A large-scale language model 'Mistral 7B' that can be used and verified with a truly open source license has appeared, making it possible to develop AI with performance exceeding 'Llama 2 13B' and 'Llama 1 34B'

Mistral 7B , a large-scale language model developed by French AI startup Mistral AI, was released in September 2023. The model weights are released under
Mistral 7B | Mistral AI | Open source models
https://mistral.ai/news/announcing-mistral-7b/
Mistral 7B is a model with 7.3 billion parameters, and its features are as follows.
- Outperforms Llama 2 13B in all benchmarks
- Outperforms Llama 1 34B in many benchmarks
-Performs close to CodeLlama 7B on coding tasks while remaining excellent on English tasks
・Use Grouped-Query Attendance (GQA) to speed up inference
・Use Sliding Window Attention (SWA) to process long sequences at low cost
The Mistral 7B model is released under the Apache 2.0 license, so you can freely modify and adjust it for commercial use. A reference implementation is available on GitHub , documentation on how to deploy to cloud services using Skypilot is available, and a model is also available on Hugging Face .
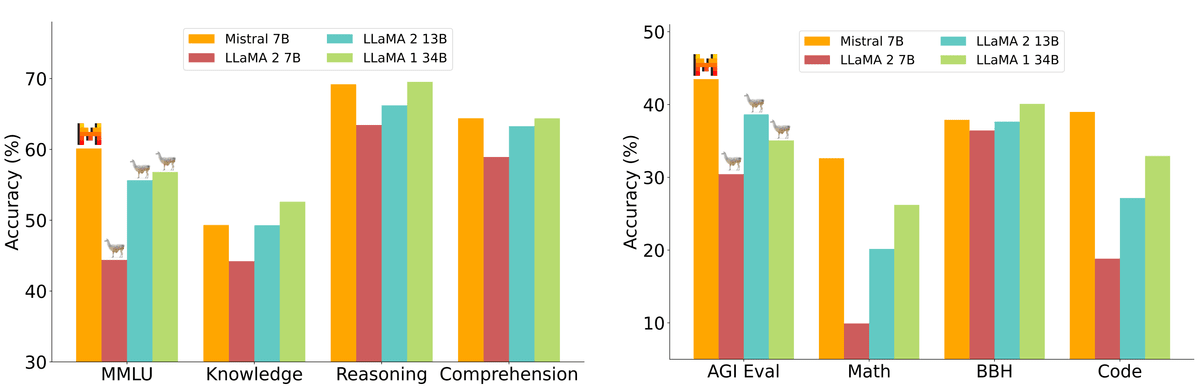
The results of comparing the performance in various benchmarks using the four models 'Mistral 7B', 'LLaMA 2 7B', 'LLaMA 2 13B', and 'LLaMA 1 34B' are shown in the figure below. Despite having a significantly smaller number of parameters, Mistral 7B outperforms LLaMA 2 13B on all benchmarks and performs on par with LLaMA 1 34B.
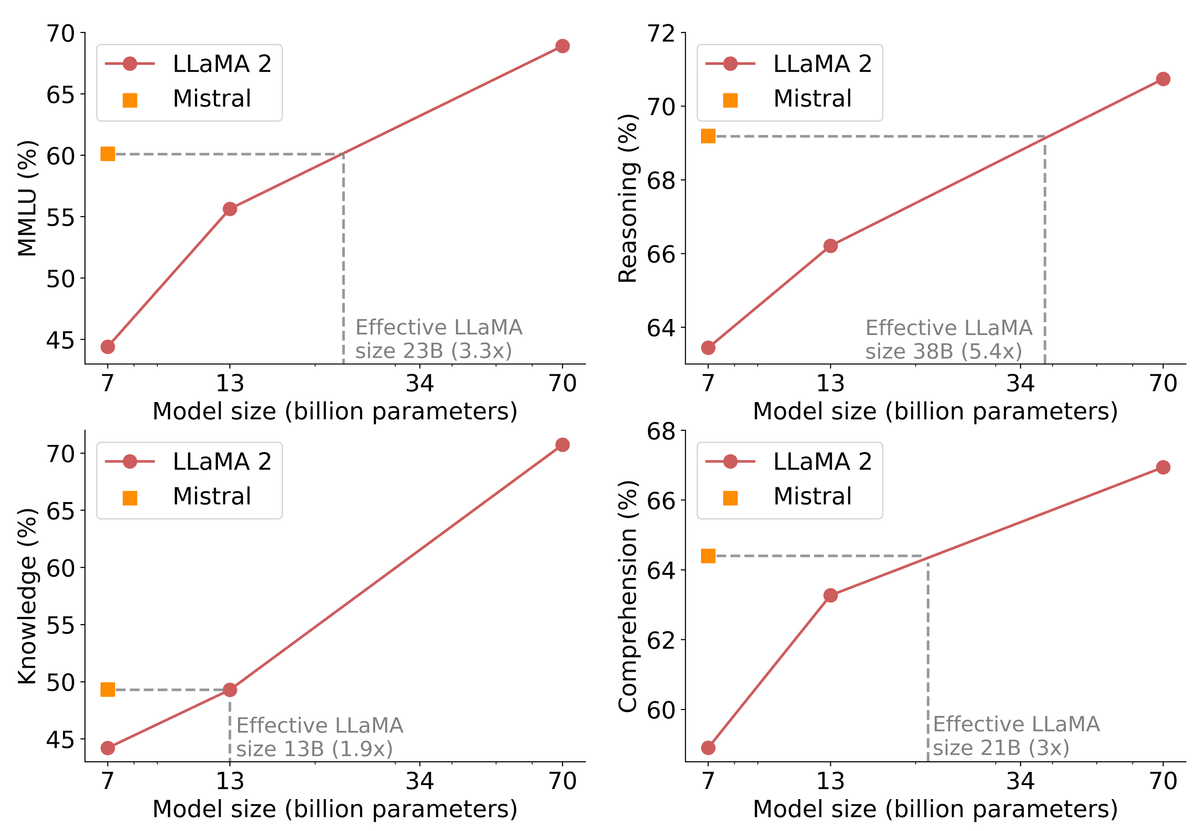
In addition to MMLU, which measures multitasking performance, the figure below shows the results of estimating how many parameters are required for LLaMA 2 to achieve the same performance as Mistral 7B in the areas of reasoning, knowledge, and reading comprehension. It is summarized in For example, in MMLU, Mistral can achieve the same performance as LLaMA 2 with 23 billion parameters with 7.3 billion parameters, and can significantly reduce costs such as memory usage and inference time.
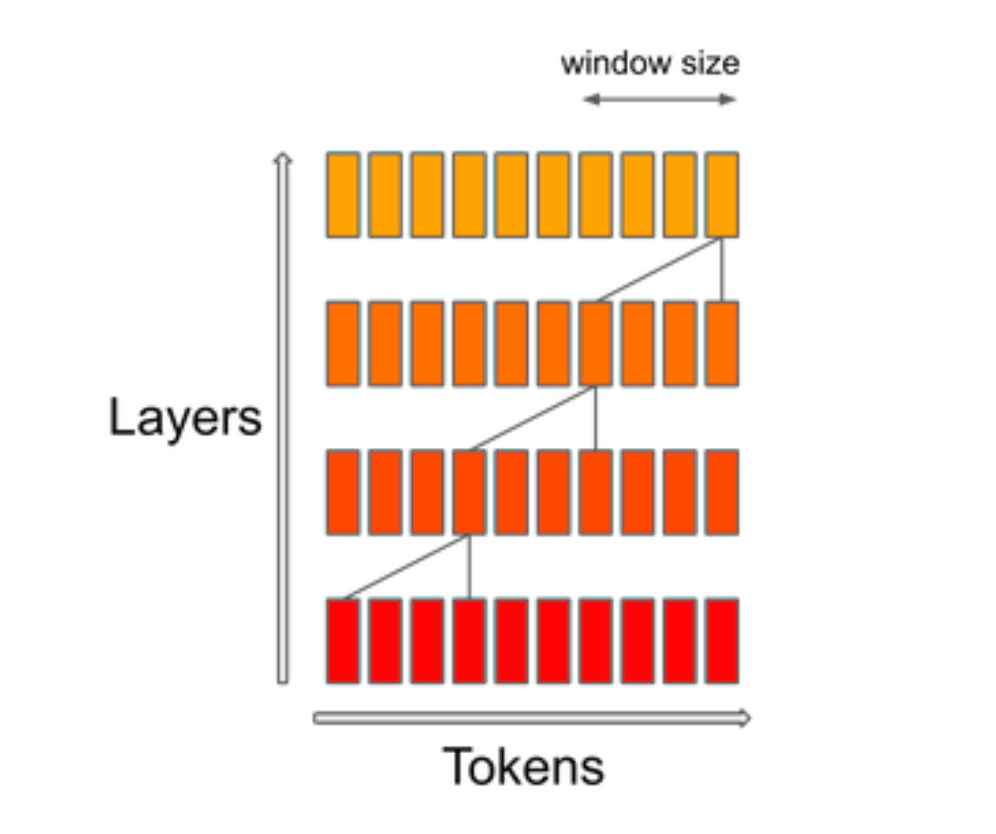
Mistral 7B uses a technique called Sliding Window Attention (SWA). This is a method that calculates only a certain range instead of calculating all combinations between tokens when calculating attention, and can significantly reduce memory usage and calculation time compared to traditional attention mechanisms.
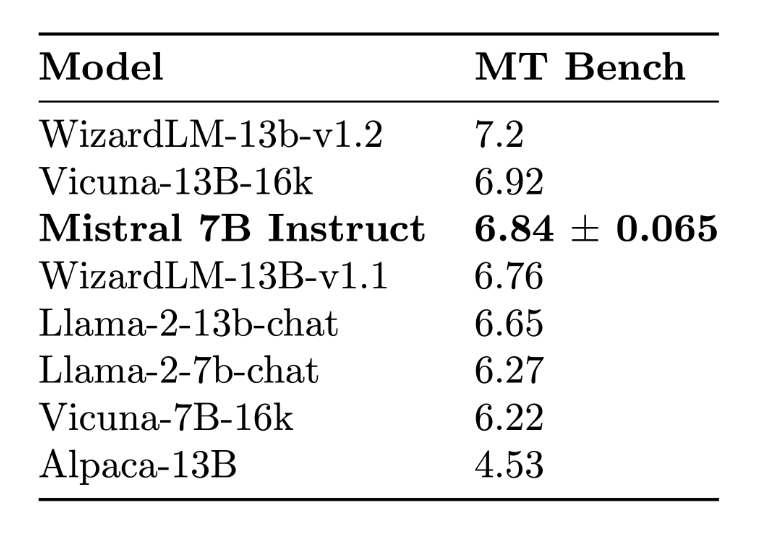
Mistral 7B can be made to correspond to various tasks using fine tuning, and Mistral AI is an example of
In addition, Mistral AI, which released Mistral 7B, is already training the next model, and a large-scale language model that is larger, has higher inference performance, and supports multiple languages is scheduled to be released soon. .
Related Posts:







in Software, Posted by log1d_ts