What is the appearance of the machine learning system architecture shown by engineers who were top executives in Google's AI division?

The world of machine learning and artificial intelligence (AI) based on the machine learning technology advances constantly is a place where new technology will always continue to appear. Jeff Dean, who once served as chief at Google's AI department and was at the top of Google Brain, talks about important points in determining future machine learning.
Google AI Chief Jeff Dean's ML System Architecture Blueprint
https://medium.com/syncedreview/google-ai-chief-jeff-deans-ml-system-architecture-blueprint-a358e53c68a5
In January 2018, Mr. Dean co-presented the paper " A New Golden Age in Computer Architecture: Empowering the Machine-Learning Revolution " with Turing Award winner and computer architect (designer) David Patterson . This paper is encouraged to collaborate and design machine learning experts and computer architects necessary for realizing machine learning possibilities.

Mr. Dean also gave a lecture on the trends of models that researchers want to learn at the "Tsinghua-Google AI Symposium" held in Beijing in July 2018.
Dean said that the increase curves of machine learning-related articles archived at the paper archive site "arXiv" already exceeded the rising curve of "Moore's Law" which showed the growth forecast of computer chips in 1975 It pointed out.

Mr. Dean and Mr. Patterson described in the paper the example of hardware developed by Google, exemplifying " TPU v1 " which is the first generation of the processor for machine learning · Tensor Processing Unit of the second generation and " TPU v2 " of the second generation I will analyze. In order to maintain competitiveness as machine learning hardware, the two sides explain the necessity to judge the situation on the 5-year time axis consisting of at least 2 years of design and 3 year introduction period.
Mr. Dean raises the following six points on machine learning hardware design on the time axis of the past five years.
◆ 1: Training (strengthening)
The two most important phases in machine learning workflow are the production phase called "inference" or "prediction" and the development phase called "training" or "learning" And that.
Google announced TPU v1 in 2015, TPU v2 in 2017, and TPU 3.0 in 2018. Mr. Dean cited past achievements such as linking 16 TPU v2s to improve search speed of Google's search ranking model by 14.2 times and training model speed of image model by 9.8 times. TPU v2 is originally a system configuration that exercises the required performance by connecting 64 units, but Mr. Dean has realized high speed with a quarter of its configuration.
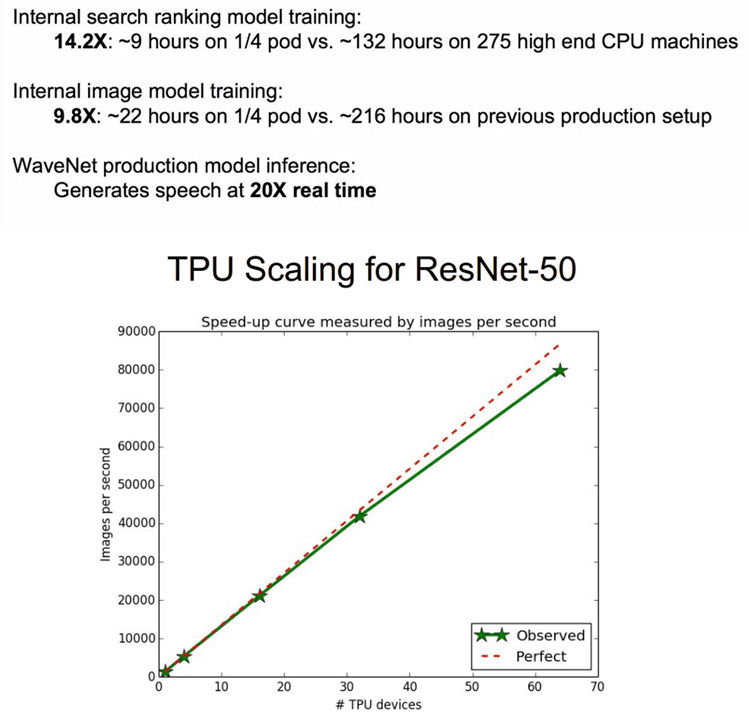
TPU is a very expensive hardware, but as part of the TFRC (TensorFlow Research Cloud) program, Google will add 1000 TPU devices to top-level scientists working on machine learning research We offer it free of charge.
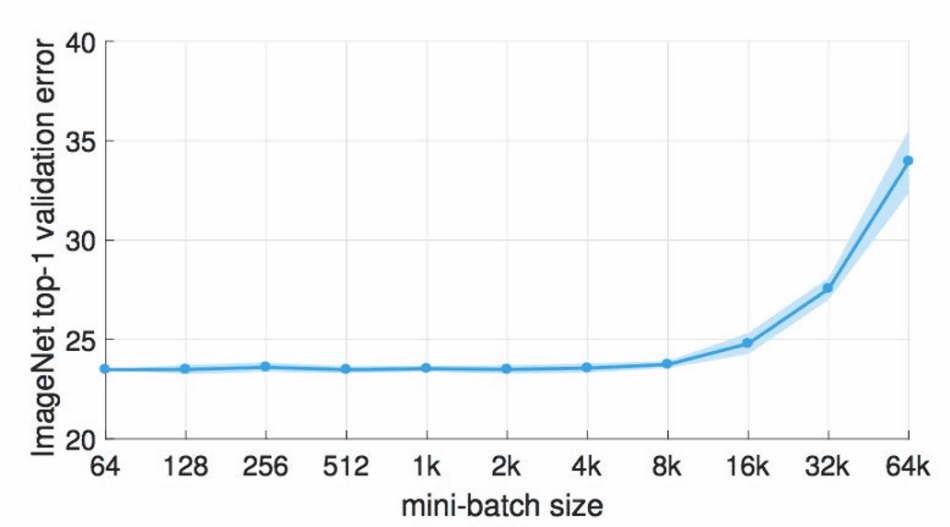
◆ 2: Batch size <br> Important setting for advancing machine learning One of the "hyperparameter" is "batch size". This is to process data for training by dividing it into small batches (mini batches), and its size setting greatly influences the speed and efficiency of machine learning.
The GPU used as of 2018 is said to be able to operate efficiently with 32 or more mini batch sizes. However, in the article " [1706.02677] Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour " published by Facebook AI Research (FAIR), the visual recognition model for learning images is a mini batch size of "8192" and "32768" It has been shown to be trained effectively. Although such large-scale training is suitable for the FAIR model, it is the current situation that it is not regarded as a universal solution.
◆ 3: Sparity (sparsity) and embedded "sparcity" or "sparseness" means that only a part of the neurons of the neural network will ignite (react). There are various forms of sparcity, and by using it successfully, it becomes possible to reduce the complexity of machine learning by skipping 0 and small values of data. In general, researchers need increasingly large model sizes for large datasets, but they are preaching that "a larger model, but a sparsely activated state" is important I will.
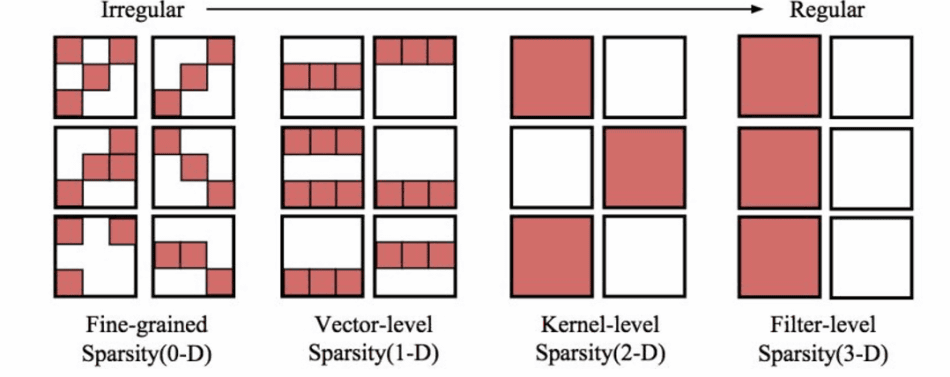
One such example is Google Brain's Mixed of Expert (MoE) model. In this model, we refer to a subset of the "Expert" panel learned as part of the network configuration to achieve the desired level of sparsity.
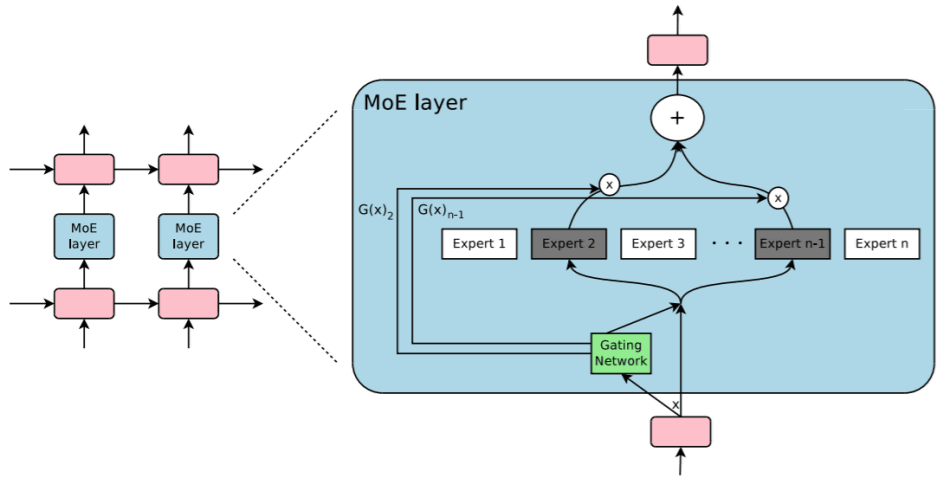
As a result, MoE models learn more precisely with fewer FLOP numbers than previous approaches. In the English-to-French translation dataset Google has, the MoE model is trained in only one sixth of the time and then 1.01 times higher than the Google Neural Machine Translation (GNMT) model, which is the brain of Google translation Bilingual Evaluation Understudy score was recorded.

◆ 4: Quantization and Distillation "Quantization" has already proved useful in cost-effective machine learning reasoning. In addition, there is widespread recognition that distillation that learns the input and output of already trained AI as it is, learning to a new simple AI can not be neglected in improving efficiency.
◆ 5: Network with 'Soft Memory' <br> Dean and Patterson in the thesis show that several deep learning techniques can provide functions similar to memory access (access to memory) . For example, the "attention mechanism" can be exploited to improve machine learning performance in machine translation by paying attention to selected parts of the source during long sequences of data processing It is thought.
Unlike the conventional "hard memory", "soft memory" calculates a weighted average for all entries prepared for content selection with a large amount of information. However, this is a complicated process, and there has not been any research on implementing soft memory models efficiently or with sparsity.
◆ 6: "Learn from learning"
Most large machine learning architectures and their model designs still depend on empirical rules and instincts of human experts. "Learning to Learning (L2L)" which learns from machine learning learning is revolutionary in the sense of being a model enabling automatic machine learning without human decision by decision by a human expert. This approach is used to address problems that machine experts are missing.
In the case of automated machine learning, the Google Brain team uses "Reinforcement Learning". This is the method proposed in the paper " Neural Architecture Search with Reinforcement Learning " published in 2017. By using "accuracy" as a reward signal, this model learns to self improvement over time. In the paper, applying "CIFAR-10 dataset" for the discovery of new network architecture and "Penn Treebank dataset" on the composition of new memory cell with reinforcement learning, both the conventional state-of-the-art We achieved results comparable to the method.


Other examples of applying reinforcement learning in meta-learning include detecting optimal paths, selecting activation functions, and updating criteria for learning optimization. In the Neural Machine Translation (NMT) model training test, the learning speed was about 65 hours faster than the professional placement, despite reinforcement-based placement inconsistent with human intuition, 27.8% Speeding up training time has been achieved.
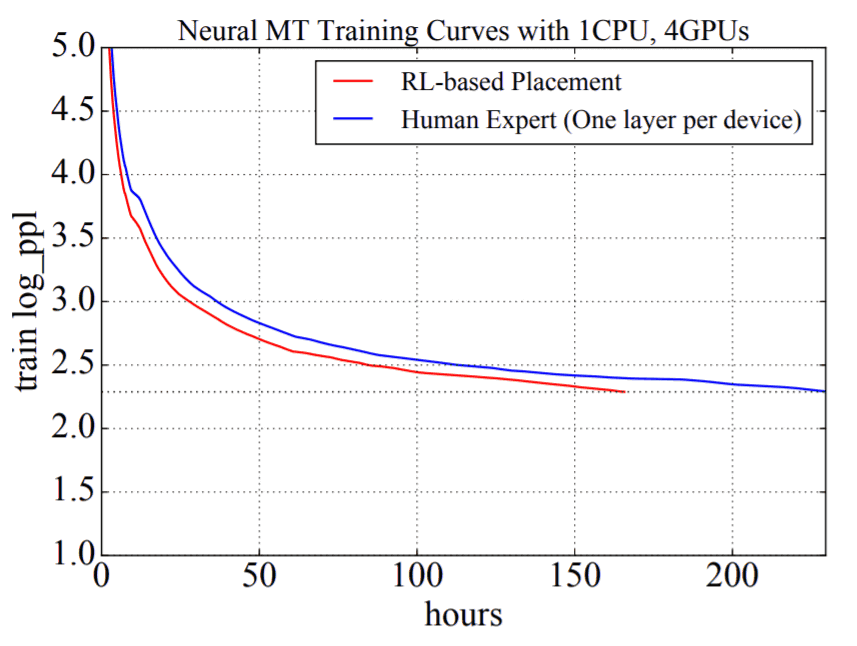
Future prospects At the end of the symposium, Mr. Dean presents the following ideas on future prospects.
1. It is a large-scale model, but it is activated sparsely
2. A single model to solve many tasks
3. Learn routes dynamically through large models and grow
Four. Machine learning Hardware specialized for supercomputing
Five. Machine learning capable of efficient mapping to hardware
Related Posts: