What kind of theory was established for large-scale language models such as ChatGPT? Summary of 24 important papers
ChatGPT was released in November 2022, and after
Understanding Large Language Models - by Sebastian Raschka
https://magazine.sebastianraschka.com/p/understanding-large-language-models
◆ Contents
・Main architecture and tasks
・Improve scaling and efficiency
・Guide the language model to the intended direction
・Reinforcement learning with human feedback (RLHF)
・Main architecture and tasks
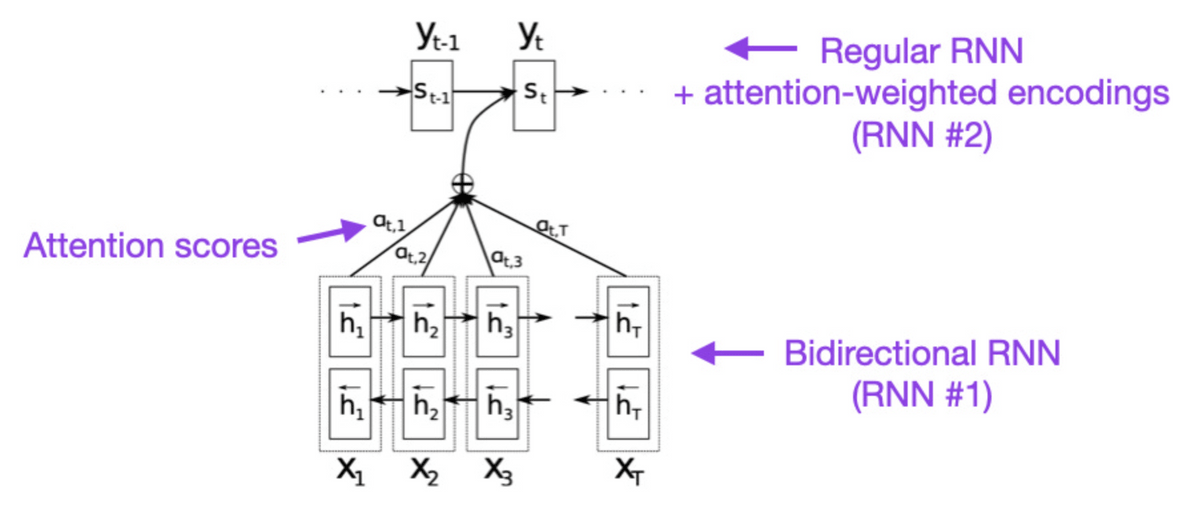
◆1: Neural Machine Translation by Jointly Learning to Align and Translate (2014)
