Google announces AI chip 'TPU v5p', which is up to 2.8 times faster than the previous generation and will also be used for training 'Gemini'

On December 6, 2023 local time, Google announced a new model of its machine learning specialized processor '
Introducing Cloud TPU v5p and AI Hypercomputer | Google Cloud Blog
https://cloud.google.com/blog/products/ai-machine-learning/introducing-cloud-tpu-v5p-and-ai-hypercomputer

The TPU v5p is built on the 'TPU v5e' released on August 30, 2023. However, the TPU v5e prioritizes power efficiency and cost performance over computing performance, and its actual performance was inferior to that of the previous model, ' TPU v4 '.
Google announces the fifth generation model of its AI-specialized processor TPU, 'TPU v5e,' with up to 2x the training performance and up to 2.5x the inference performance per dollar compared to the previous model - GIGAZINE

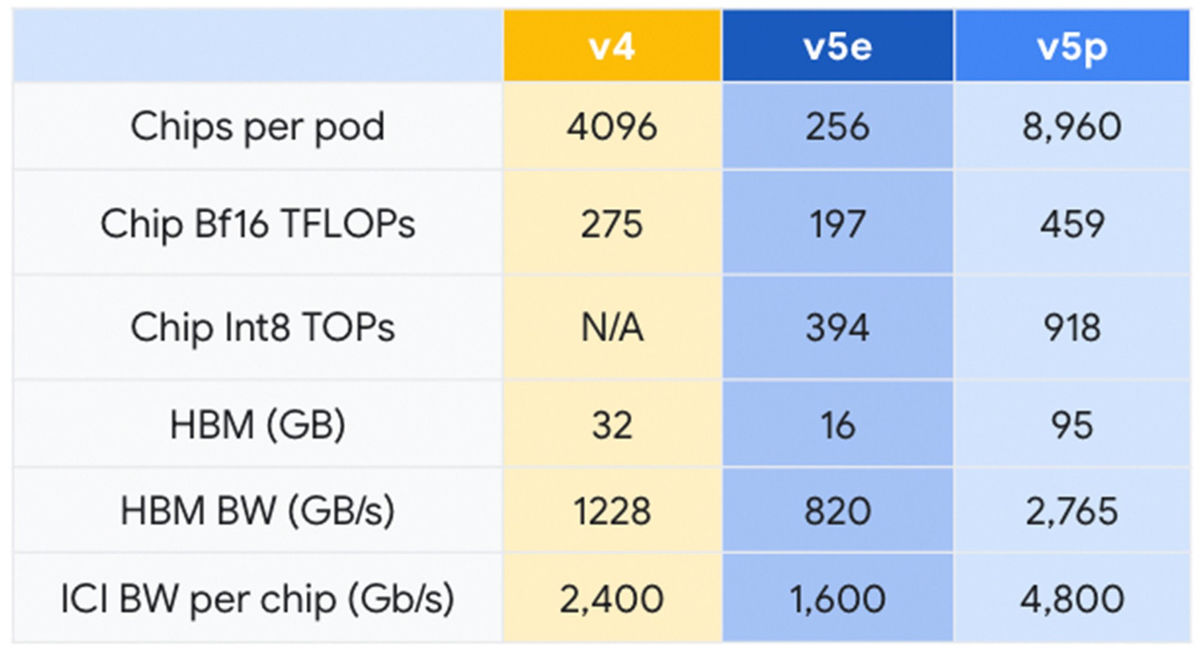
On the other hand, the newly announced TPU v5p is a performance-specialized TPU. Compared to the TPU v4, the TPU v5p is composed of a total of 8,960 chips, with 95 GB of memory per chip and a significantly improved memory bandwidth of 2,765 GB per second. Google says, 'This performance will enable us to meet the computational needs of higher-level AI learning.'
Below is a table comparing the performance of the TPU v4, TPU v5e, and TPU v5p published by Google. It can be seen that the TPU v5p significantly outperforms the conventional TPU v4 and TPU v5e in terms of the number of chips per pod, 16-bit floating-point performance, and the number of operations that can be performed per second.
