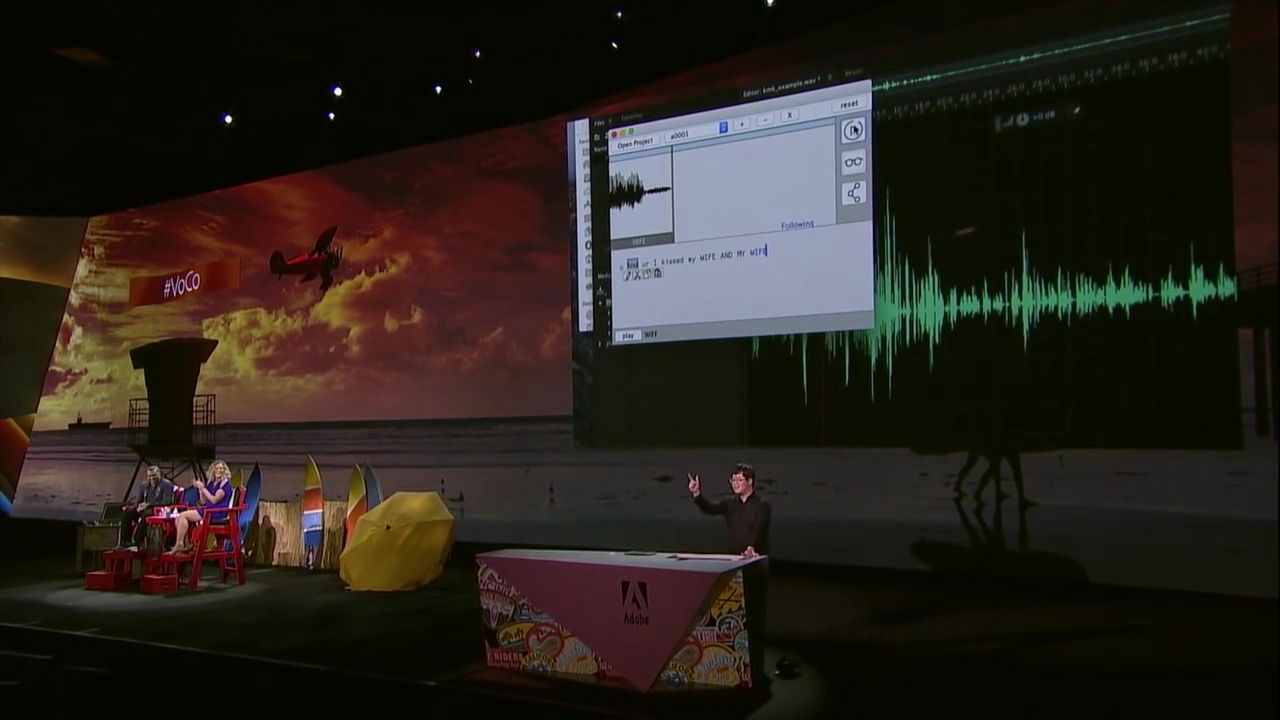
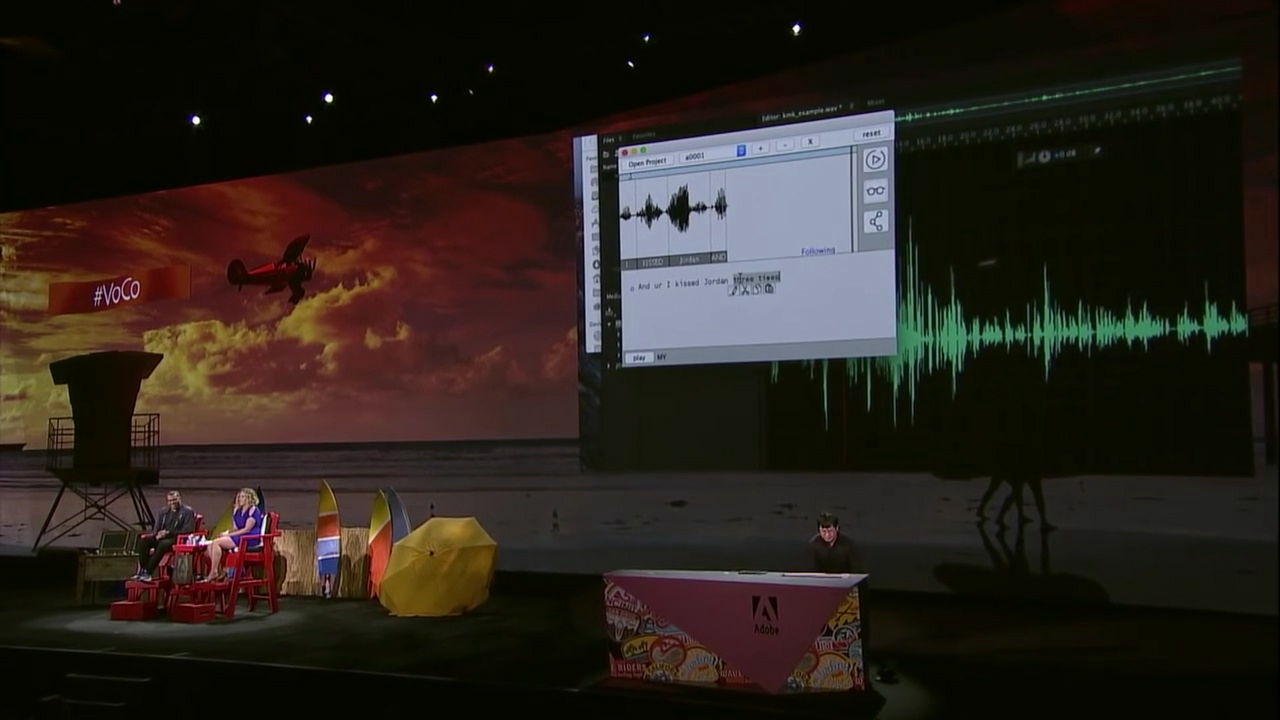
VoCo's frightening is where you can modify audio beyond simply copying and pasting. If you