Meta releases next-generation open LLM 'Llama 3,' the best-ever performance model available for free commercial use

Meta has released the next-generation large-scale language model of the Llama family, ' Llama 3 '. In addition to research purposes, it is available for commercial use free of charge for those with less than 700 million monthly active users.
Meta Llama 3
Introducing Meta Llama 3: The most capable openly available LLM to date
https://ai.meta.com/blog/meta-llama-3/
The two models released this time are 8 billion (8B) and 70 billion (70B) parameters. Both are 'Instruct' models that have been pre-trained and fine-tuned for command following, and can handle tasks as a chat AI.
The results of the comparison with models with equivalent parameters are shown in the figure below. Among open models, it has the highest scores in most indicators. By improving the post-training procedure, it has reduced the false rejection rate and improved response diversity, and it is said that functions such as inference, code generation, and instruction have been greatly improved.
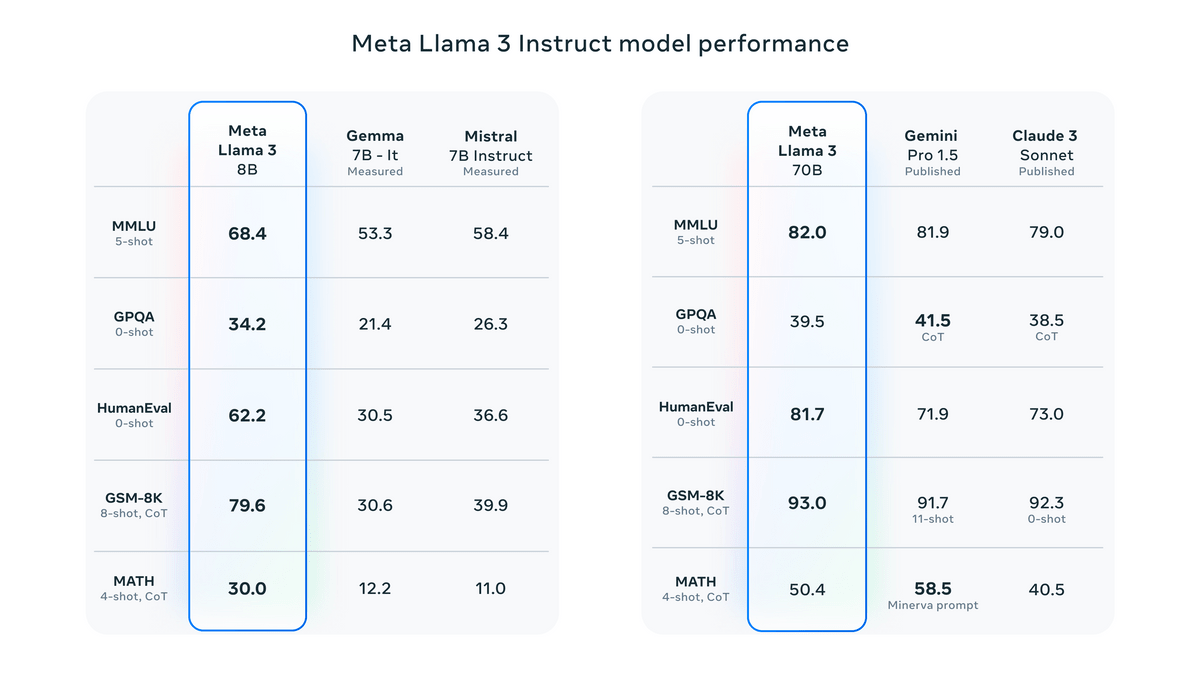
In addition to standard benchmarks, Llama 3 also seeks to optimize performance for real-world usage scenarios by introducing a new high-quality human evaluation set, which includes 1,800 prompts across 12 key use cases, with human reviewers evaluating responses to each prompt.
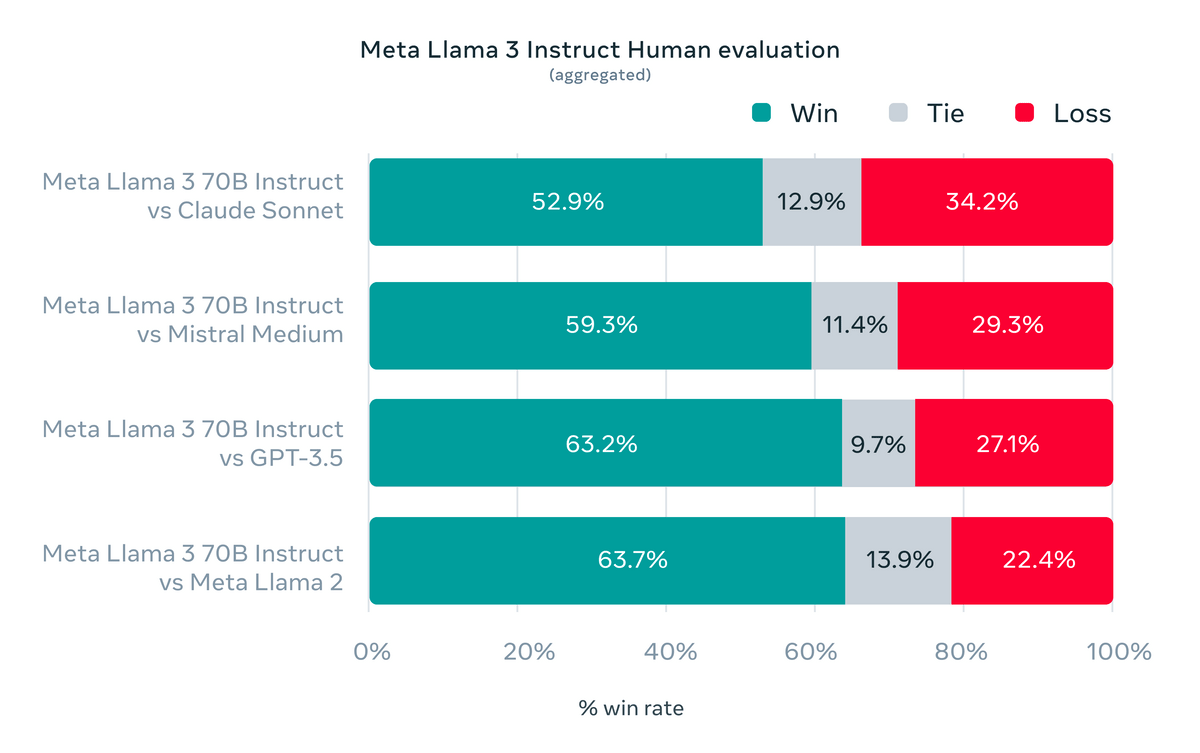
The output of other models for the same prompt and the results of a human evaluation of 'which answer was better' are shown in the figure below. In addition to being rated higher than Claude Sonnet, Mistral Medium, and GPT-3.5, we can see that the answers are much improved compared to the previous model, Llama 2.
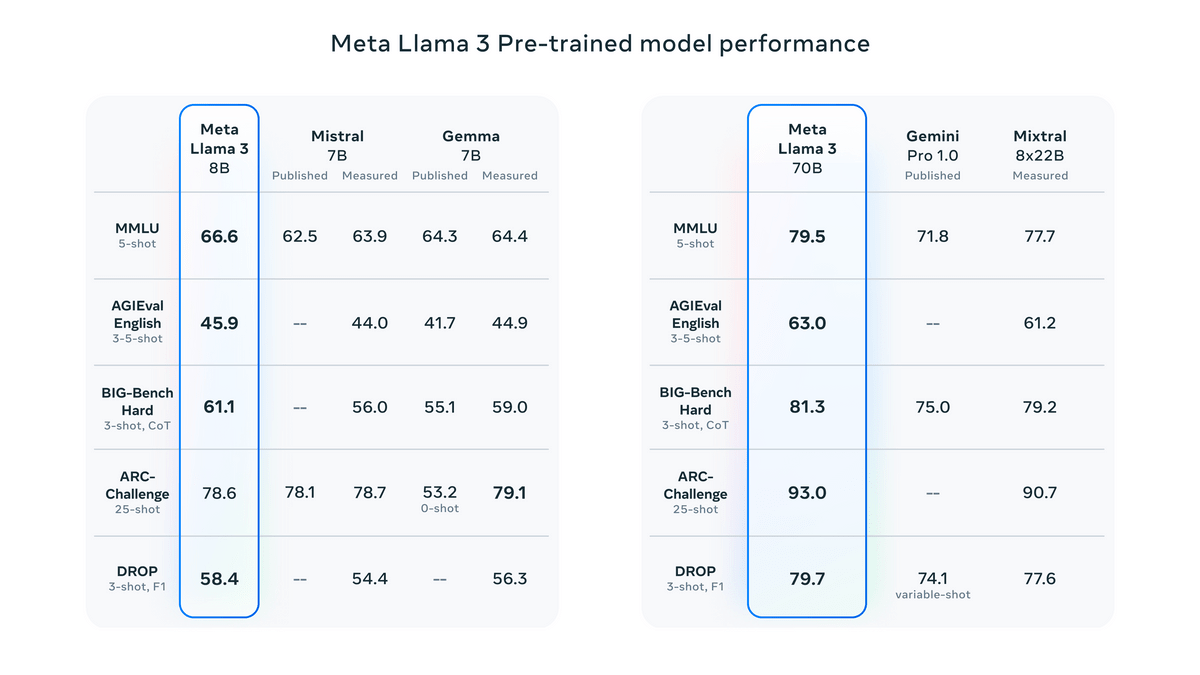
The performance comparison for a pre-trained model that has not undergone fine tuning is shown in the figure below.
In developing Llama 3, Meta focused on four elements: model architecture, pre-training data, scaling up pre-training, and fine-tuning instructions.
Llama 3 uses a relatively standard decoder-only transformer architecture as its model architecture. Compared to Llama 2, the token vocabulary has been increased to 128,000 tokens, allowing language to be encoded more efficiently and significantly improving performance. In addition, to improve the inference efficiency of Llama 3, it is said that grouped querier attention (GQA) was adopted and the model was trained on a sequence of 8192 tokens.
A total of more than 15 trillion tokens of data collected from public sources have been used to train Llama 3. This training dataset is seven times larger and contains four times more code than that used in Llama 2. To prepare for future multilingual use cases, 5% of this dataset contains non-English data across more than 30 languages, but the same performance as for English cannot be expected.
In addition, Meta developed a data filtering pipeline to improve the quality of training data using heuristic filters, NSFW filters, semantic deduplication approaches, text classifiers, etc. Through extensive experimentation, they investigated how to appropriately mix a large number of data sets and selected a data mix that ensures Llama 3 works well in a variety of use cases, including science, coding, and history.
During the development of Llama 3, Meta also investigated the impact of the scale of training data on quality. For both the 8B and 70B models, performance improved logarithmically linearly even after training with 15 trillion tokens. To handle such large amounts of training, Meta parallelized three of its data-model pipelines, achieving a compute utilization of 400 TFLOPS per GPU even when training simultaneously on 16,000 GPUs. In addition, a newly developed training stack that automates GPU error detection, handling, and maintenance has reduced effective training time by more than 95%, and overall, the training efficiency of Llama 3 is about three times that of Llama 2.
After this pre-training, Llama 3 has been tuned for command following by combining 'supervised fine tuning (SFT)', 'rejection sampling', 'proximity policy optimization (PPO)' and 'direct policy optimization (DPO)'. When encountering a question that is difficult to answer, the model was in a state where it 'knew how to generate the correct answer but did not know how to select that method', so by learning priority ranking via PPO and DPO, it became possible to appropriately select how to generate the answer, significantly improving the performance of inference and coding tasks.
Meta also envisions Llama models as 'part of a broader system in which developers sit in the driver's seat', and takes a new systems-level approach to improving model safety.
