'Models All The Way Down' clearly shows the problems of the AI dataset 'LAION-5B' which takes '781 years' when checked properly

LAION-5B, a set of over 5 billion images and text, is used to train major image generation AIs such as Stable Diffusion. It is said that it would take 781 years for a full-time worker who works 5 days a week to visually check images one second at a time.The site ``Models All The Way Down'' has been released, which summarizes the huge size of the data set and its problems. .
Models All The Way Down

When you access the URL above and scroll, various images and associated text data appear and disappear in the background. This is a dataset included in LAION-5B.
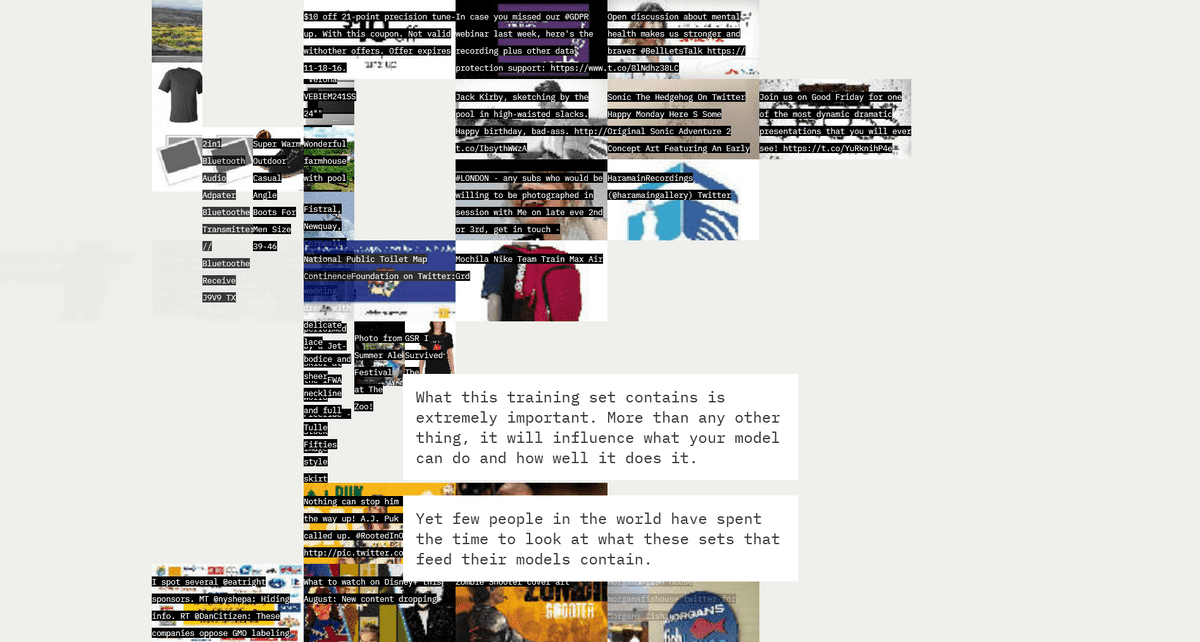
Although
It was found that 1008 child pornography images were included in the over 5 billion image set ``LAION-5B'' used for image generation AI ``Stable Diffusion'' etc. and will be deleted - GIGAZINE
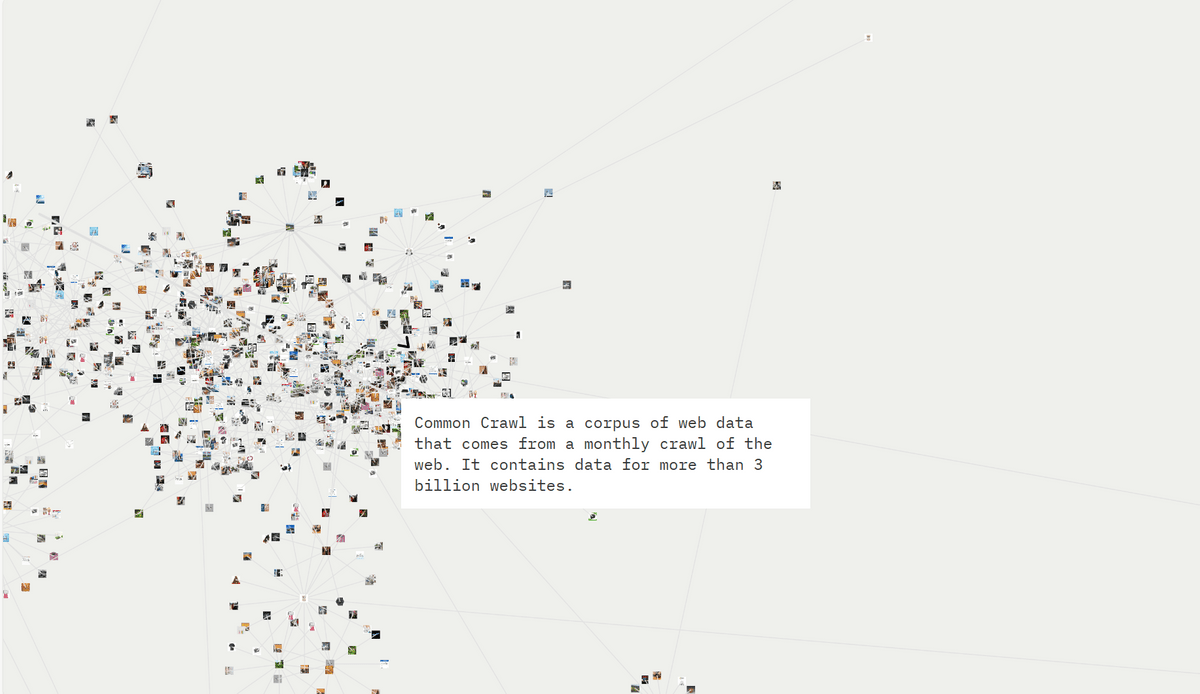
Scroll further to learn how LAION-5B was created. According to it, LAION-5B is built from an even larger dataset provided by Common Crawl, another nonprofit organization. Common Crawl crawls data from the Internet every month, including data from over 3 billion websites.
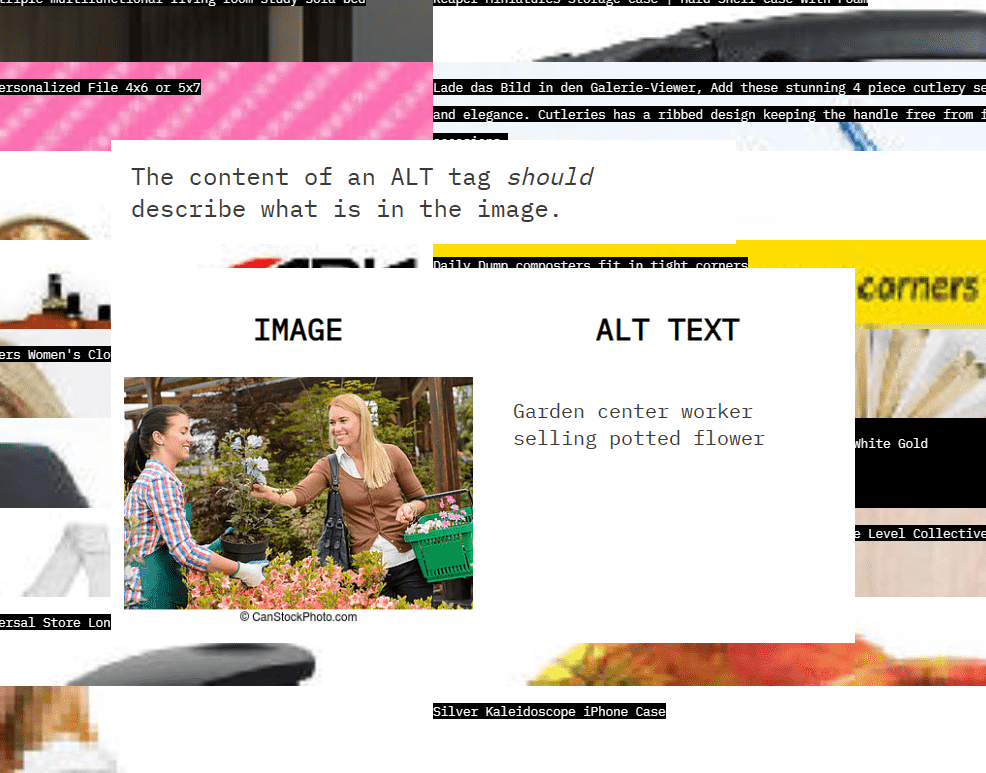
Typical sites where LAION-5B images come from include the photo sharing service Pinterest, the e-commerce platform Shopify, and the PowerPoint data sharing platform SlidePlayer. These sites are especially useful because many images are captioned with ALT attributes, which provide alternative text for the visually impaired.

Below is an example of an explanation using the ALT attribute. The photo shows two women buying and selling flowers, with the text ``Gardening Center Employee Selling Flowers.''
However, it is rare that they are used in the original way for visually impaired people, and many of the ALT attributes are currently used to attract algorithms rather than humans. For example, if a text like the one below is attached, such as 'Heart Shaped Sunnies - Chynna Dolls Swimwear,' you won't be able to tell what kind of photo it is even if you listen to it with a text-to-speech software. yeah.
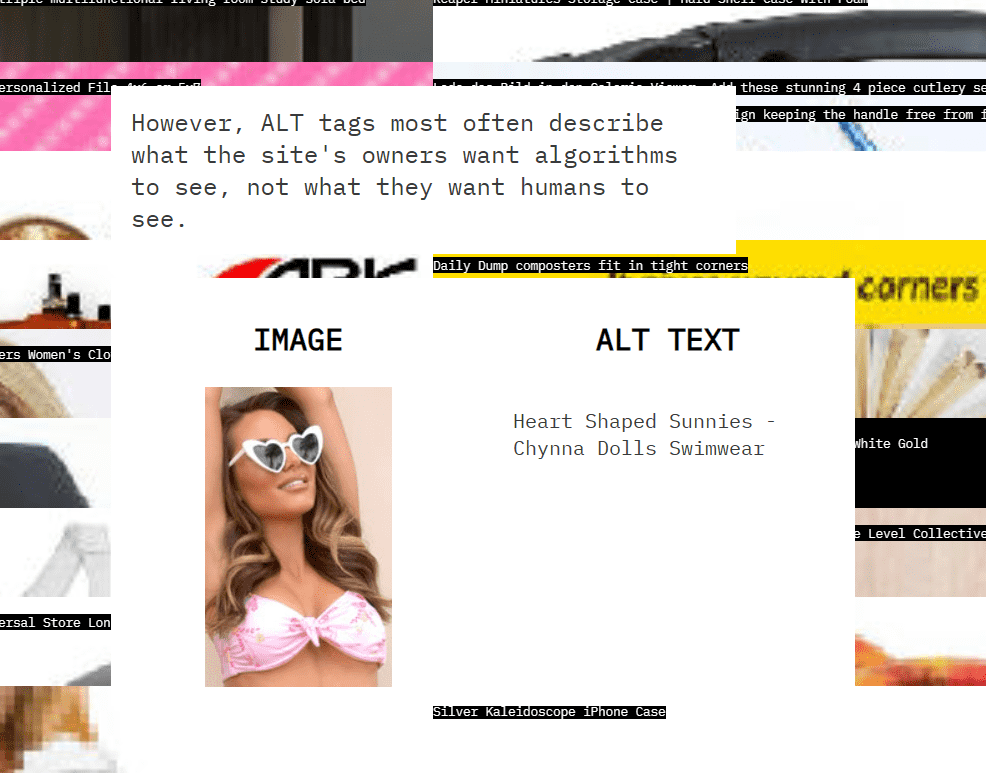
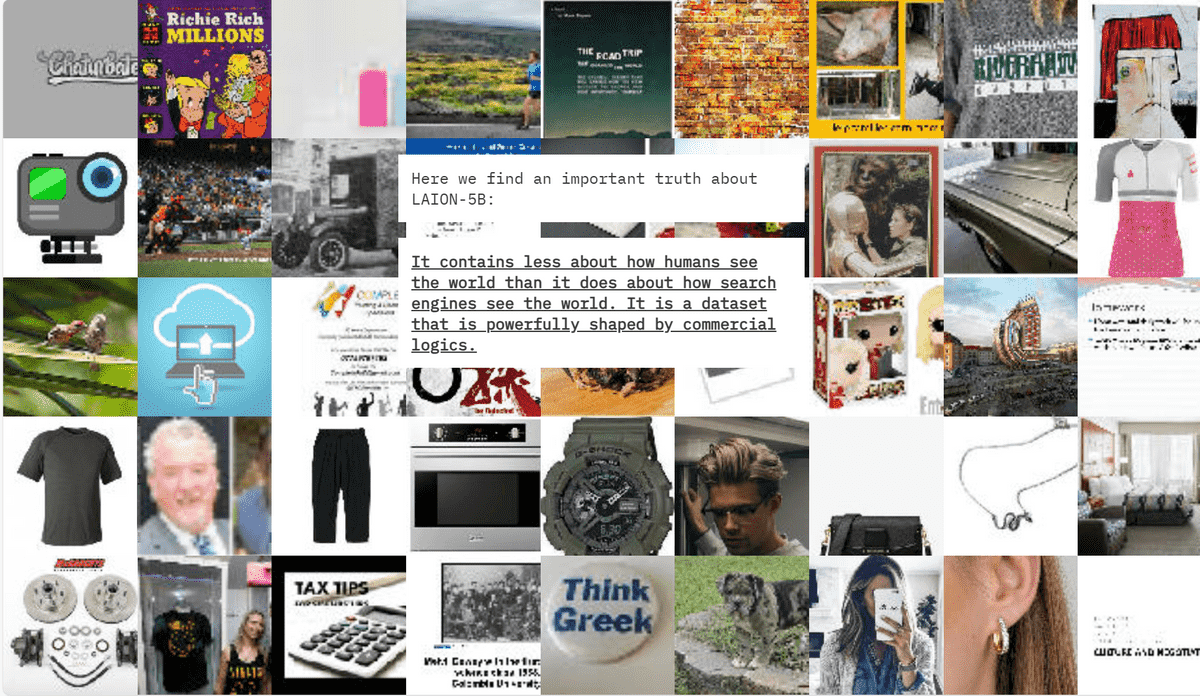
'The truth about LAION-5B is that there is more to how search engines see the world than how humans see the world,' Models All The Way Down complains.
In order to select a set of images and text captions whose ALT attribute text matches the image content, LAION-5B uses ``CLIP (Contrastive Language–Image Pre-training)'', a model developed by Open AI. , we obtained a score that indicates the similarity between the text string and the image.
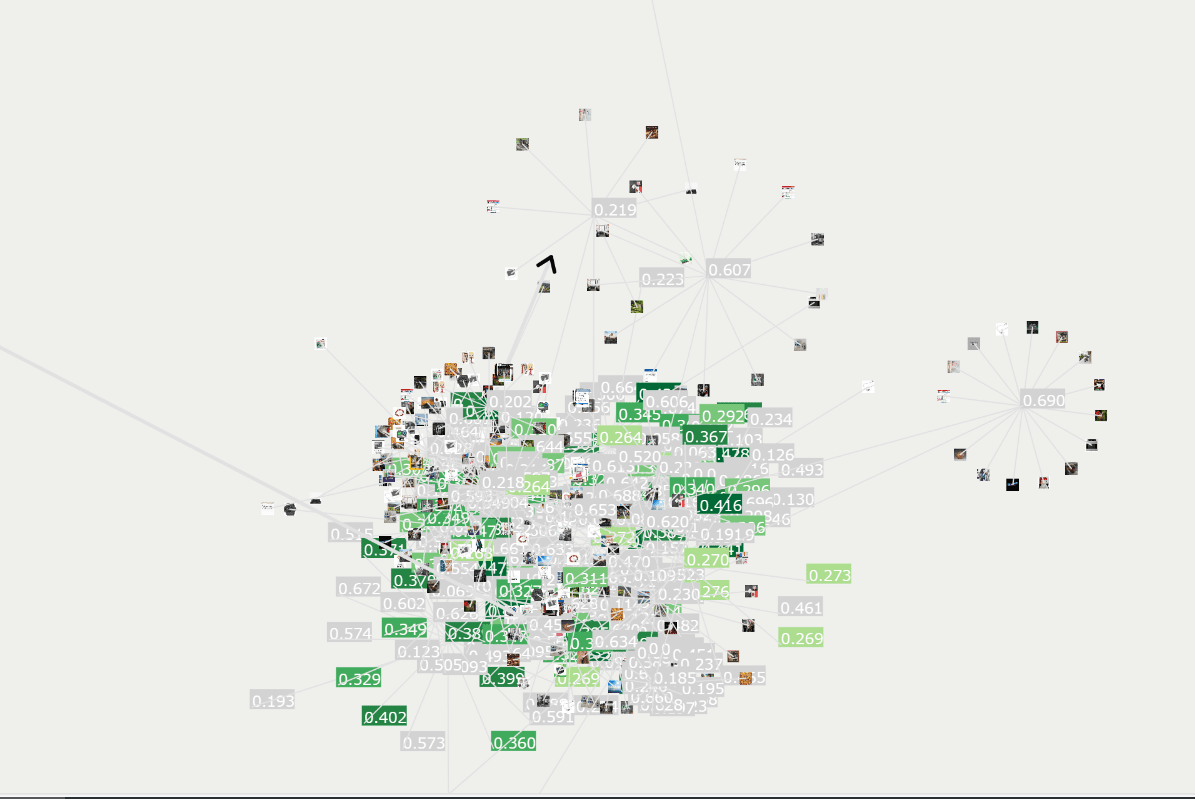
However, the scores of the selected images varied, with only 22,645 of the 5 billion images having a score of 0.5 or higher, and 16% of the total had a score of 0.1 or lower. Because of this accuracy drawback, if LAION researchers increased the similarity score tolerance by just 0.01, more than 900 million image and text sets would disappear from the dataset. .

This raises two important issues. First, algorithmic curation relies on scores, which ignores the content of images and text, and no one knows what the standards are for the images and text used in the dataset. is. Second, there is a cyclical nature in the process of creating datasets in which models are used to create models, and blind spots and biases that existed in a certain model or training set are endlessly transferred to a new model or dataset. This is something that will be inherited.

There is also a linguistic bias. As a premise, the LAION dataset is divided into three subsets: 'LAION-2B EN' linked to English, 'LAION-2B MULTI' for other languages, and 'LAION-1B NOLANG' for which the language could not be specified. I understand.
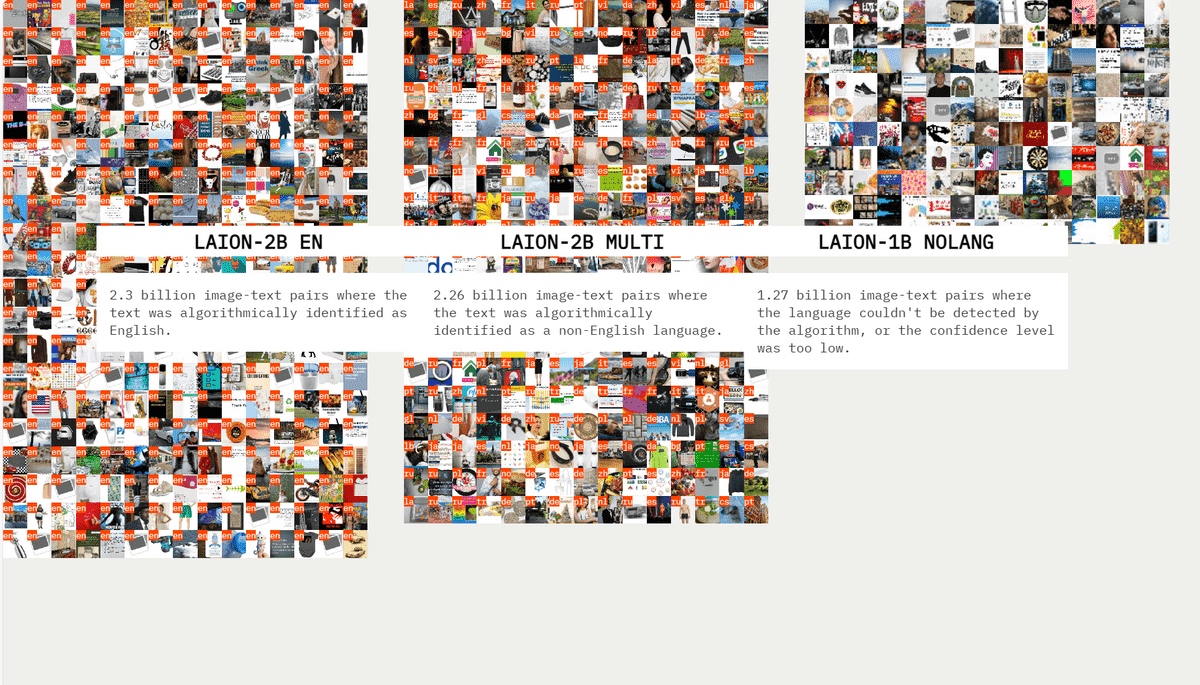
Russian is the most common language other than English, and there is one image caption labeled Russian in the dataset for each of the 255 million Russian speakers on the planet. Similarly, there is one image for every 2 French speakers and 1 image for every 35 Swahili speakers. On the other hand, there are 1.6 images per English speaker, 3 images per Dutch speaker, and 7 images per Icelandic speaker.
Additionally, LAION-5B has approximately 35 million text captions classified for Luxembourgish, which has only 300,000 speakers, while the original training set only has approximately 33,000 pages. That's not surprising; looking at the data set that was supposed to be Luxembourgish, most of the data were in English or another language. 'This is a stark example of how LAION's automatic processing can fail,' Models All The Way Down noted.

In addition to the language subset, LAION-5B also has a dataset called LAION-Aesthetics, which is a collection of high-quality images that were evaluated by a small number of people. This means that most of the ratings in the dataset were submitted by a handful of users, whose aesthetic preferences dominate the dataset. This raises the issue that 'the concept of what is visually appealing and what is not is driven by the preferences of a small number of individuals and the process by which dataset creators choose to curate their datasets.' The points will be highlighted.

In this way, although LAION-5B has various problems, it continues to be used for AI development with the proviso that it should not be used to create ready-to-use products, with the resolution of the problems postponed. Masu. What's more, we were able to identify this problem because LAION-5B was publicly available, but since the child pornography issue was discovered, new downloads are no longer available. The developers promise that they are 'working on fixing the issue,' but before that happens, a new dataset called CommonPool, made up of 12.8 billion samples collected by Common Crawl, has been released. I did.
Related Posts:







in Software, Posted by darkhorse_log