In addition, the TPU v5p also supports learning using
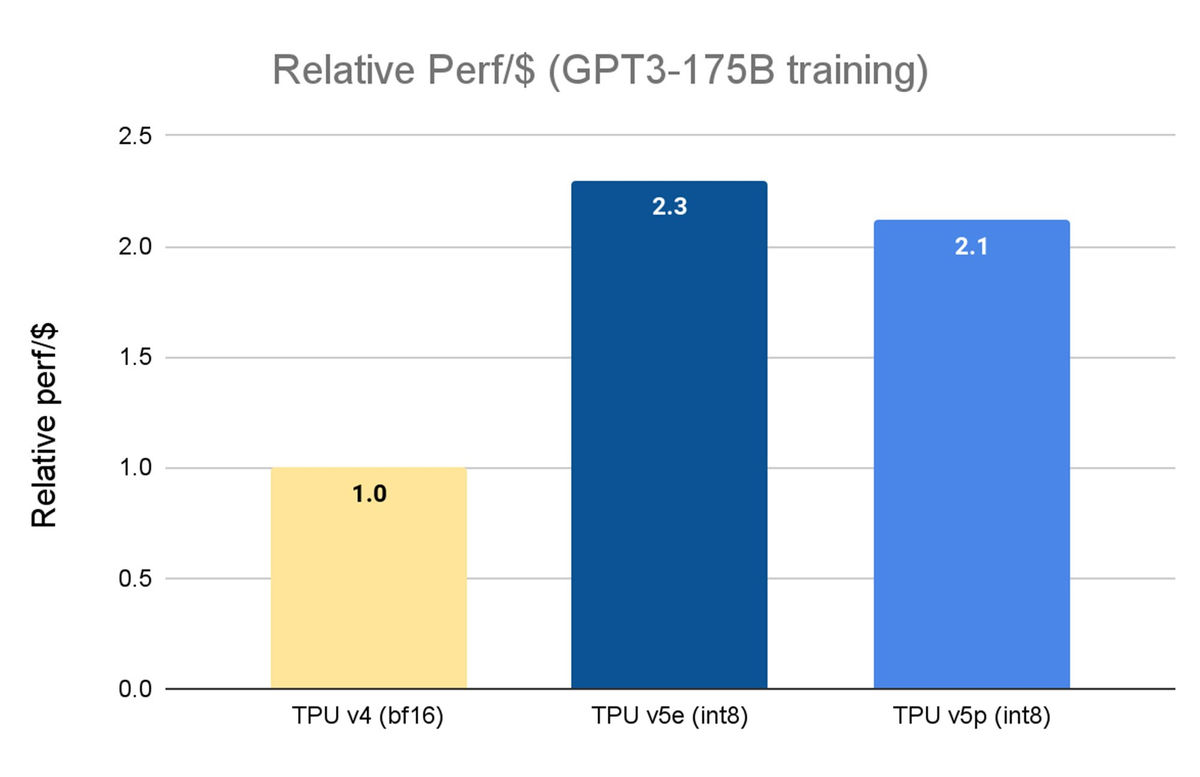
On the other hand, the TPU v5e is more cost-effective. When training GPT3-175B, if the relative performance per dollar of the TPU v4 is set to 1, the TPU v5p is about 2.1 times better, while the TPU v5e is about 2.3 times better.
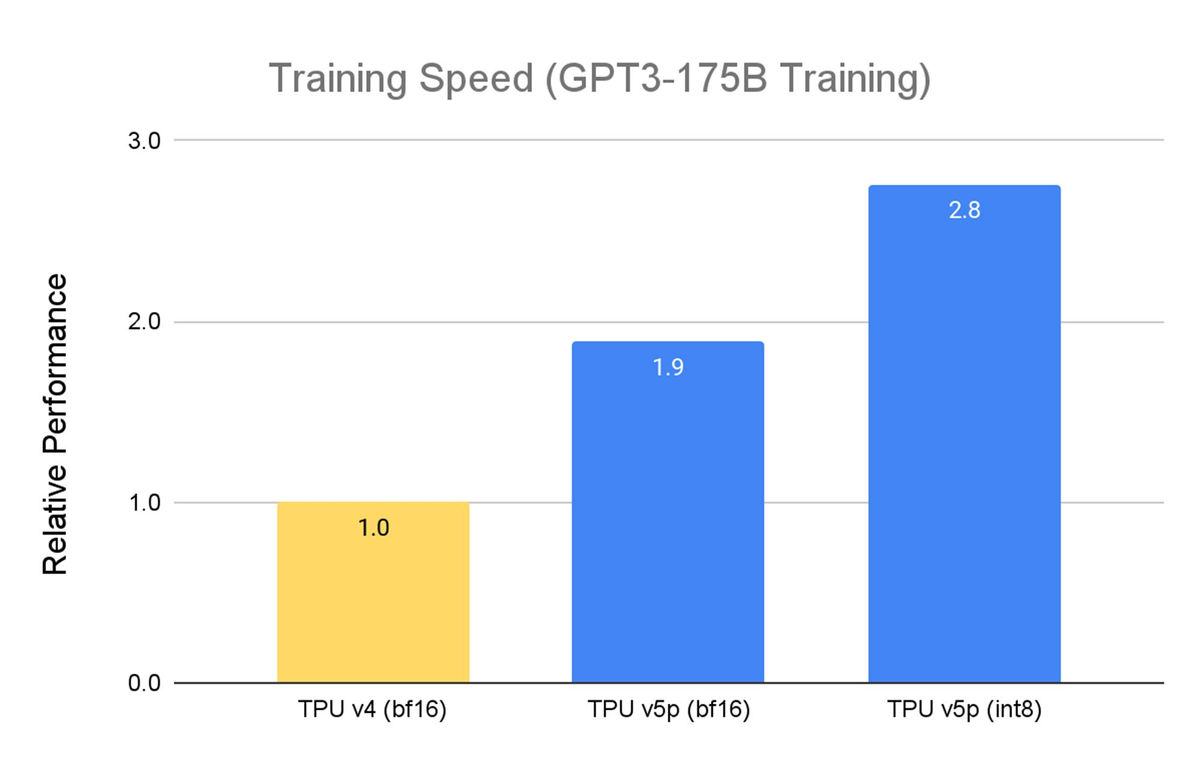
'We've seen roughly 2x speedup in training large language models with TPU v5p compared to the performance of the TPU v4 generation,' said Jeff Dunn, chief scientist at Google DeepMind and Google Research. 'Strong support for machine learning frameworks such as JAX, PyTorch and TensorFlow, as well as a range of automated tools, makes it possible to scale even more efficiently than previous models.'
Google reported about the TPU v5p, 'In fact, Gemini, Google's most high-performance AI model, which was announced at the same time as the TPU v5p, was trained on the TPU v5p.'
A multimodal AI called 'Gemini' that can process text, voice, and images simultaneously and interact more naturally than humans, surpassing GPT-4, will be released - GIGAZINE

'The TPU v5p is essential for research and engineering efforts using cutting-edge AI models like Gemini for multimodal AI,' said Dan.
Regarding the availability of TPU v5p, Google stated, 'If you would like access, please contact your Google Cloud account manager .'
Related Posts:






