Google's AI processing chip 'Trillium' now available via Google Cloud, demonstrating four times the learning performance of previous generation TPUs

Google's sixth-generation TPU
Trillium TPU is GA | Google Cloud Blog
https://cloud.google.com/blog/products/compute/trillium-tpu-is-ga?hl=en
TPU v6e | Google Cloud
https://cloud.google.com/tpu/docs/v6e
Trillium is the sixth-generation TPU announced at Google I/O 2024 in May, and has made various advancements, including 4.7 times the peak performance per chip and twice the capacity and bandwidth of high-bandwidth memory (HBM) compared to the previous generation TPU v5e.
'Trillium is a key component of Google Cloud's AI hypercomputer, a groundbreaking supercomputer architecture that employs performance-optimized hardware, open software, and ML frameworks,' Google said.
Google announces 6th generation TPU 'Trillium', supporting Google Cloud AI with 4.7x better performance per chip and 67% more energy efficient than TPU v5e - GIGAZINE

Trillium is now available to the general public. Google claims that Trillium can be used to deliver superior performance across a wide range of workloads, including 'scaling AI training workloads,' 'training LLMs, including dense models and Mixture of Experts (MoE) models,' and 'inference performance and collection scheduling.'
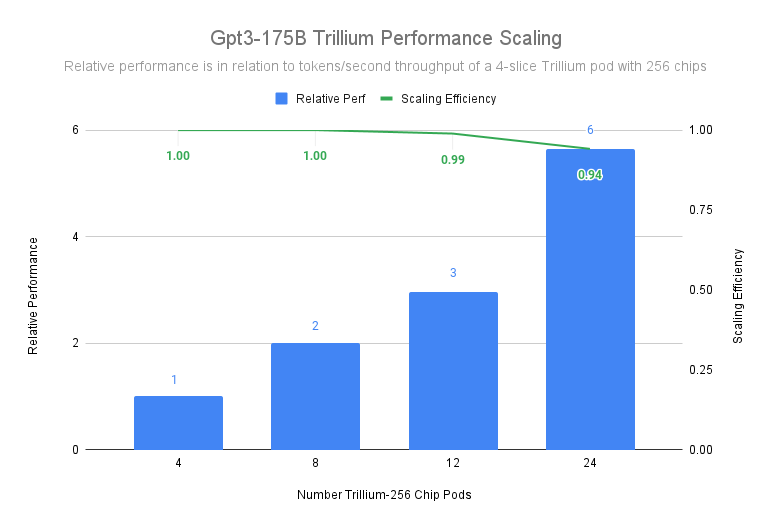
In the example of scaling AI training workloads, the scaling efficiency of pre-training the gpt3-175b model is shown below. Trillium has 256 chips per pod, and when using 12 of them, the scaling efficiency is up to 99%. Even when using 24 chips, the efficiency remains at 94%.
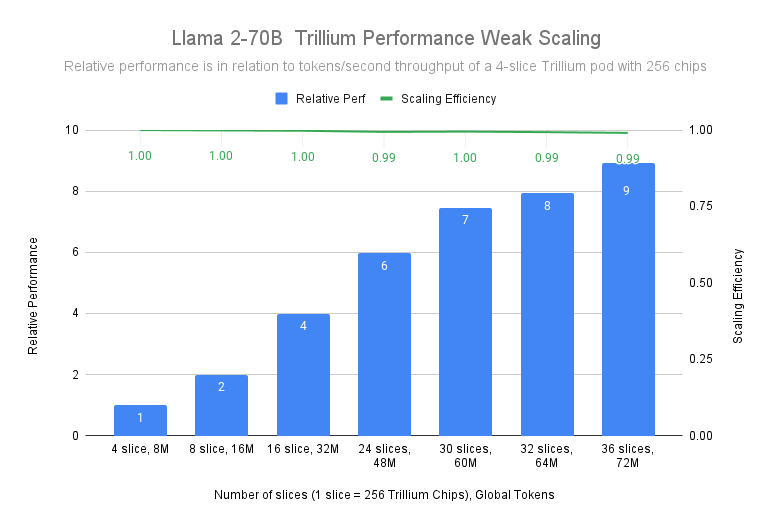
Training of the Llama-2-70B model demonstrated near-linear scaling from a 4-slice Trillium-256 chip pod to a 36-slice Trillium-256 chip pod with 99% scaling efficiency.
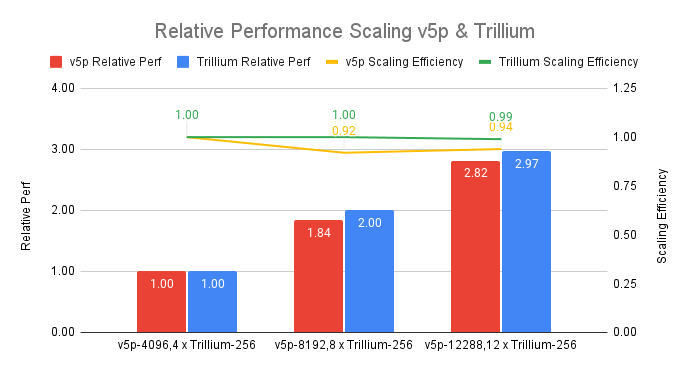
Trillium also exhibits better scaling efficiency when compared to its comparably sized predecessor, v5p.
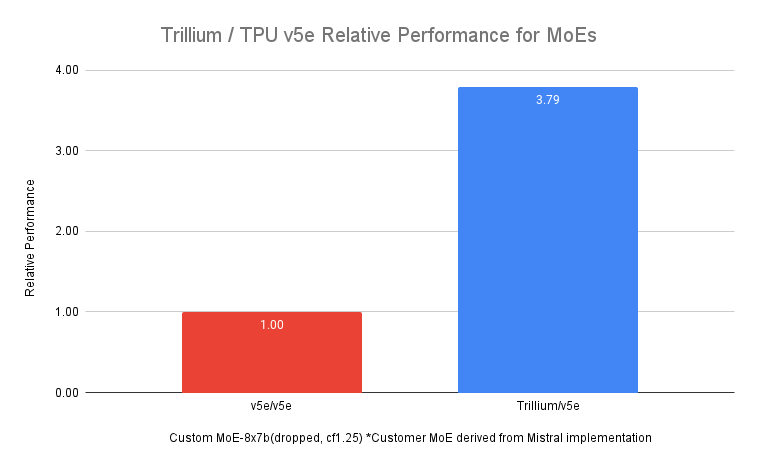
Trillium is also used for training Gemini 2.0, which was announced on the same day. Large-scale language models (LLMs) like Gemini have billions of parameters, making training complex and requiring enormous computing power. According to Google, compared to the previous model v5e, Trillium achieves training 3.24 times faster for the high-density LLM gpt3-175b and up to 4 times faster for Llama-2-70b.

In addition, it has become common to train LLMs using a machine learning technique called
Additionally, Trillium offers three times the host DRAM compared to v5e, which Google says 'helps offload some of the computation to the host, maximizing performance and goodput at scale.'
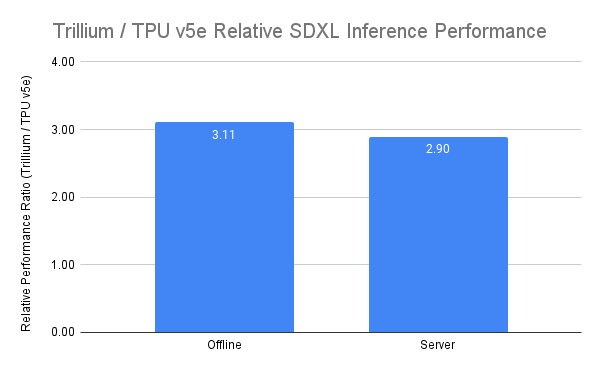
In response to the growing importance of multi-step inference during inference, Trillium has made great strides in inference workloads, with Stable Diffusion XL's relative inference throughput (number of images generated per second) more than three times higher than v5e, and Llama2-70B's relative inference throughput (number of tokens processed per second) nearly doubled. It also demonstrates the best performance in both offline and server inference use cases, with the relative throughput being 3.11 times higher than v5e for offline inference and 2.9 times higher for server inference.
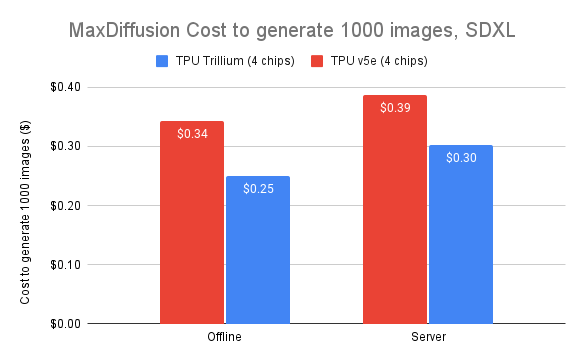
It also has high cost performance per dollar, achieving up to 2.1 times performance improvement per dollar compared to v5e and up to 2.5 times performance improvement per dollar compared to v5p. The cost of generating 1,000 images with Trillium is 27% lower than v5e for offline inference and 22% lower than v5e for server inference.
The actual server housing Trillium is shown in the video below.
A Google staff member opens the case.

There is a board inside.

This is Trillium.

'Trillium is a major leap forward for Google Cloud's AI infrastructure, delivering incredible performance, scalability and efficiency for a variety of AI workloads. Trillium can scale to hundreds of thousands of chips using world-class collaborative design software, enabling us to achieve breakthroughs faster and deliver better AI solutions,' said Google.
Related Posts:






