




Microsoftがわずか数秒のサンプルから会話や歌声を再現できる音声合成AI「NaturalSpeech 2」を発表

2023年4月18日にMicrosoft Research AsiaとMicrosoft Azureのカイ・シェン氏らの研究チームが拡散モデルを使用した小品質の音声合成システム(TTS)である「NaturalSpeech 2」を発表しました。NaturalSpeech 2では数秒の短い音声サンプルを利用する事で、人の声だけでなく歌声までも忠実にシミュレートすることが可能になっています。
[2304.09116] NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers
https://doi.org/10.48550/arXiv.2304.09116

NaturalSpeech 2
https://speechresearch.github.io/naturalspeech2/
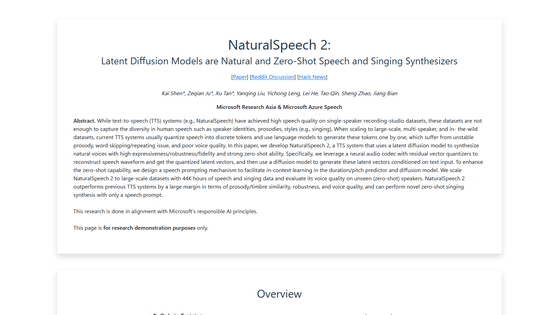
これまでのTTSシステムは、単一話者が録音したデータセットにおいて高い音声品質を達成していますが、これらのデータセットでは人間の多様なアイデンティティやアクセントなどのスタイルを把握しきることは不可能です。また、大規模で多人数のデータセットに拡張する場合、現在のTTSシステムは、通常、音声を個別のトークンに量子化し、言語モデルを用いてトークンを1つずつ生成する都合上、不安定な韻律や単語のスキップ・リピートの問題、音声品質の低さが問題となっています。
しかし、シェン氏らの研究チームが開発した「NaturalSpeech 2」では、潜在拡散モデルを利用する事で、高い表現力や再現性を持ち、サンプルの声を忠実に再現したテキスト読み上げモデルを作成することが可能です。
NaturalSpeech 2は、ニューラルネットワークを使用したオーディオコーデックと残差ベクトルの量子化器を用いて入力された音声の波形を再構成し、拡散モデルを用いてテキスト入力を条件とした潜在ベクトルを生成しているとのこと。さらにNaturalSpeech 2ではゼロショット学習を強化するため、音声のピッチ予測器と拡散モデルの文脈内学習を促進するための発話促し機構が搭載されています。また、NaturalSpeech 2では、韻律や声質などの点でこれまでのTTSシステムを上回っているとされています。
シェン氏らの研究チームが発表した論文では、実際にNaturalSpeech 2を用いた音声合成の例が提示されています。以下はLibriSpeechを用いて学習した、「実際、同じ結果を出さずに姉妹の中に入れる見知らぬ人は、1人か2人しかいませんでした(Indeed, there were only one or two strangers who could be admitted among the sisters without producing the same result.)」という文章を読み上げる過程です。最初にプロンプトとして数秒の無関係の音声を入力します。
「Ground Truth」の音声は、サンプル音声と同じ人が書かれたテキストを読み上げたもので、これが目標となる「正解の音声」となります。
以下の「Baseline」は従来のAIモデルで作成した合成音声です。抑揚がなくやや不自然で機械的ですが、人間に近い音声が出力されています。
NaturalSpeech 2を用いて出力された音声が以下。息継ぎやアクセントの面で「人間の声」と言われても遜色ないレベルの音声が出力されていることが確認できます。
エジンバラ大学の研究チームによる「VCTK」を用いた学習例が以下。「角を曲がります(We will turn the corner.)」という音声を生成するためにまずは無関係の音声を入力します。
以下は「Ground Truth」の音声です。
「Baseline」での音声出力が以下。
以下はNaturalSpeech 2を用いて出力した「角を曲がります」の音声です。
研究チームはMicrosoftが開発した音声合成AIモデル「VALL-E」との比較も行っています。「このように、この人道的で正しい心を持った父親は、不幸な娘を慰め、母親は再度彼女を抱きしめ、彼女の気持ちを和らげるためにできる限りのことをした(Thus did this humane and right minded father comfort his unhappy daughter, and her mother embracing her again, did all she could to soothe her feelings.)」という文章をVALL-Eで出力した音声が以下。
以下はNaturalSpeech 2を用いた音声出力です。
NaturalSpeech 2では歌声での入力や歌声の出力も可能です。「なので注意深くよく聞いてください(So listen very carefully.)」という歌詞で歌唱した例が以下。まずは無関係の文章を入力します。
すると抑揚やリズムのある歌声になって出力されます。
NaturalSpeech 2では歌声からの入力も可能です。以下の例では同様の「BINGO」を歌唱しています。
以下の例では、歌声での入力を行った場合でも、同様に歌声での出力を行うことが示されています。
Microsoftの研究チームは「NaturalSppech 2は忠実な表現が可能で、話者の模倣やなりすましなど悪用される危険性があります」と注意喚起を行っています。また、これらの倫理的・潜在的な問題を回避するために研究チームは「この技術を悪用しないこと、AIが合成した音声を検出するための対策ツールを開発することを開発者に対して訴えています」と主張しています。さらに、「このようなAIモデルを開発する際には、常にMicrosoftの責任あるAIの基本原則を順守しています」と述べています。
NaturalSpeech 2のソースコードはGitHub上で公開されています。
GitHub - lucidrains/naturalspeech2-pytorch: Implementation of Natural Speech 2, Zero-shot Speech and Singing Synthesizer, in Pytorch
https://github.com/lucidrains/naturalspeech2-pytorch
・関連記事
Microsoftがたった3秒のサンプルから人の声を再現できる音声合成AI「VALL-E」を発表 - GIGAZINE
AIを使った音声圧縮で従来の圧縮を超えた圧縮率と圧縮速度を「Encodec」が実現 - GIGAZINE
AIで作成したクローン音声で誘拐をでっち上げて身代金を要求する事件が発生 - GIGAZINE
Googleが入力したテキストから自動で作曲するAI「MusicLM」を開発 - GIGAZINE
まるで本物の人間のように表現力豊かに発話できるAIをNVIDIAが開発中 - GIGAZINE
・関連コンテンツ






in AI, ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article Microsoft announces 'NaturalSpeech 2,' a….