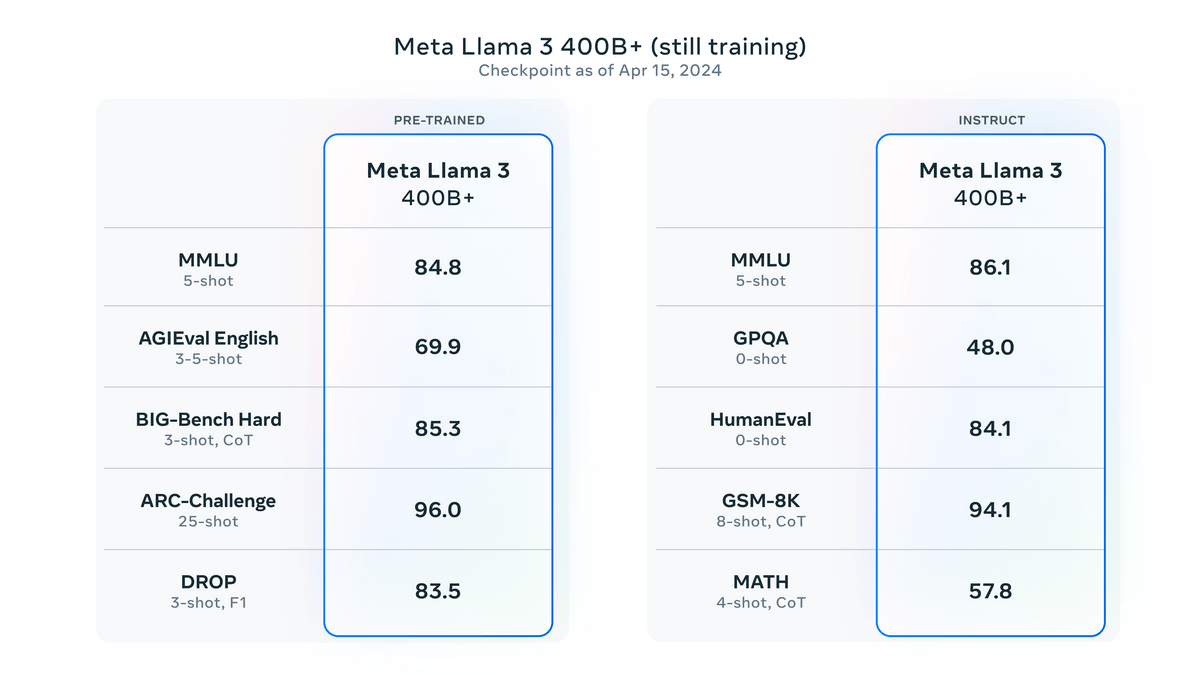
In addition to the two models, 'Llama 3 8B' and 'Llama 3 70B', Llama 3 will have many more models in the future. The largest model has 400 billion parameters (400B) and is currently being trained. The benchmark results for the 400B model as of April 15, 2024 are shown below.
Over the coming months, the company will release models with new features, such as the ability to converse in