change the part of 'wife' to the name of a man named 'Jordan' ...
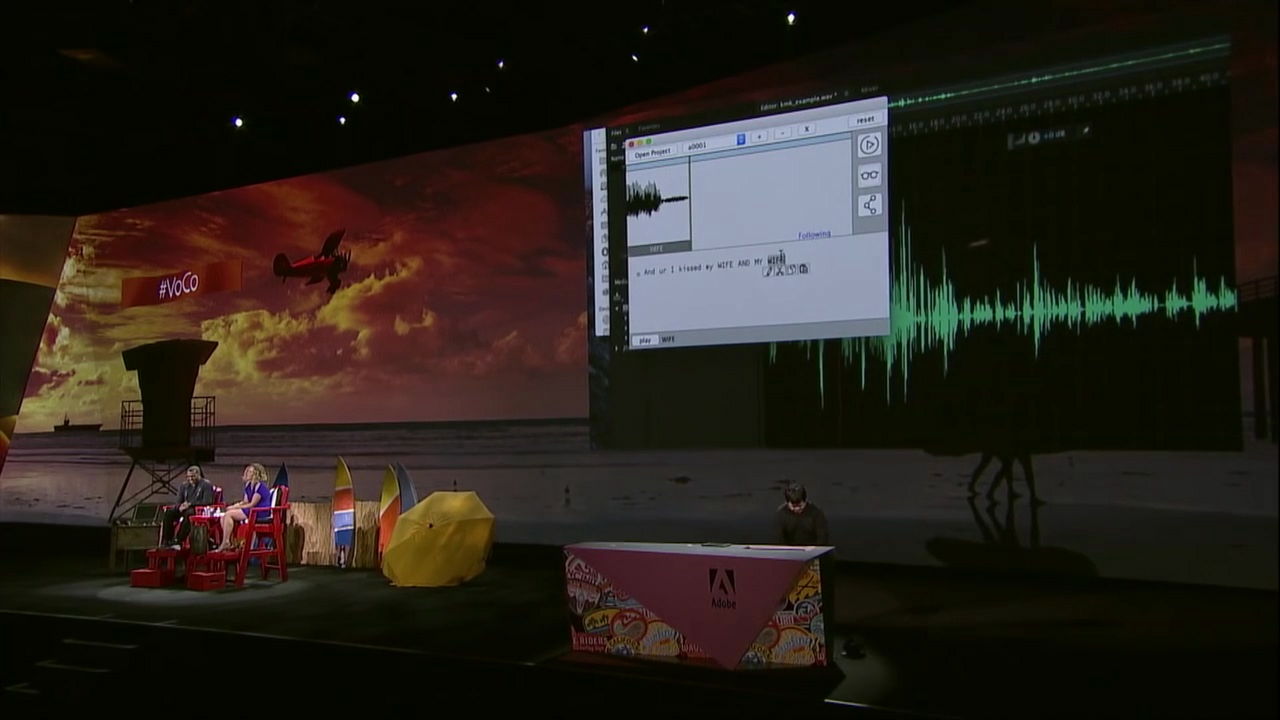
It turned into a remark that saying "I kiss a dog after kissing Jordan."
Furthermore, if we change the part of "dog" to the word "three times (3 times)" ...
Completely napping remarks were born "I kiss Jordan three times".
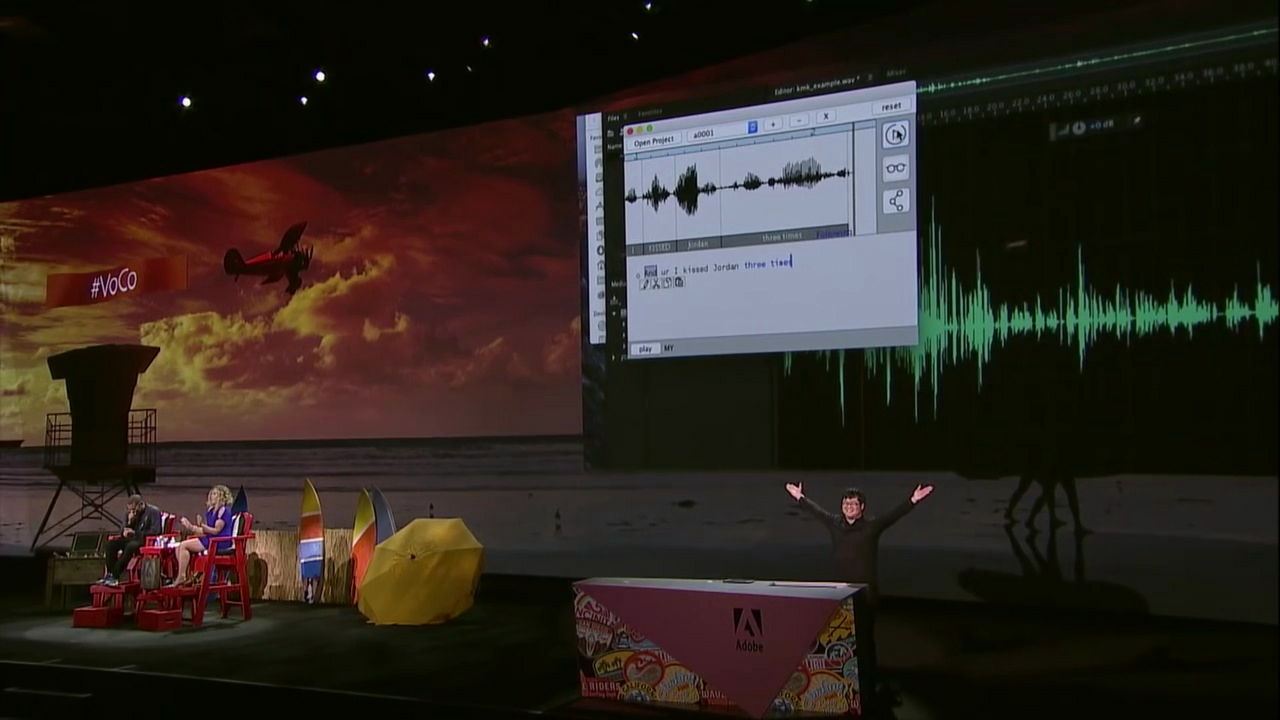
Michael, who showed the power of VoCo, asks "Can you freely make sounds from a single phrase?"

Mr. Jin said, "If you have one speech in about 20 minutes, you can handle it like an AudioBook and get the speaker's way of speaking, then you can correct the remark by text input."

VoCo uses a new technology that learns from the sample speech to the speaker's way of talking beyond the word level using Adobe's machine learning technology "Adobe Sensei (Adobe teacher)" and hear it No new words can be produced as speech. In addition, it adopts an automatic correction function using an algorithm to make sound data automatically generated from text be heard as natural remarks. VoCo currently supports English only, but it is possible to develop multilingual. It seems that the unexpected coming of the future that you can freely change the content of what you say is close.
Related Posts: