Cohere for AI releases open source large-scale language model “Aya” compatible with 101 languages

Most large-scale language models (LLMs) are primarily trained with English and Chinese data. Therefore, there is a problem in that the accuracy of sentence generation decreases for thousands of other languages. The LLM ' Aya ' released by Cohere for AI, a non-profit research organization of the start-up company Cohere, was developed in a project involving 3,000 researchers from 119 countries, and is more than twice as many languages as existing open source LLMs. It is said to cover.
Cohere For AI Launches Aya, an LLM Covering More Than 100 Languages
Aya | Cohere For AI
https://cohere.com/research/aya?ref=txt.cohere.com
Cohere for AI says, ``While LLM and AI are transforming the global technology landscape, many communities around the world remain unsupported by the language limitations of existing models. 'This could impede the applicability and usefulness of technology and widen existing disparities that already exist from previous waves of technological development.'
The dataset prepared by Cohere for AI includes machine translated data into over 100 languages. Half of those languages are languages that cannot be learned adequately using existing text datasets, such as Azerbaijani, Bemba, Welsh, and Gujarati.
Furthermore, for 67 languages, a dataset was created that attempts to capture cultural nuances and context with approximately 204,000 types of prompts and results annotated by fluent speakers.
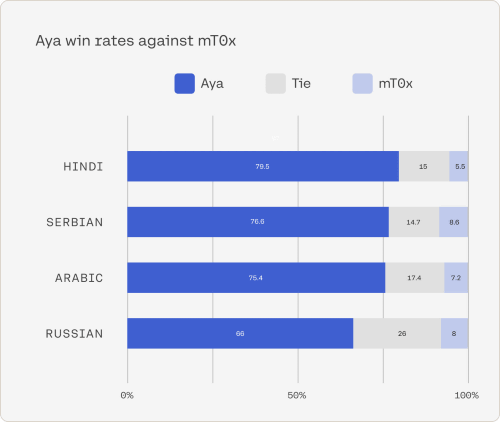
According to Cohere for AI, Aya significantly outperforms mt0 and bloomz in benchmark tests, consistently scoring 75% in human evaluation and 80-90% in simulation win rate against other leading open source models. It is said that he struck out. Below is a graph showing the winning percentage of performance comparison between Aya (blue) and mt0 (light blue) in Hindu, Serbian, Arabic, and Russian. Gray means a tie with equal performance.
Furthermore, Cohere for AI claims that Aya covers more than 50 languages that were not previously supported by other LLMs, such as Somali and Uzbek.
Sarah Hooker, vice president of research at Cohere and leader of Cohere for AI, told tech news site Venture Beat : ``When we started, we had no idea how big the project would become. , the dataset was ultimately annotated with fine-tuned over 513 million prompts.'
Aya's models are hosted in the Hugging Face repository under the Apache License 2.0 .
CohereForAI/aya-101 · Hugging Face
https://huggingface.co/CohereForAI/aya-101
In addition, a dataset containing 513 million types of prompts in 114 languages is also published in the Hugging Face repository below under Apache License 2.0.
CohereForAI/aya_dataset · Datasets at Hugging Face
https://huggingface.co/datasets/CohereForAI/aya_dataset
Related Posts:







in Software, Posted by log1i_yk