multiple languages and with multimodal language, larger context windows, and stronger overall capabilities. It also said it will publish a detailed research paper once Llama 3 training is complete.
At the same time as the release of Llama 3, '
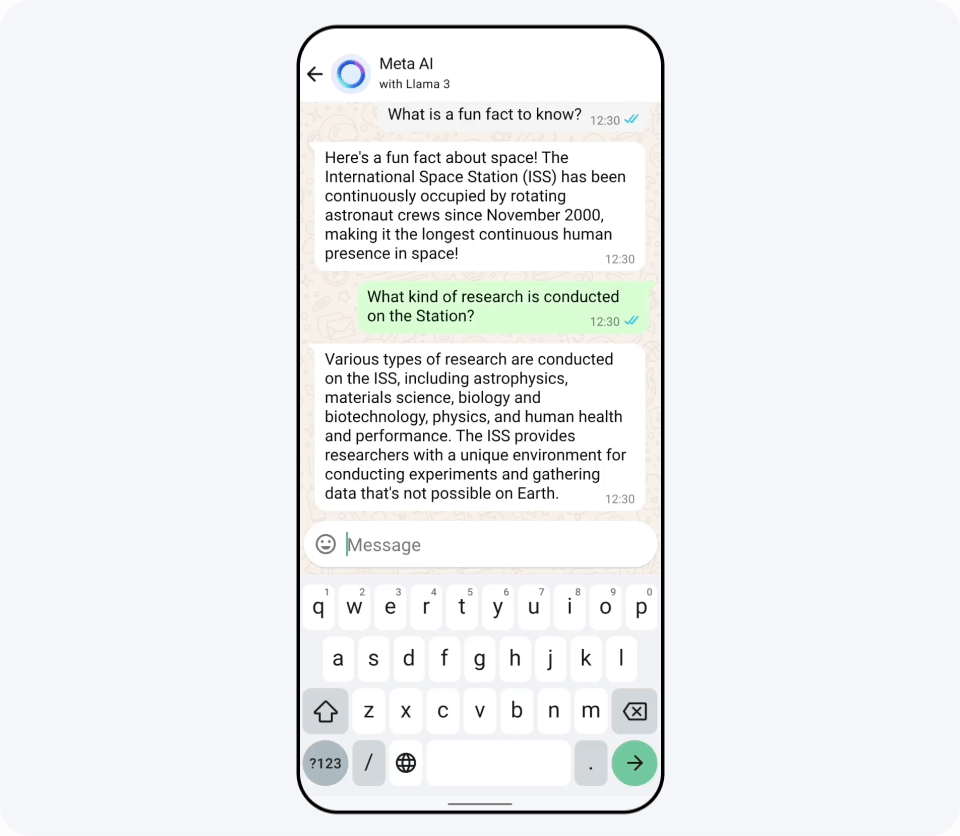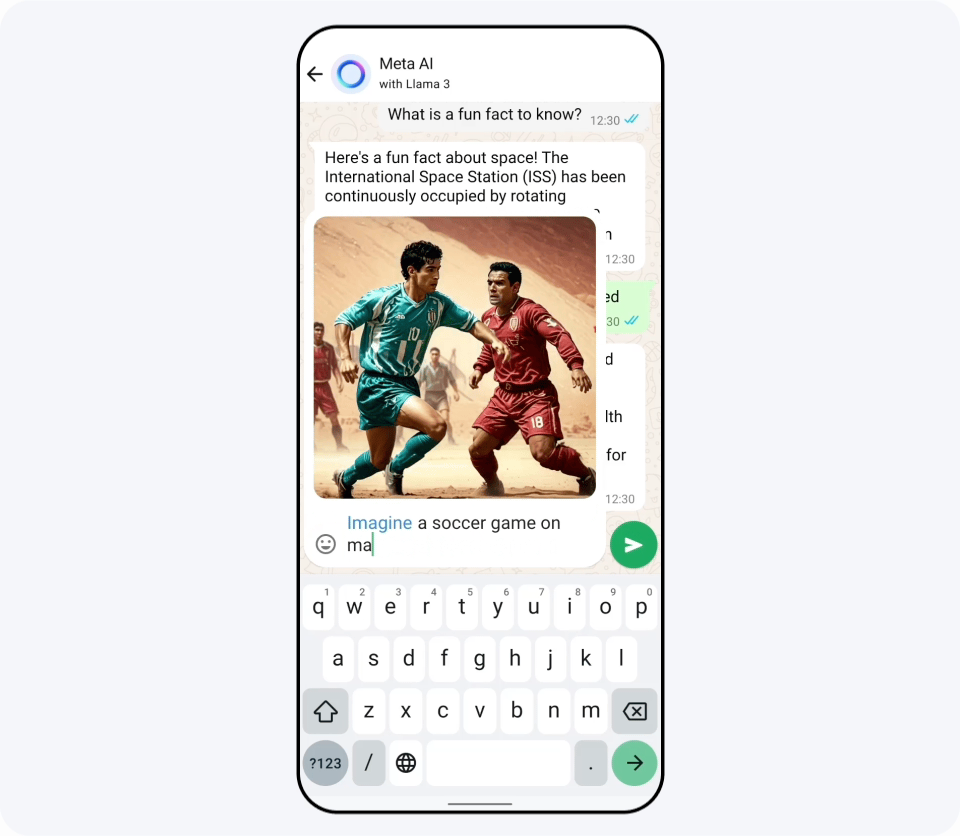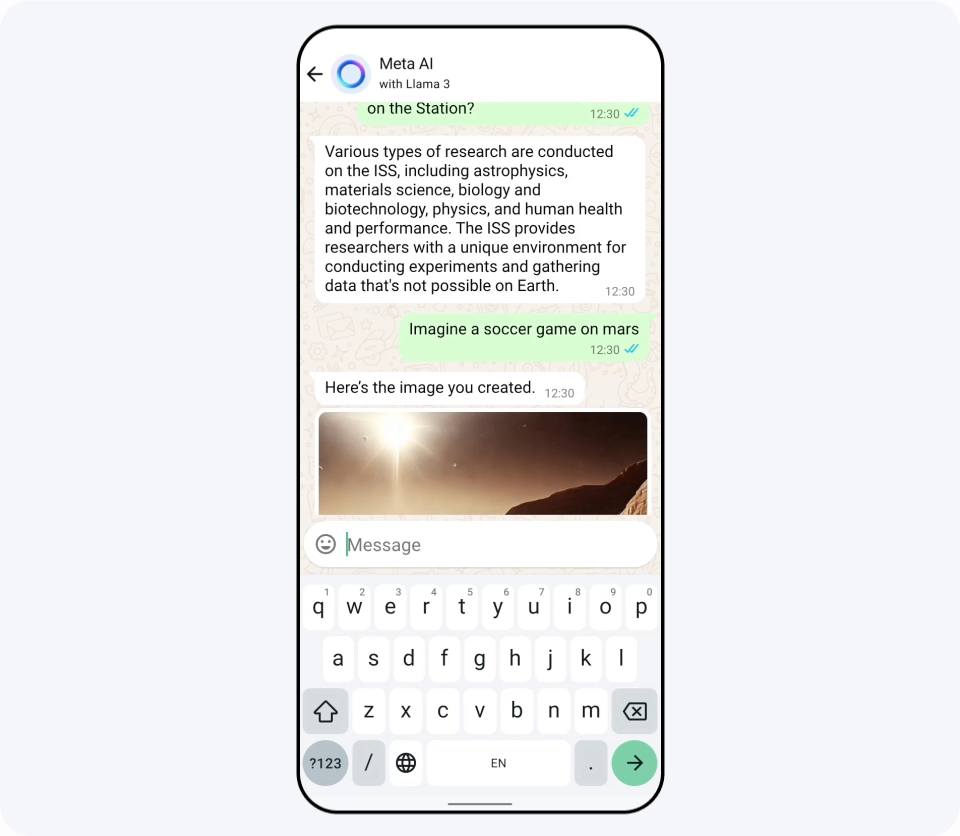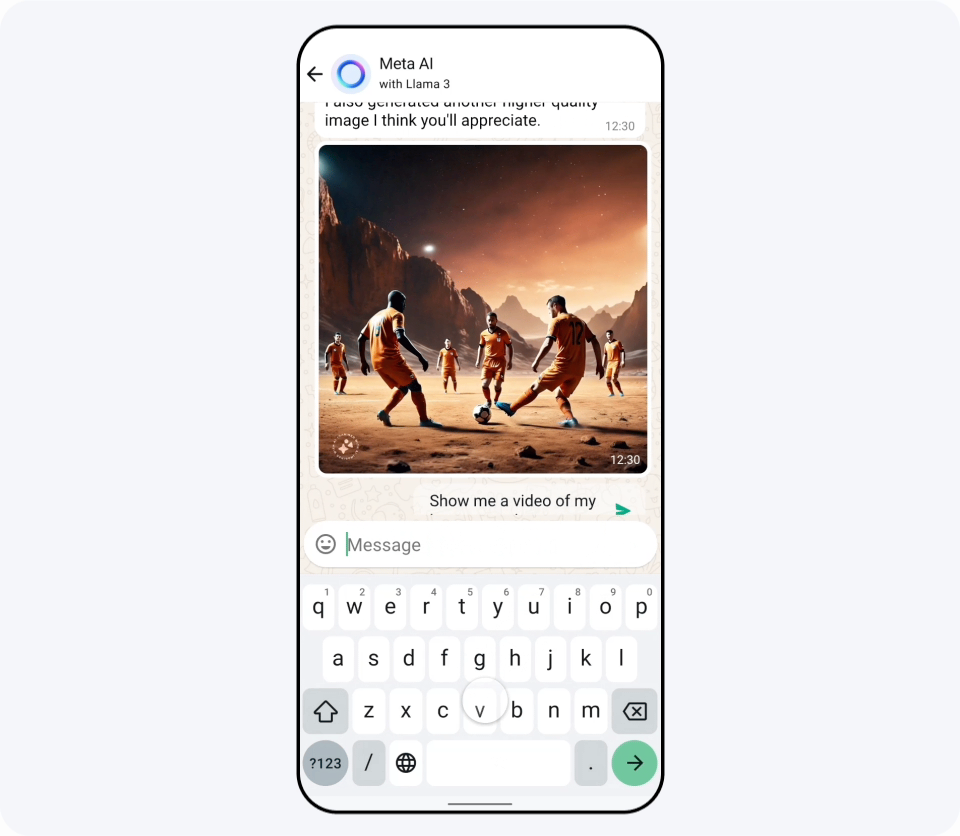
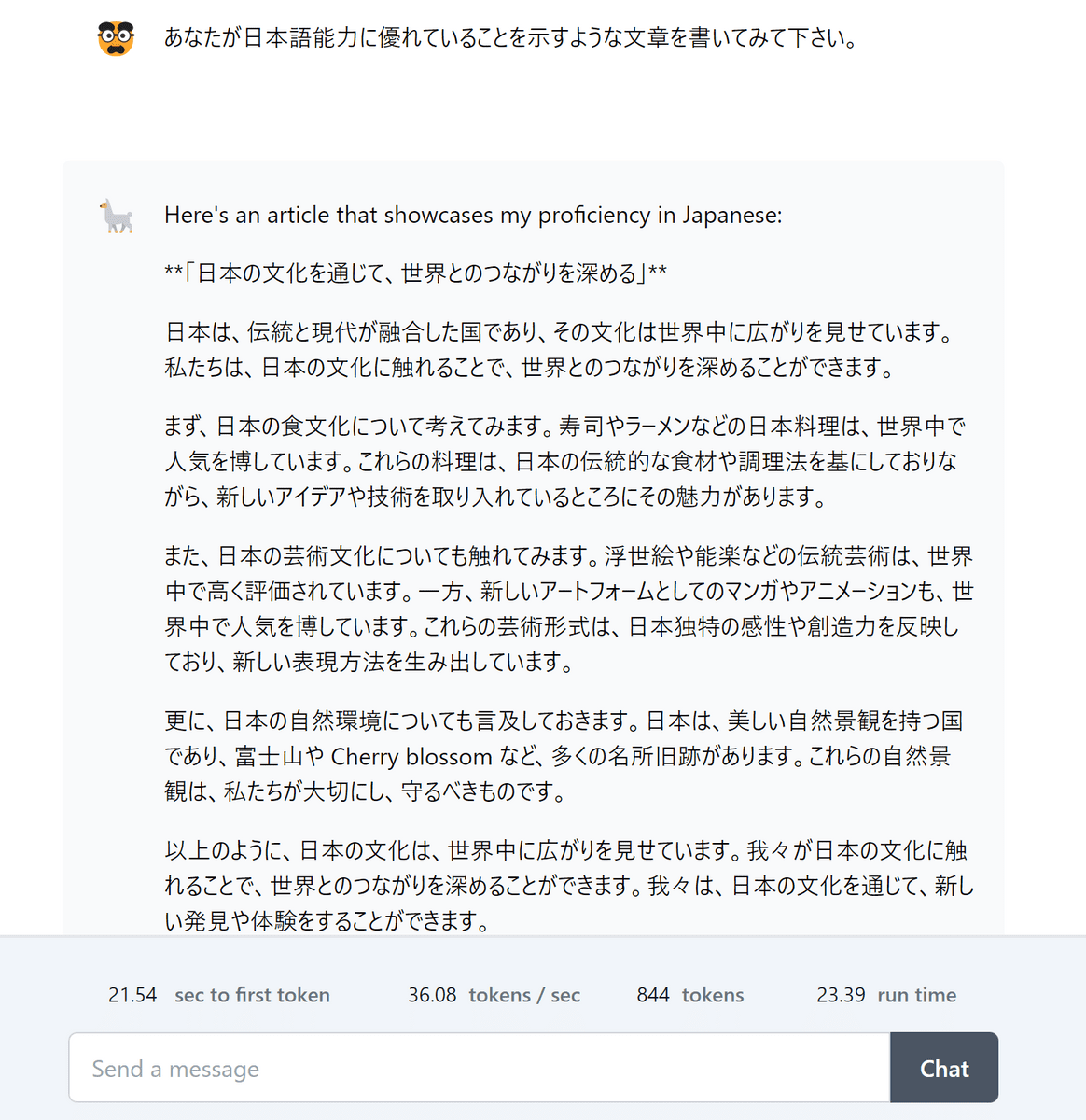
You can try out Llama 3 on Replicate , and it has already been announced that it has been introduced on Nvidia's NIM and Cloudflare's Workers AI . When I asked Replicate about Japanese language capabilities, I got the following response. Although it is officially stated that 'the performance is not as good as English,' it seems possible to use it in Japanese.
◆ Forum is currently open
A forum related to this article has been set up on the official GIGAZINE Discord server . Anyone can post freely, so please feel free to comment! If you do not have a Discord account, please refer to the account creation procedure article to create an account!
• Discord | 'Have you used Llama 3 yet? How was the performance?' | GIGAZINE
https://discord.com/channels/1037961069903216680/1230808401529798666
Related Posts:







in Software, Posted by log1d_ts