Commercially available large-scale language model 'Swallow' with excellent Japanese ability will be released

A research team from Tokyo Institute of Technology (Tokyo Institute of Technology) and National Institute of Advanced Industrial Science and Technology (AIST) has released a large-scale language model ' Swallow ' that is strong in Japanese. It is provided under the LLAMA 2 Community License, and commercial use is possible if the monthly active users are less than 700 million.
Swallow

Release of 'Swallow', a large-scale language model that is good at Japanese. Teaching Japanese to a large-scale language model that is good at English | Tokyo Tech News | Tokyo Institute of Technology
https://www.titech.ac.jp/news/2023/068089
A research team from Tokyo Tech and AIST has expanded its Japanese language capabilities based on Meta's Llama 2, a large-scale language model with high language comprehension and conversational ability in English. Llama 2 also supports Japanese, but 90% of Llama 2's pre-learning data is in English, and the proportion of Japanese data is about 0.1% of the total. As a result, although Llama 2 demonstrated high performance in English, it was not good at reading and writing Japanese.
In addition, in Llama 2, text is tokenized using an algorithm called ``byte pair encoding'' that finds the optimal vocabulary within the specified vocabulary based on the statistical information of characters and strings of language data. However, because the amount of Japanese in the original language data was small, major Japanese words and characters were not included, and the text was tokenized in unnatural units.
The research team added 16,000 vocabulary items such as Japanese characters and words to the language model, created new Japanese data to be used for training, and continued preliminary training to improve Llama 2's advanced language processing. He said that he succeeded in strengthening his Japanese language ability while maintaining his Japanese ability. The increased vocabulary allows Japanese text to be expressed with fewer tokens, which has benefits such as reducing computational costs for training and text generation, and increasing the upper limit on the amount of text that can be handled during input/output. is occurring.
The three models released this time are the 'Swallow 7B' model with 7 billion parameters, the 'Swallow 13B' model with 13 billion parameters, and the 'Swallow 70B' model with 70 billion parameters. We have improved the scores of the Llama 2 model on which it is based on the average of benchmarks that test various Japanese language proficiency.
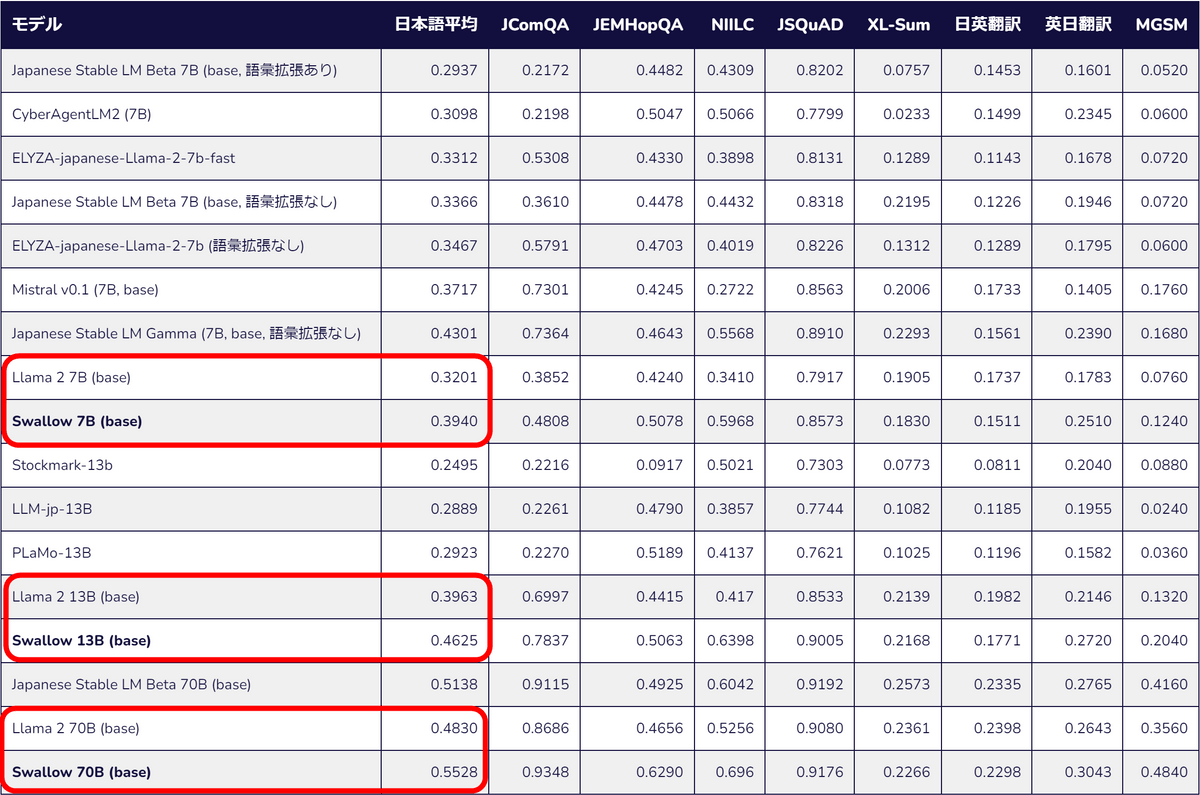
Each model is hosted on Hugging Face and is available under the LLAMA 2 Community License for commercial use.
Additionally, an explanation by Kazuki Fujii, one of the project members, has been published on Zenn, an information sharing community for engineers. If you are interested, please check it out.
Related Posts:







in Software, Posted by log1d_ts