Meta releases lightweight quantized Llama model that runs on mobile devices

Meta has released the first lightweight quantized model in its large-scale language model family, Llama 3.2, which has significantly improved inference speed and memory usage while maintaining most of the existing performance.
Introducing quantized Llama models with increased speed and a memory reduced footprint

Meta released the Llama 3.2 family on September 26, 2024. In addition to the larger models 11B and 90B, smaller models for mobile devices, 1B and 3B, were also available.
Meta releases 'Llama 3.2', with improved image recognition performance and a smaller version for smartphones - GIGAZINE

This time, Meta quantized the Llama 3.2 1B and 3B models from 4 bits to 8 bits for each part. After performing quantization-aware training (QAT) that takes into account the effects of quantization during training, they applied the LoRA adapter to perform supervised fine tuning, a technique called 'QLoRA,' which succeeded in reducing the weight of the model while maintaining almost all of its performance.
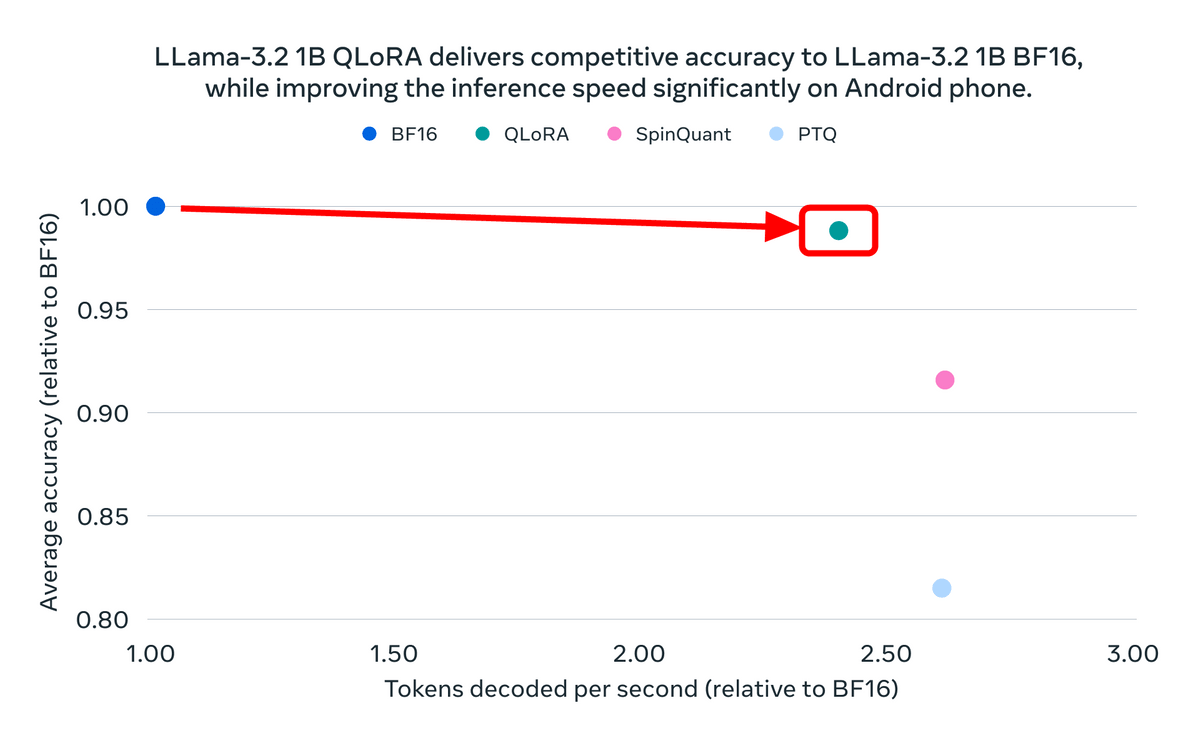
The figure below compares the accuracy and token decoding speed of the 1B model of Llama 3.2, with the original pre-quantization model 'BF16' set as 1. We can see that QLoRA has increased the decoding speed by about 2.5 times while slightly decreasing the accuracy. We can also see that other methods, SpinQuant and PTQ, have achieved speeds faster than QLoRA, but at the expense of reduced accuracy.
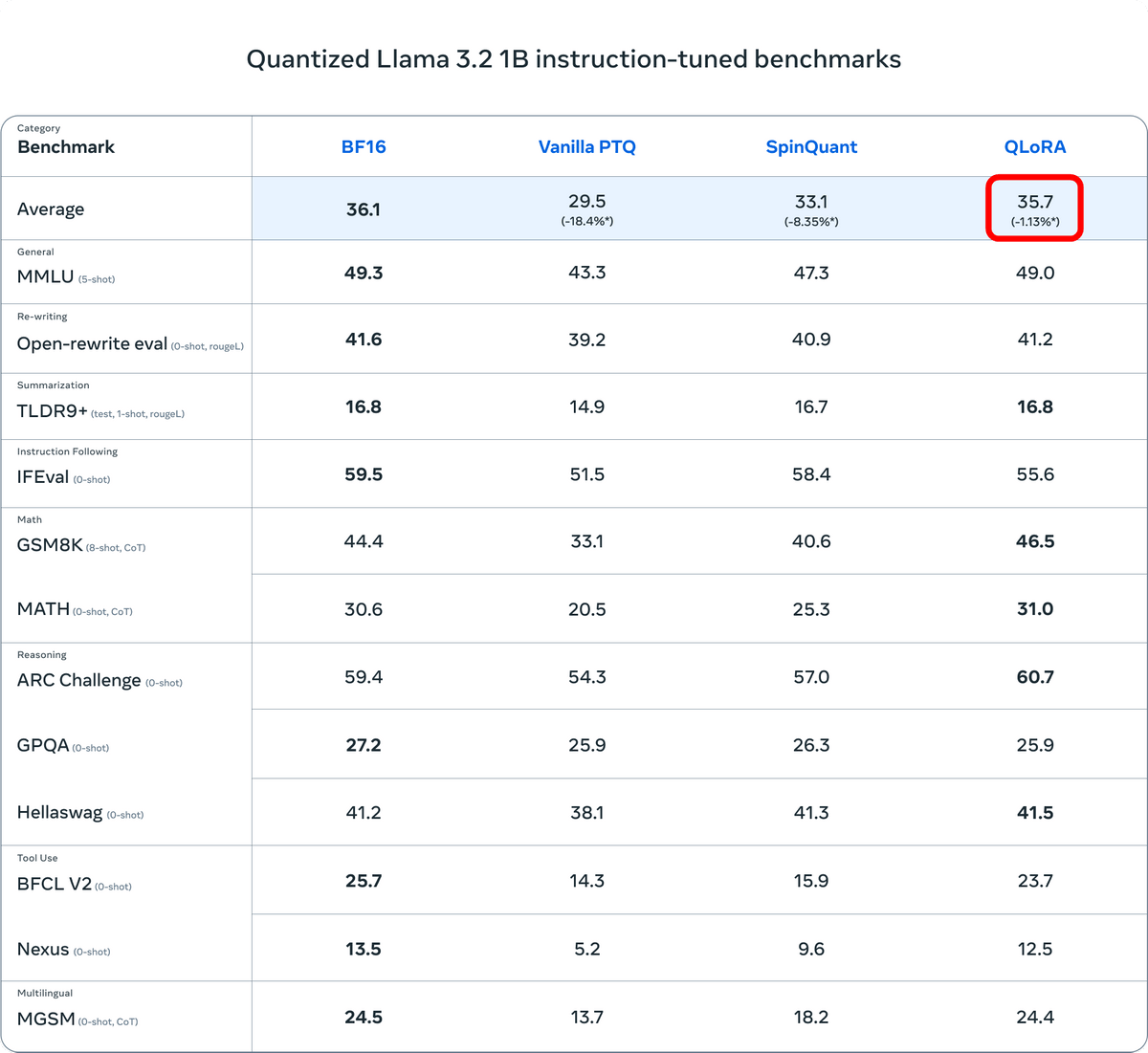
The specific benchmark values are as shown in the figure below. Looking at the average score, QLoRA was 1.13% lower than BF16.
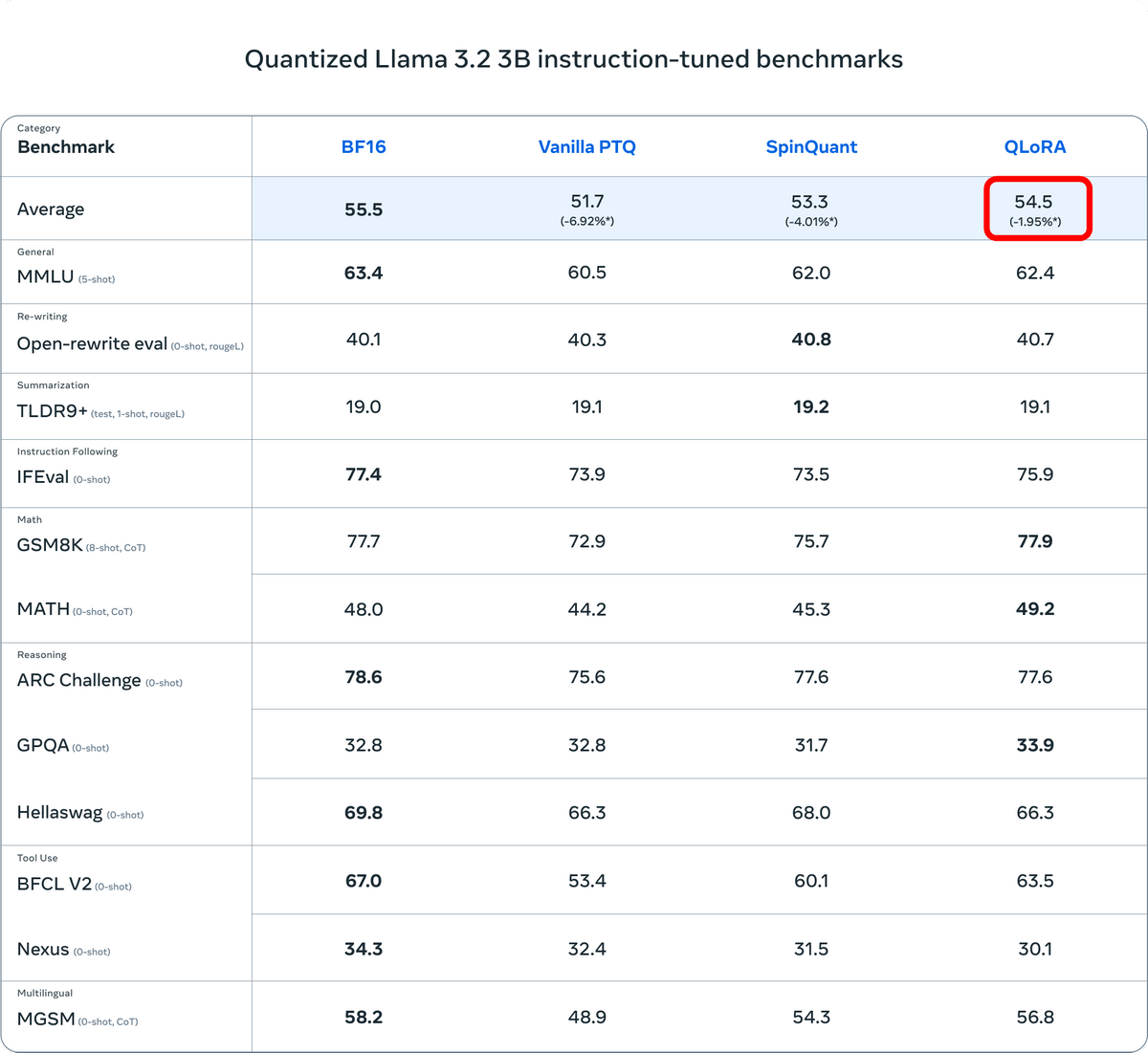
Even on the 3B model of Llama 3.2, QLoRA experienced a 1.95% performance degradation compared to BF16.
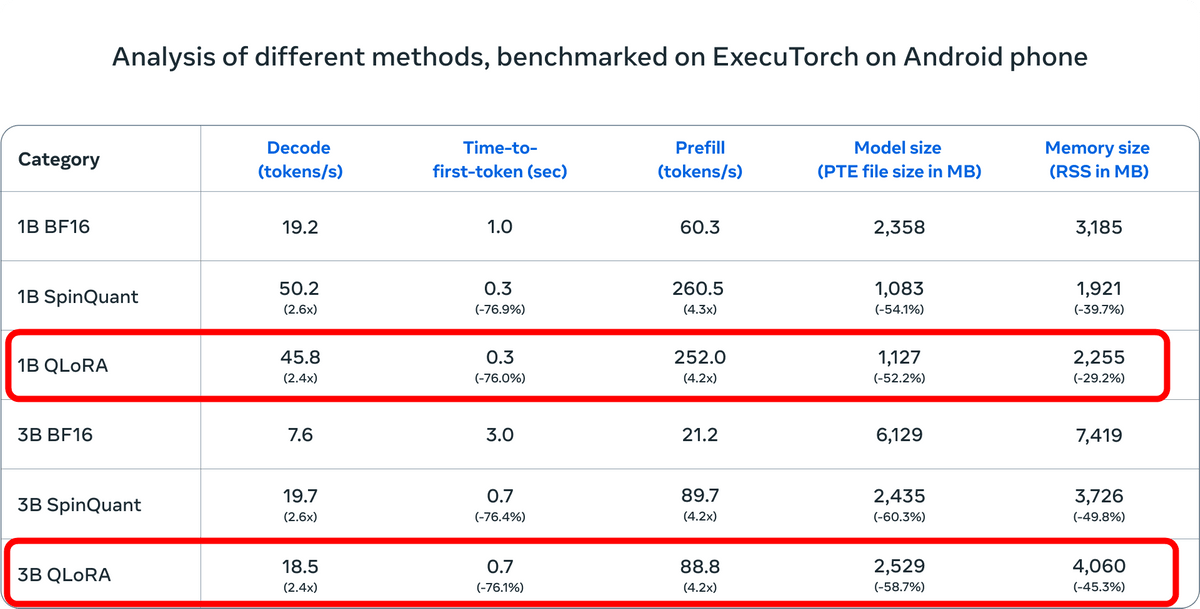
On the other hand, the token decoding speed increased by 2.4 times for both models, and the time it took to generate the first token decreased by 76%. When using Prefill, which processes input tokens in parallel, the speed increased by 4.2 times and the model size was reduced by more than half. The amount of memory used during inference decreased by about 30% for the 1B model and about 45% for the 3B model.
The newly released model can be downloaded from Llama's official website and Hugging Face .
Related Posts:






in Software, Posted by log1d_ts