A library ``vLLM'' that increases the output speed of large-scale language models by up to 24 times has appeared, and what is ``PagedAttention'', a new mechanism to improve memory efficiency?

When using a large-scale language model, you need not only the model itself, but also a library for handling the model. In many cases, a library called
vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
https://vllm.ai/
Libraries for manipulating large-scale language models include Hugging Face's Transformers (HF) and Text Generation Inference (TGI) for production environments. The vLLM that appeared this time is a form that joined this corner.
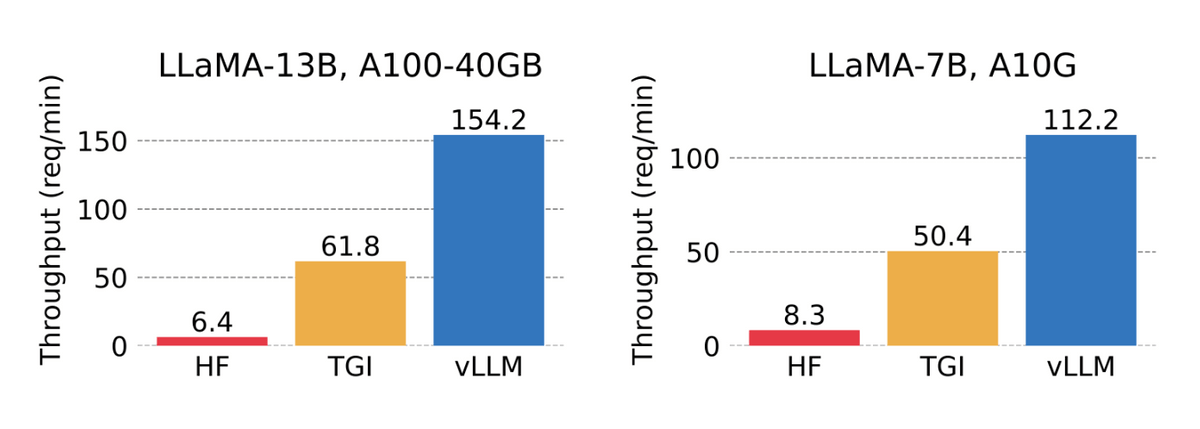
The figure below compares the processing speed (left) when running LLaMA's 13B model on NVIDIA A100 40GB and the processing speed (right) when running LLaMA's 7B model on NVIDIA A10G. . The Transformers shown on the far left are only processing orders of magnitude per minute, while the vLLM on the far right is processing over 100 requests. vLLM is 24x faster than Transformers and 2.5x faster than TGI.
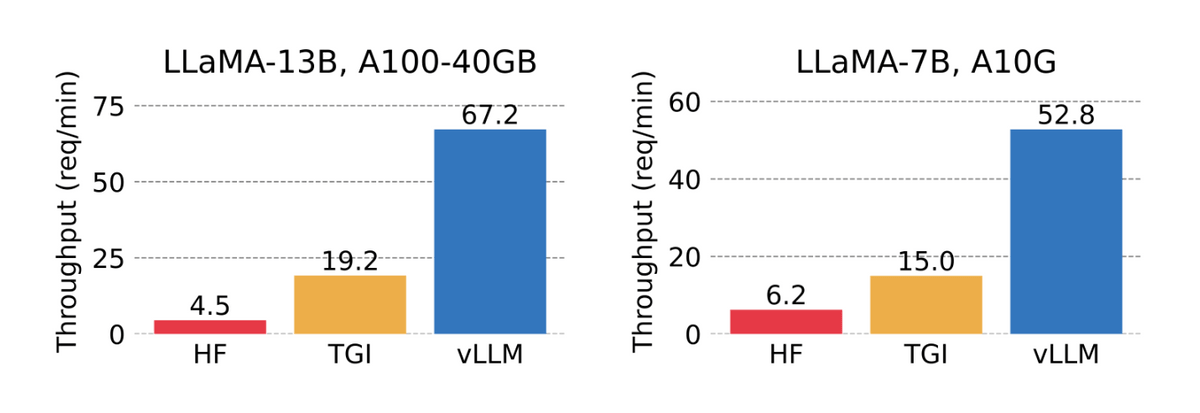
In addition, in parallel output tests that perform multiple outputs at the same time, processing is 15 times faster than Transformers and 3.5 times faster than TGI, showing performance.
The reason why we were able to achieve this speed improvement was that memory was the bottleneck as a result of examining the performance of large-scale language models. In large-scale language models, when generating text, tensors of attention keys and values are calculated from all input tokens and stored in GPU memory as KV cache. I had a problem.
·big
LLaMA's 13B occupies 1.7GB of memory per process.
- dynamically resize
The size of the KV cache depends on the length of sentences, but it is difficult to manage memory efficiently because it is not possible to predict how many sentences a large language model will output. In the conventional library, there were cases where 60% to 80% of the memory was wasted due to fragmentation and overreservation.
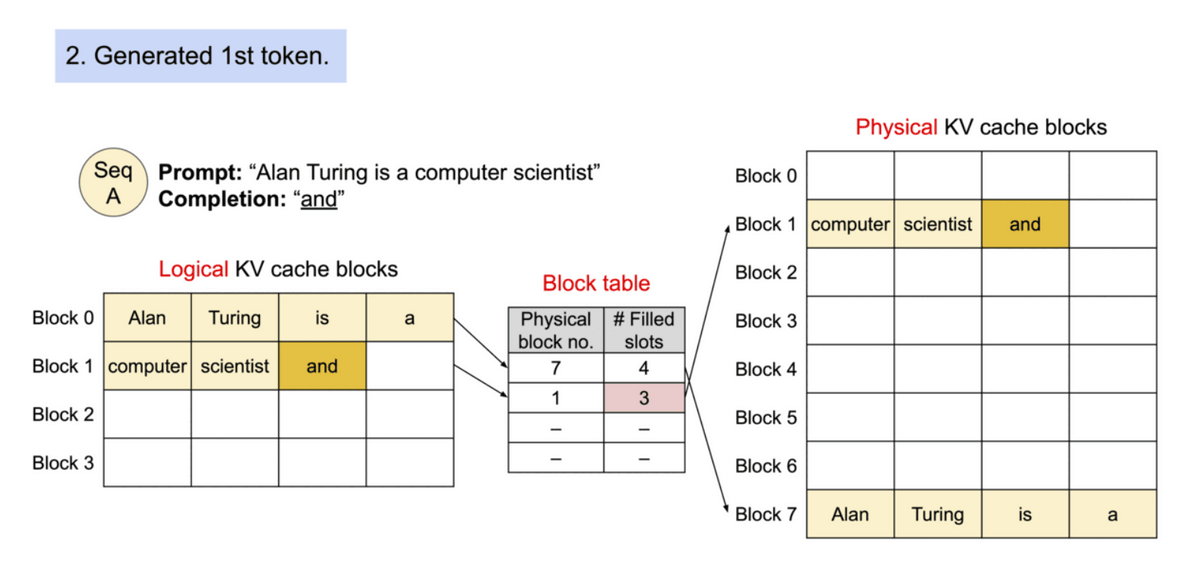
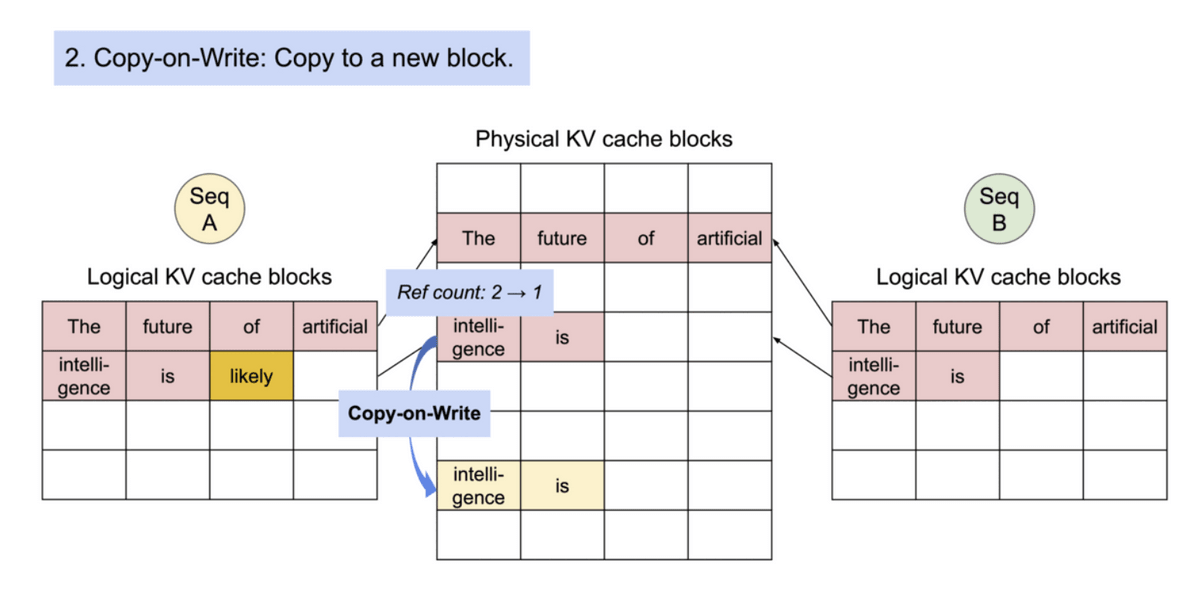
Therefore, the research team developed a mechanism `` PagedAttention '' that can efficiently handle memory when calculating attention, referring to the OS's virtual memory and paging mechanism. PagedAttention can store continuous KV cache in discontinuous memory space by dividing each input token by a certain length and handling it.

By using the block table, it is possible to treat blocks that are completely separated from each other in physical memory as if they were continuous.
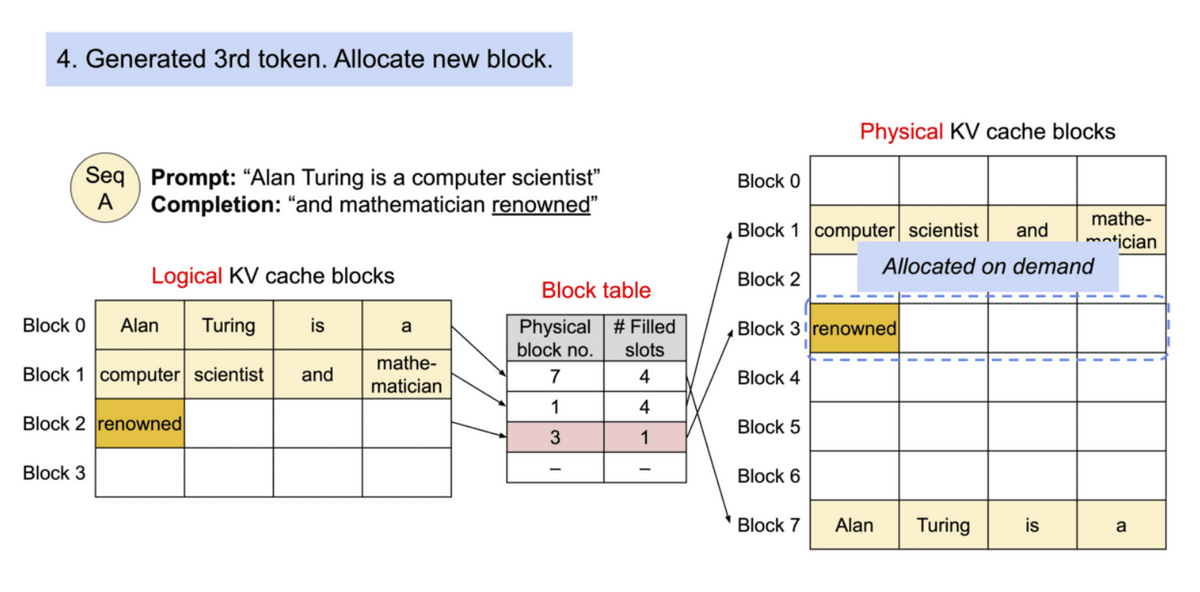
Also, new memory blocks are allocated as needed. By doing this, it is possible to keep the amount of memory that is wasted even though it is occupied within one block. Thanks to the improved memory efficiency, the system can process many requests in batches at the same time, improving the efficiency of GPU usage, which led to the improvement in processing speed as described at the beginning.
Additionally, PagedAttention can be even more memory efficient when processing multiple outputs simultaneously.
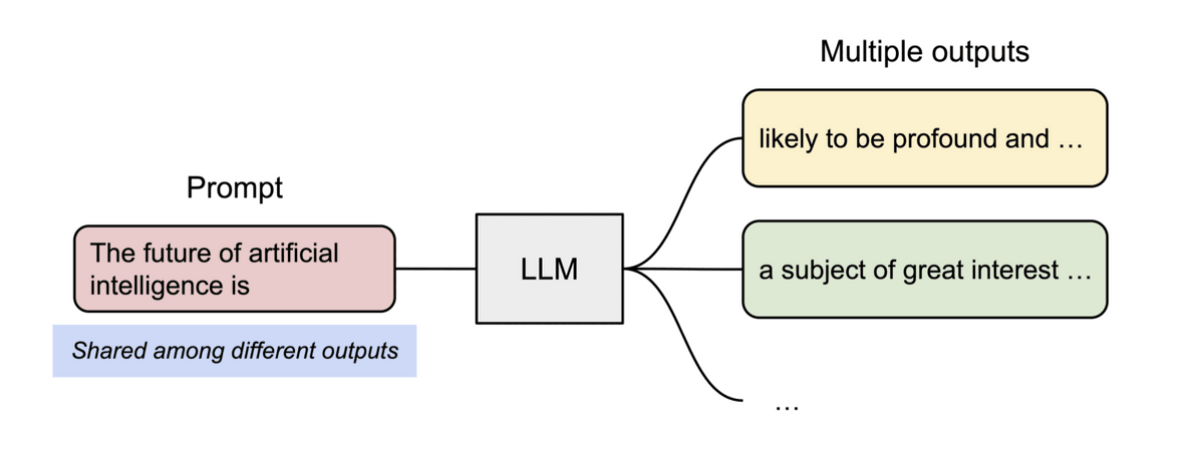
Specifically, the same physical block is used to refer to common parts in memory block units, which solves the problem of saving the same contents to memory multiple times. Also, when generating, the number of references is checked, and if there are multiple references, the contents are copied to a new block and written to prevent trouble.
The team that developed vLLM this time is mainly the development team of
For those who actually want to use vLLM, there are installation guides and quick start guides , so if you are interested, please check them out.
Related Posts:








in Software, Posted by log1d_ts