




きちんとチェックすると「781年」かかるAI用データセット「LAION-5B」の課題がよくわかる「Models All The Way Down」

Stable Diffusionをはじめとする主要な画像生成AIのトレーニングには、50億枚超の画像とテキストのセットである「LAION-5B」が用いられています。週5で働くフルタイム労働者が1秒ずつ画像を目視確認すると781年かかるといわれているデータセットの膨大さや、その問題点がまとめられたサイト「Models All The Way Down」が公開されました。
Models All The Way Down
https://knowingmachines.org/models-all-the-way

上記のURLにアクセスしてスクロールすると、背景にさまざまな画像とそれに紐付けられたテキストデータが現れては消えていきます。これは、LAION-5Bに収録されているデータセットとのこと。
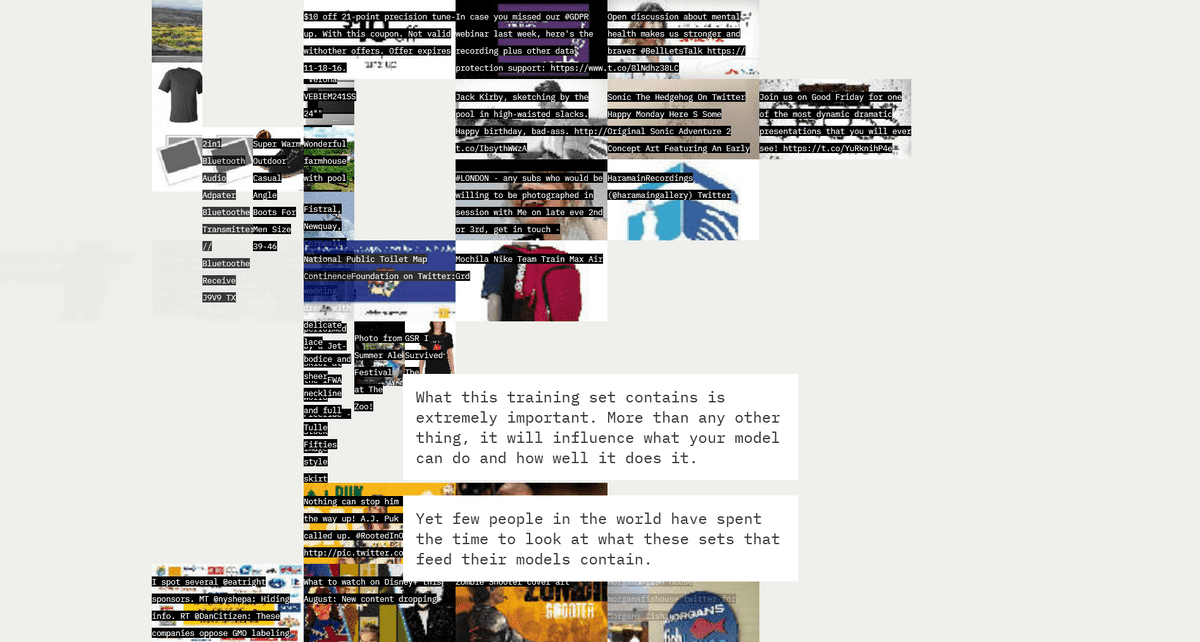
LAION-5Bの公開ページには「すぐに使える製品の作成に使用することはお勧めしません」との注意書きが記されていますが、この警告はほぼ無視されており、児童ポルノ画像が多数紛れ込んでいることが発覚するといった形で問題がたびたび表面化しています。
画像生成AI「Stable Diffusion」などに使われた50億枚超の画像セット「LAION-5B」に1008枚の児童ポルノ画像が入っていることが判明し削除へ - GIGAZINE
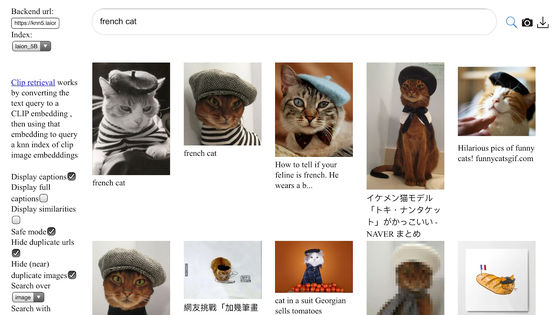
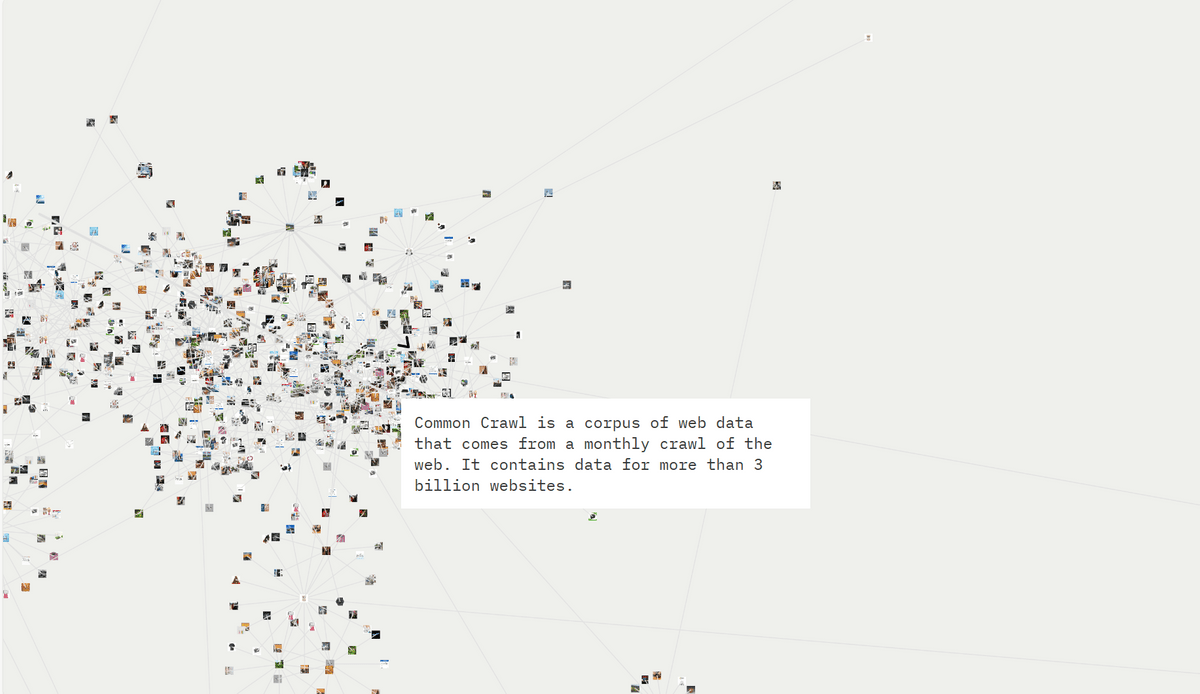
さらにスクロールすると、LAION-5Bが作成された経緯が解説されます。それによると、LAION-5Bは別の非営利団体であるCommon Crawlが提供するさらに大きなデータセットから構築されているとのこと。Common Crawlはクローリングで毎月インターネットからデータを取得しており、これには30億以上のウェブサイトのデータが含まれています。
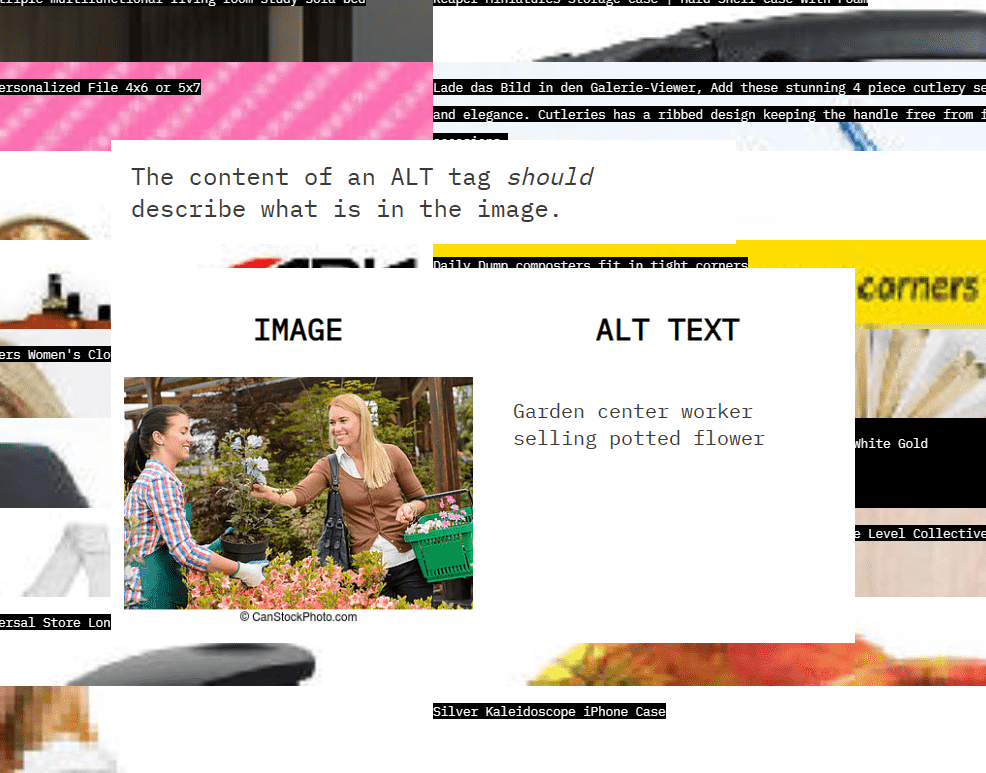
LAION-5Bの画像の出どころとして代表的なサイトには、写真共有サービス・Pinterest、eコマースプラットフォーム・Shopify、PowerPointデータ共有プラットフォーム・SlidePlayerなどがあります。これらのサイトには、視覚障害者のために代替テキストを付与するALT属性でキャプションが付けられた画像が多く掲載されているため、特に重宝されています。

ALT属性による説明の例が以下。写真には花を売り買いする2人の女性が写っており、そこに「花を販売する園芸センターの店員」というテキストがつけられています。
しかし、視覚障害者に向けた本来の使われ方をしているのはまれで、ALT属性の多くは人間のためではなくアルゴリズムを引きつけるために使用されているのが現状とのこと。例えば、以下のように「Heart Shaped Sunnies - Chynna Dolls Swimwear(ハート型サングラス・Chynna Dollsの水着)」というようなテキストがつけられていると、それを読み上げソフトで聞いても何の写真かわかりません。
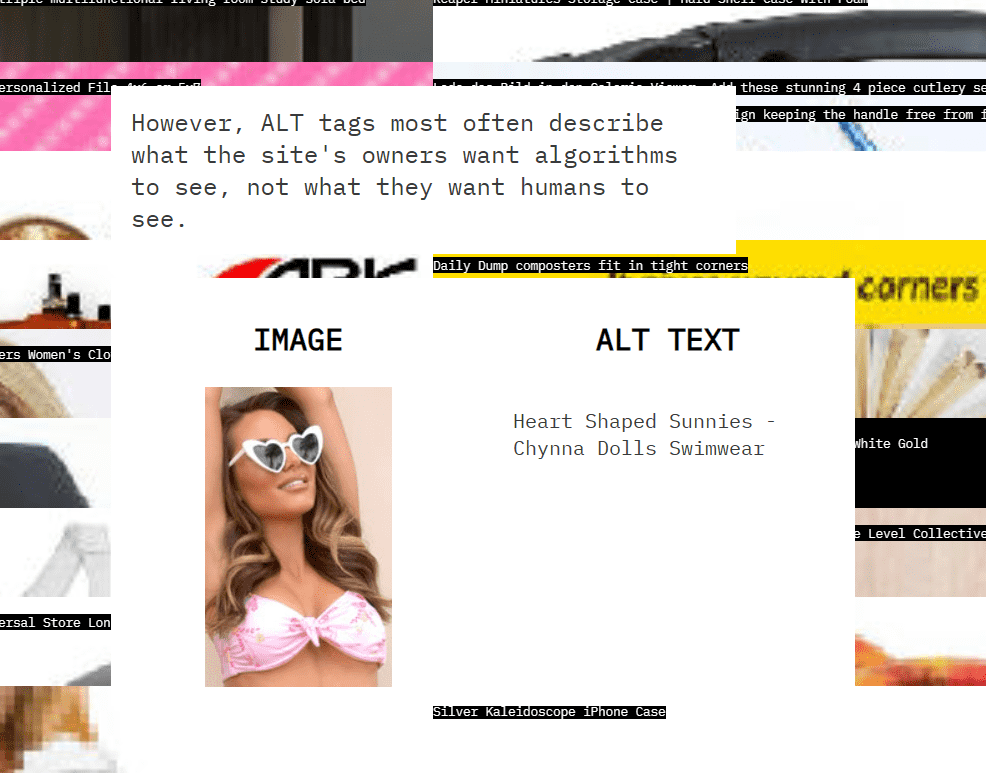
「LAION-5Bの真実は、人間が世界をどう見ているかよりも、検索エンジンが世界をどう見ているかの方が多く含まれていることです」とModels All The Way Downは訴えています。
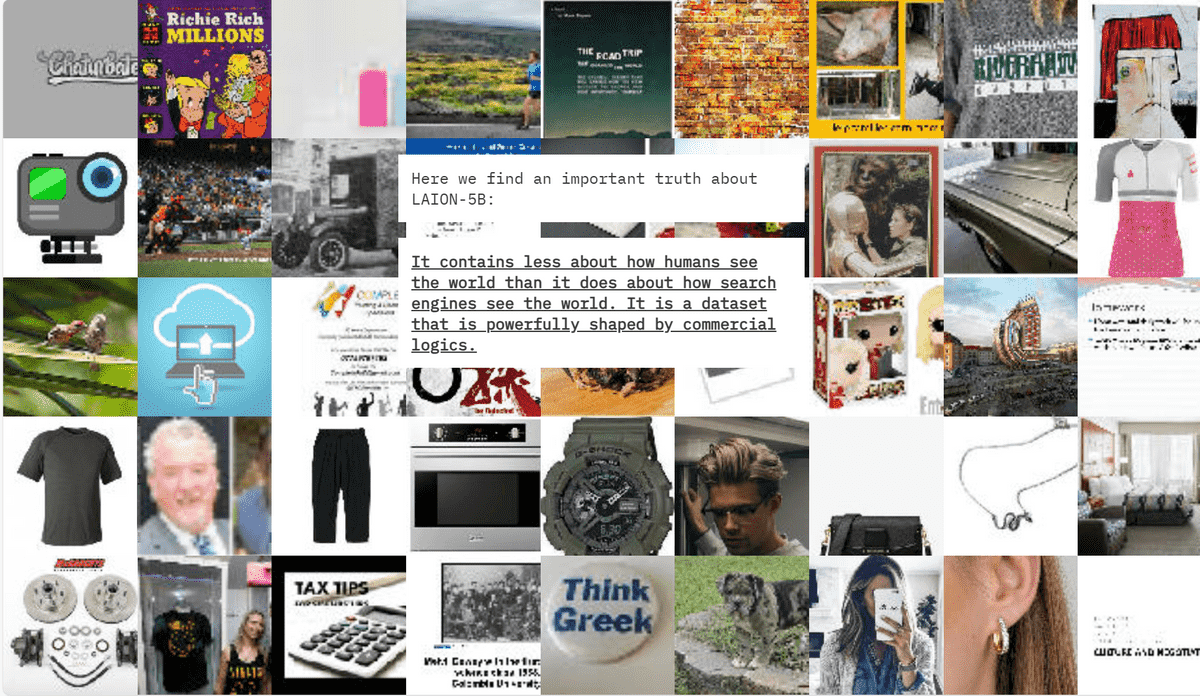
ALT属性のテキストが画像の内容とマッチしている画像とテキストキャプションのセットを選び出すため、LAION-5BはOpen AIが開発したモデルである「CLIP(Contrastive Language–Image Pre-training)」を使って、テキストの文字列と画像の類似性を示すスコアを取得しました。
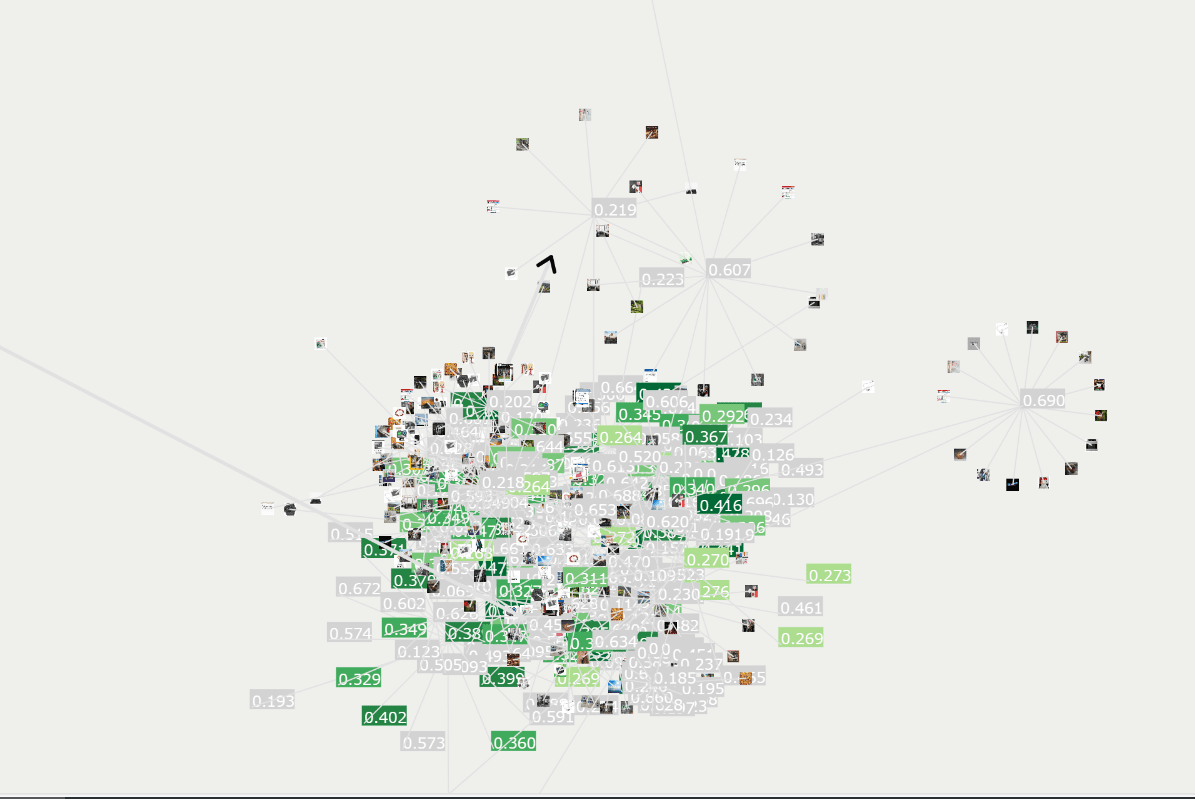
しかし、選び出された画像のスコアにはばらつきがあり、50億枚のうちスコアが0.5以上のものはたった2万2645枚で、全体の16%はスコアが0.1以下でした。このような精度の面での難点があるため、LAIONの研究者が類似性スコアの許容値を0.01引き上げるだけで、データセットから9億組以上の画像とテキストのセットが消えてしまうとのこと。

このことから、2つの重要な問題点が浮かび上がります。1つ目は、アルゴリズムによるキュレーションはスコアに依存しており、画像やテキストの内容が度外視され、データセットに採用される画像やテキストも何が基準となっているか誰も把握していない点です。そして、2つ目はデータセット作成の過程に「モデルを使ってモデルを作る」という循環性が存在しており、あるモデルやトレーニングセットに存在した盲点や偏りが延々と新しいモデルやデータセットに引き継がれてしまう点です。

また言語的にも偏りがあります。前提として、LAIONのデータセットは、英語に紐付けられた「LAION-2B EN」、そのほかの言語の「LAION-2B MULTI」、言語が特定できなかった「LAION-1B NOLANG」の3つのサブセットにわかれています。
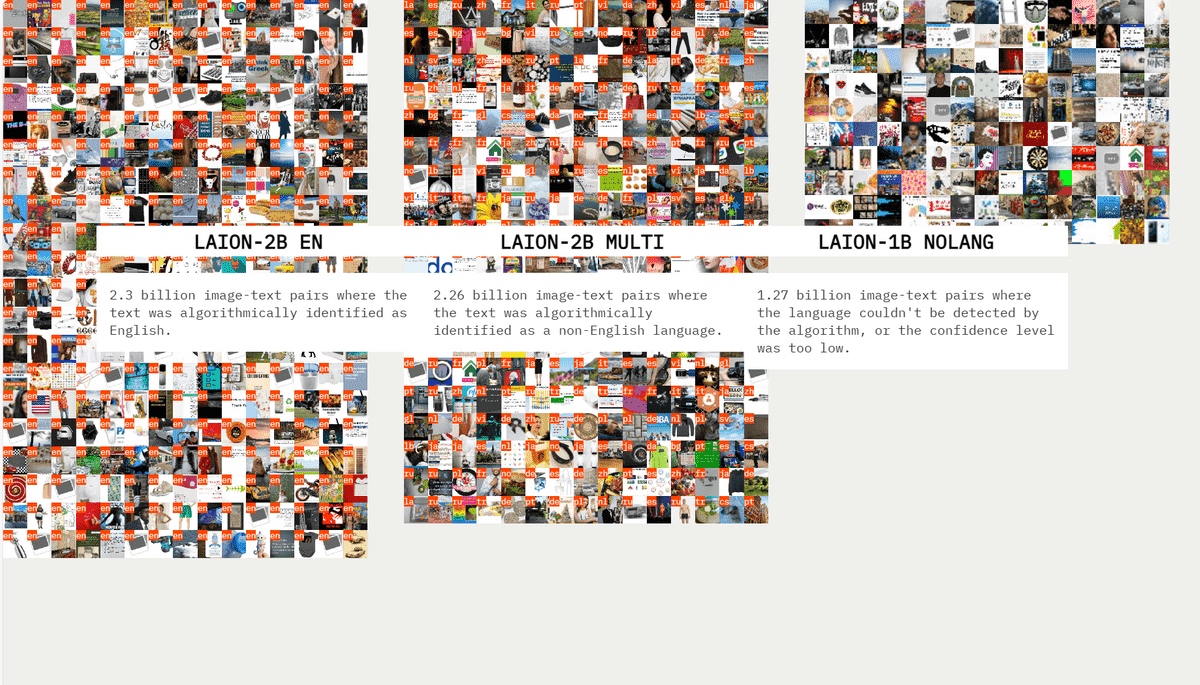
英語以外ではロシア語が一般的で、データセットには地球上の2億5500万人のロシア語話者1人につき、Russianとラベル付けされた画像キャプションが1枚存在します。同様に、フランス語話者2人につき1枚の画像が、スワヒリ語話者35人につき1枚の画像があります。一方、英語話者には1人当たり1.6枚、オランダ語話者1人当たり3枚、アイスランド話者1人当たり7枚の画像が存在します。
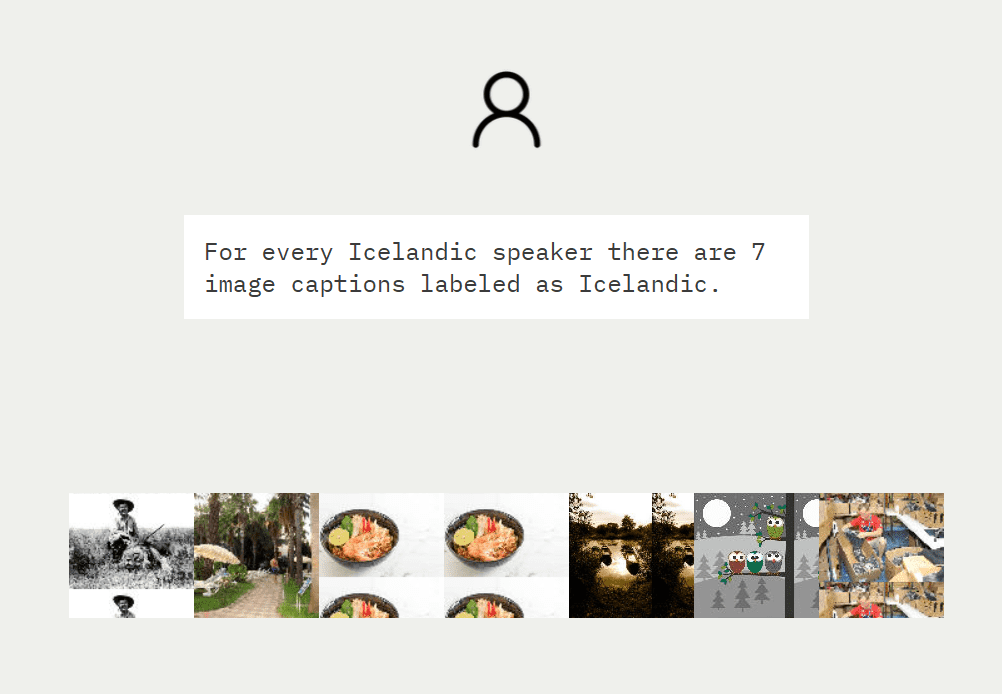
さらに、LAION-5Bには話者が30万人しかいないルクセンブルク語に分類されたテキストキャプションが約3500万個ありますが、元のトレーニングセットには約3万3000ページしかありません。それもそのはずで、ルクセンブルク語とされたデータセットを見ると、ほとんどが英語か別の言語だったとのこと。「これはLAIONの自動処理がどのように失敗するかを示す端的な例です」とModels All The Way Downは指摘しました。

言語のサブセット以外にも、LAION-5Bには品質が高い画像をまとめた「LAION-Aesthetics」というデータセットがありますが、その質はごく少数の人々によって評価されました。つまり、データセットの評価のほとんどは一握りのユーザーによって提出されたものであり、その美的な好みがデータセットを全体支配していることになります。このことから、「視覚的に魅力的なものとそうでないものの概念は、ごく少数の個人の好みや、データセット作成者がデータセットをキュレーションするために選択するプロセスによって左右される」という問題点が浮き彫りになります。

このように、LAION-5Bはさまざまな問題を抱えつつも、「すぐに使える製品の作成に使わないこと」というただし書きの元で、その問題の解決を先送りにしたままAI開発に使われ続けています。しかも、この問題を特定できたのはLAION-5Bがオープンに公開されていたからですが、児童ポルノの問題が判明して以降は新しくダウンロードできなくなっています。開発者は「問題の修正に取り組んでいます」と約束していますが、それが実現しないうちに、今度はCommon Crawlが収集した128億のサンプルで構成されたCommonPoolというデータセットが新しくリリースされました。
・関連記事
画像生成AI「Stable Diffusion」などの開発に大きな貢献を果たした超巨大データセット「LAION-5B」とは? - GIGAZINE
画像生成AI「Stable Diffusion」などに使われた50億枚超の画像セット「LAION-5B」に1008枚の児童ポルノ画像が入っていることが判明し削除へ - GIGAZINE
画像生成AI「Stable Diffusion」が使う無料のデータセット「LAION」の構築を率いているのは1人の高校教師だった - GIGAZINE
画像生成AIに自分の作品が勝手に使われたかどうかを検索できる「Have I Been Trained?」 - GIGAZINE
誰でも参加できるオープンソースの大規模言語処理モデル「Open Assistant」開発プロジェクトをLAION AIがスタート - GIGAZINE
・関連コンテンツ






in ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article 'Models All The Way Down' clearly shows ….