By introducing 'attention', which part of the input is emphasized in the recurrent neural network (RNN) , it has become possible to accurately handle longer sentences.
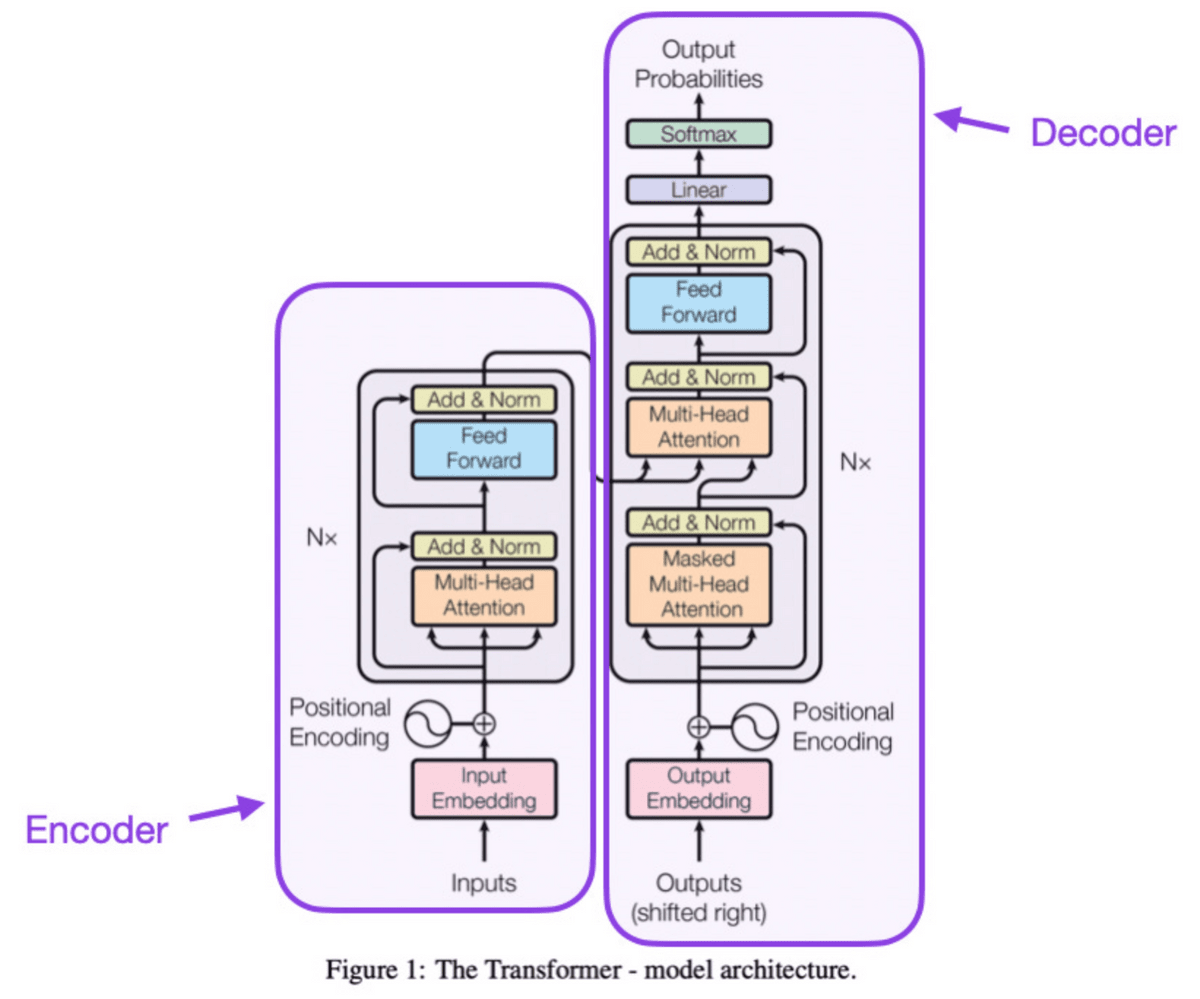
◆2:
A 'transformer' model was introduced, which consists of an encoder part and a decoder part. The paper also introduces a number of modern foundational concepts such as positional input encoding.
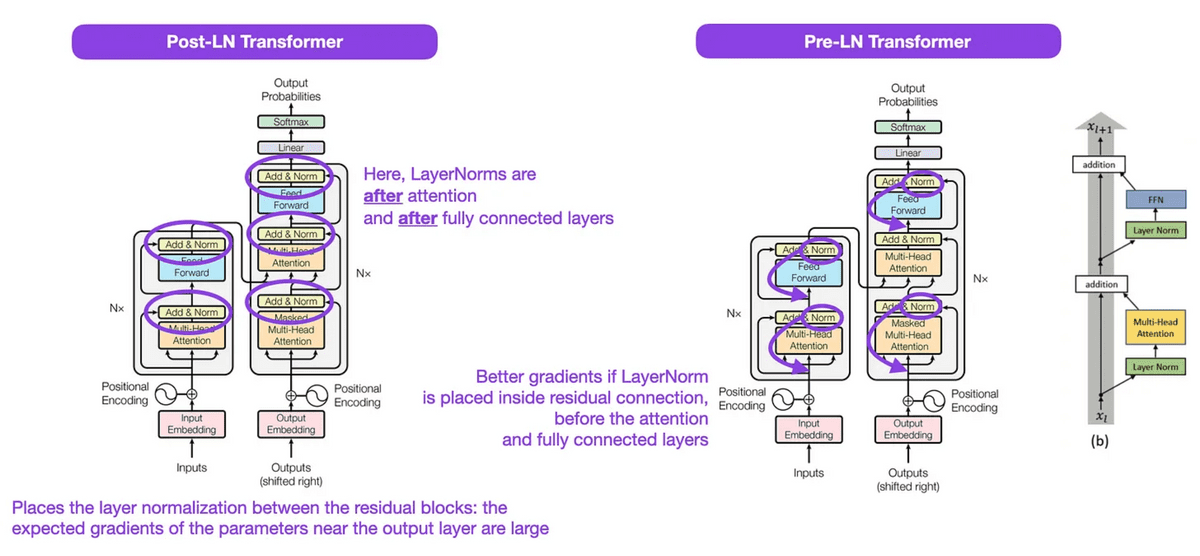
◆3:
I've shown that placing the 'Norm' layer of the transformer model in front of the block works better.
◆4:
Already in 1991 an approach comparable to Transformers was being considered. Mr. Rashka says, 'Recommended for those who are interested in history.'
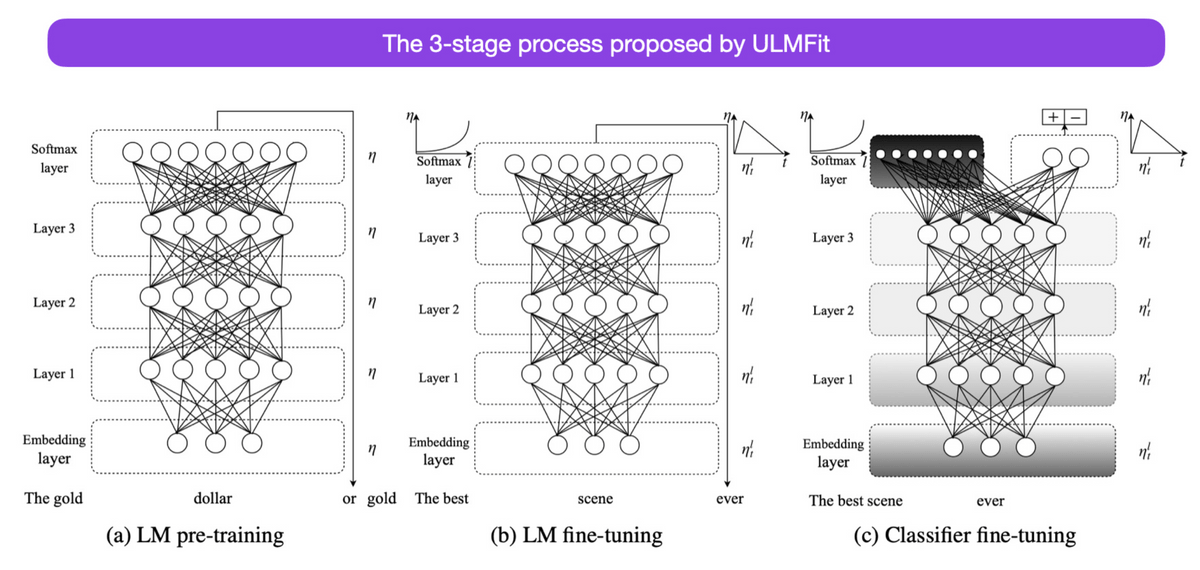
◆5: Universal Language Model Fine-tuning for Text Classification (2018)
We showed that training a language model in two stages, pre-learning and fine-tuning, enables it to perform tasks well. This paper was written a year after the Transformers paper, but the focus is on regular RNNs rather than Transformers.
◆6:
According to the structure of the transformer, which is divided into an encoder and a decoder, the research field is also divided into two directions: the direction of the encoder type transformer, which performs text classification, etc., and the direction of the decoder type transformer, such as translation and summarization.
The BERT paper introduced a technique of masking parts of sentences to make predictions, allowing the language model to understand the context.
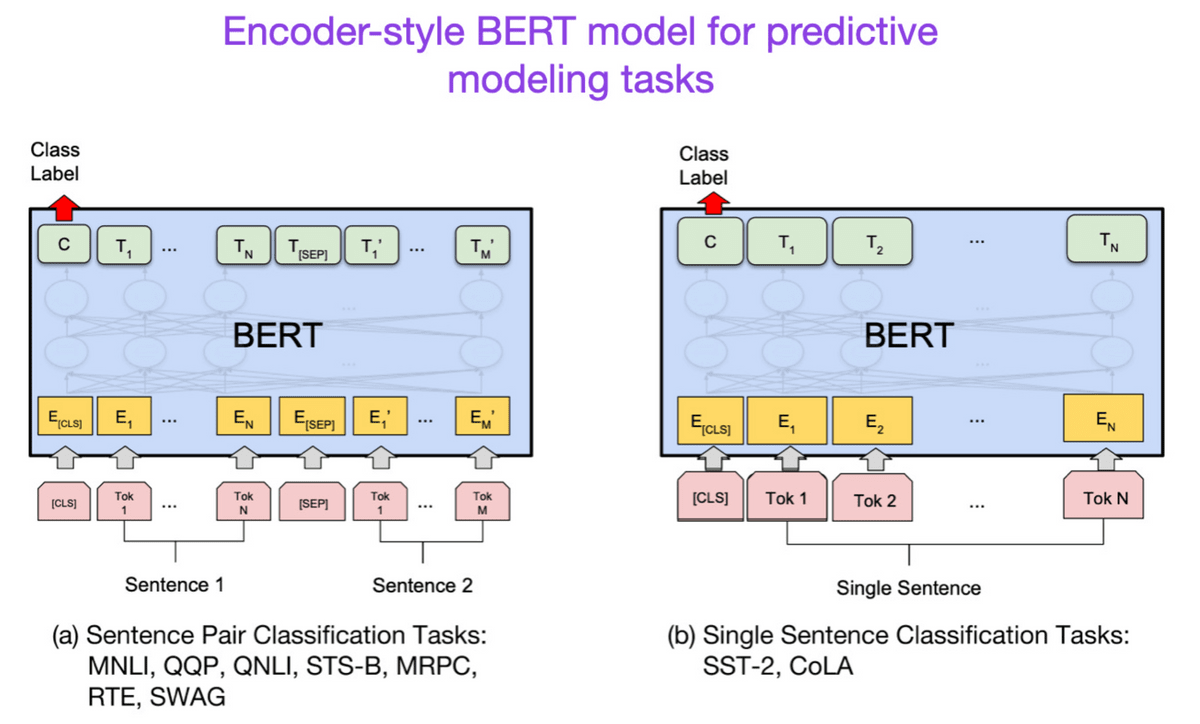
◆7:
First GPT paper. We trained a language model with a decoder-type structure by ``predicting the next word''.
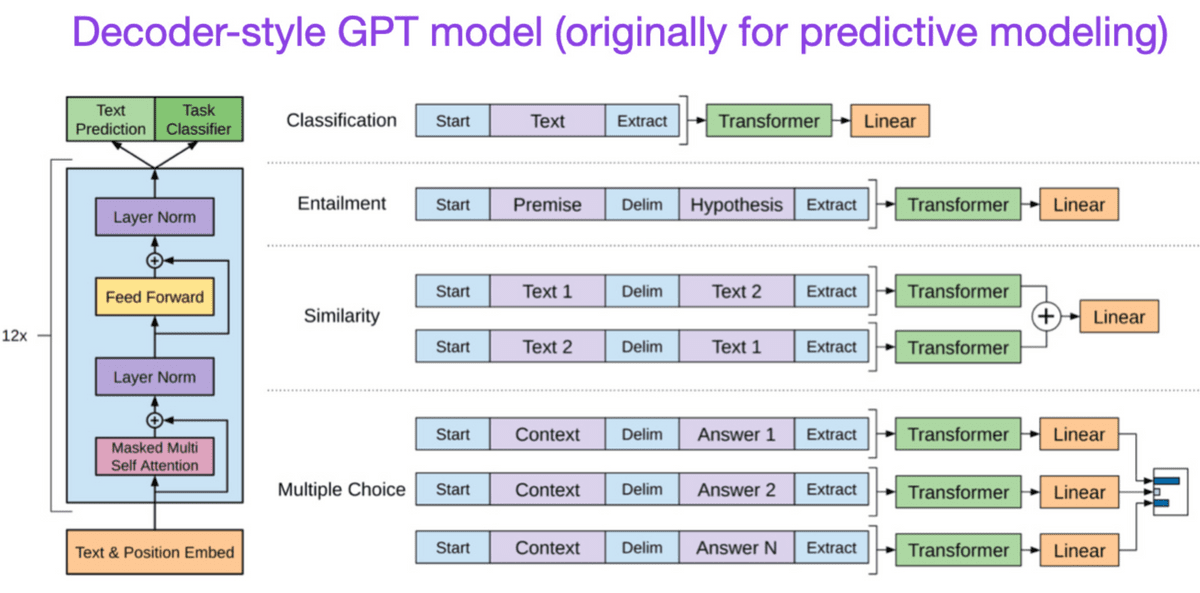
◆8:
We combined an encoder-type transformer, which is good at prediction, and a decoder-type transformer, which is good at text generation, so that we can take advantage of the strengths of both.
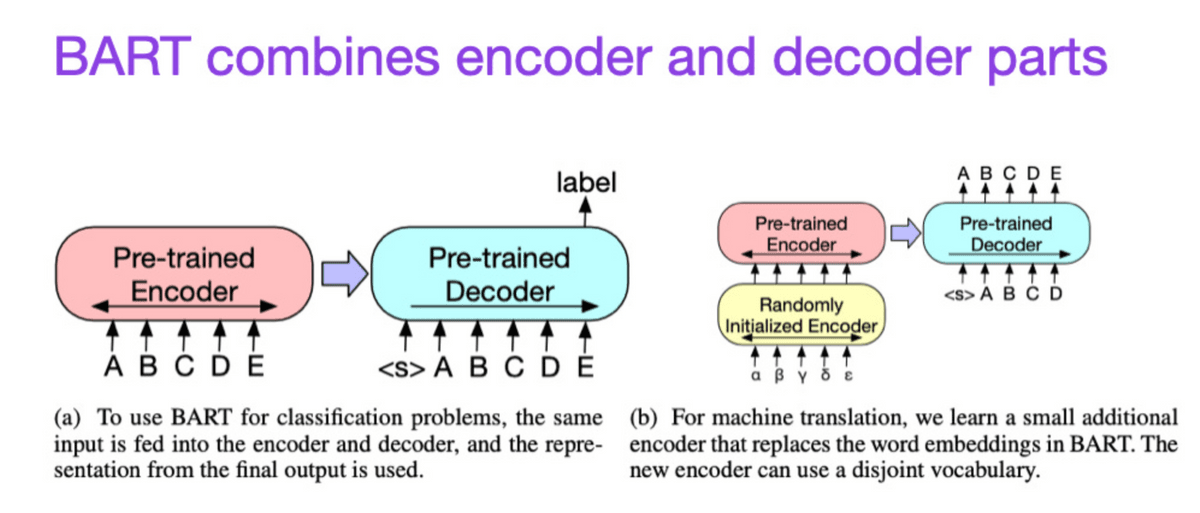
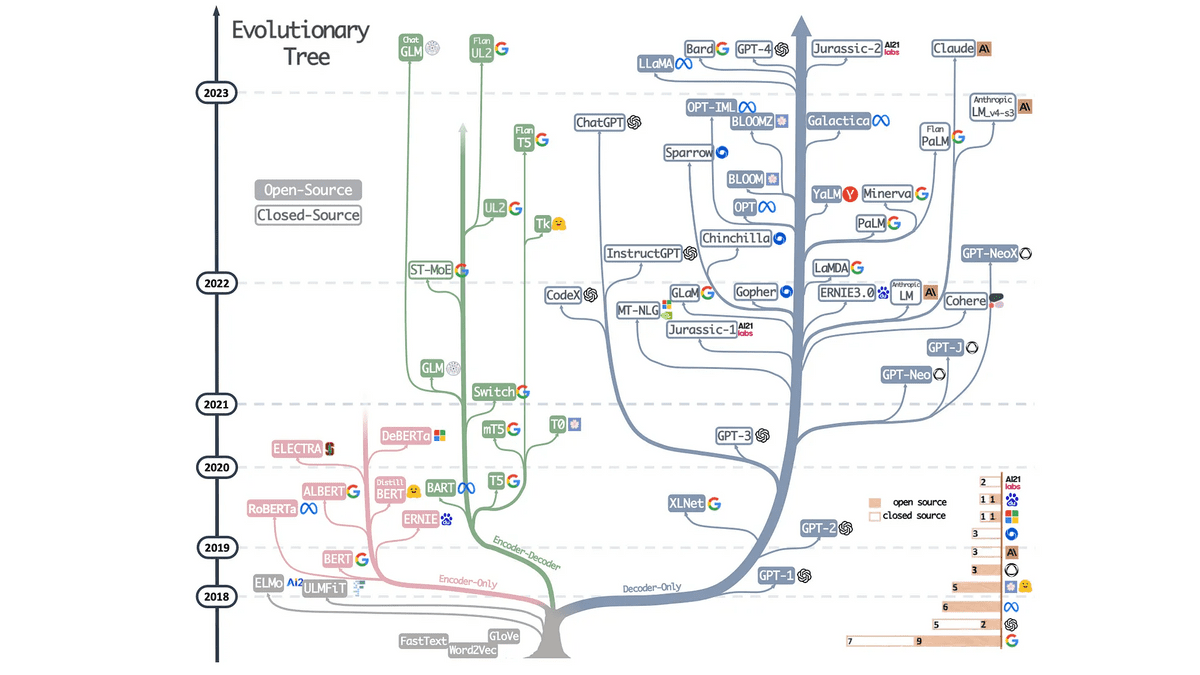
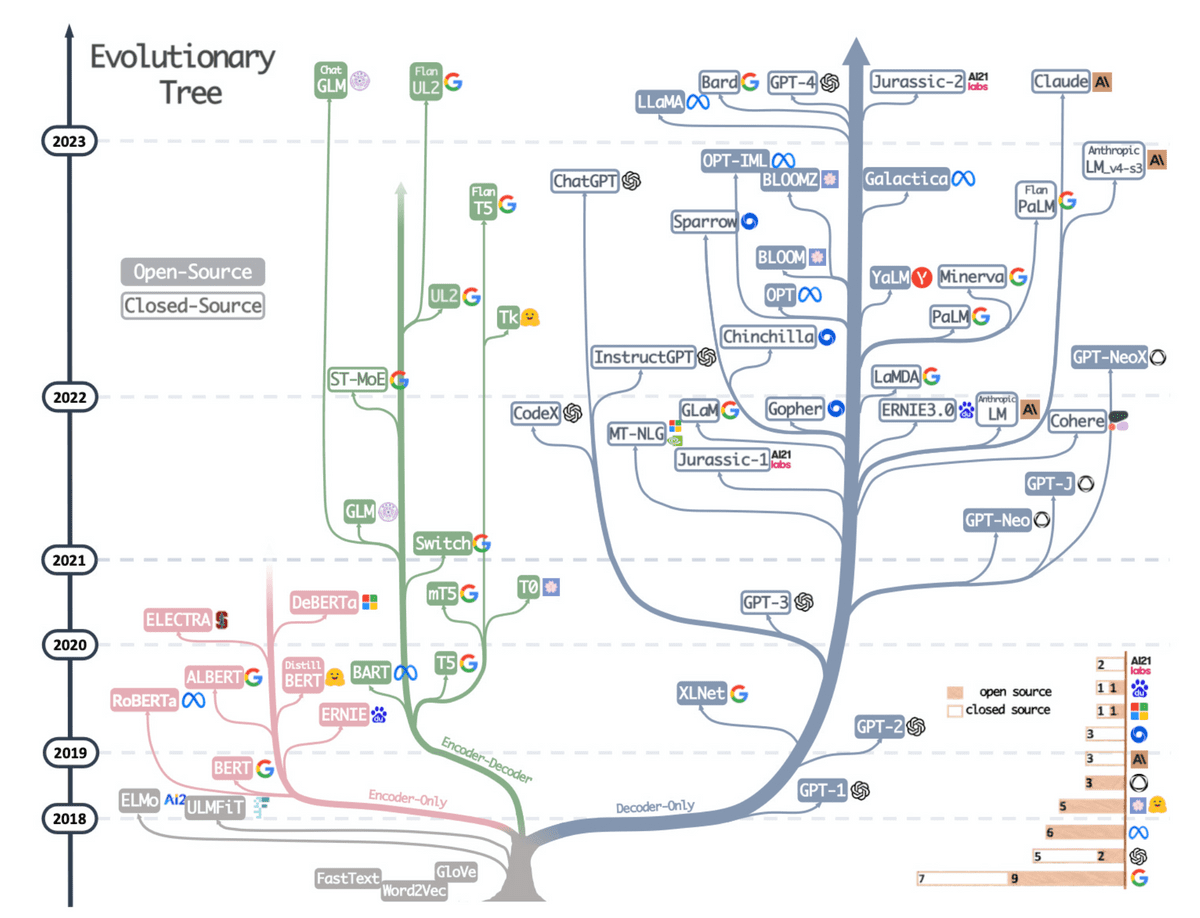
◆9:
It's not a research paper, it's a paper summarizing the findings of how different architectures evolved. As shown by the blue branch on the right, we can see that the development of the decoder type is particularly remarkable.
・Improve scaling and efficiency
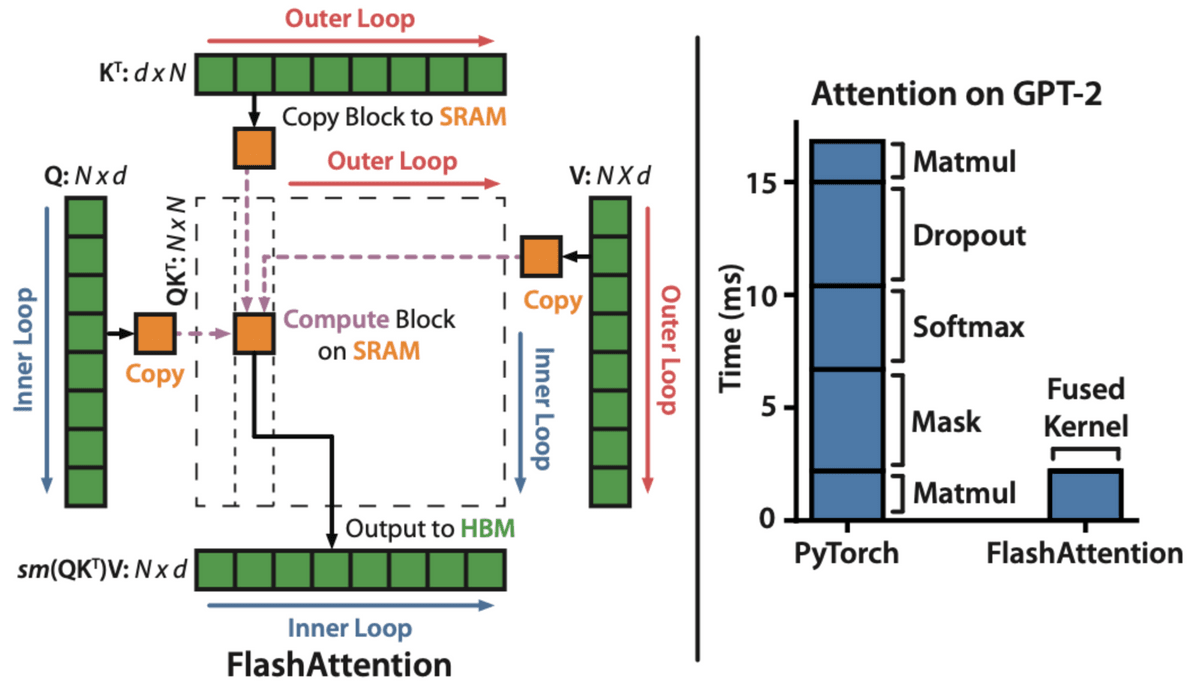
◆ 10:
It is a wonderful explanation of an algorithm that can perform attention calculations at high speed and also reduce memory consumption.
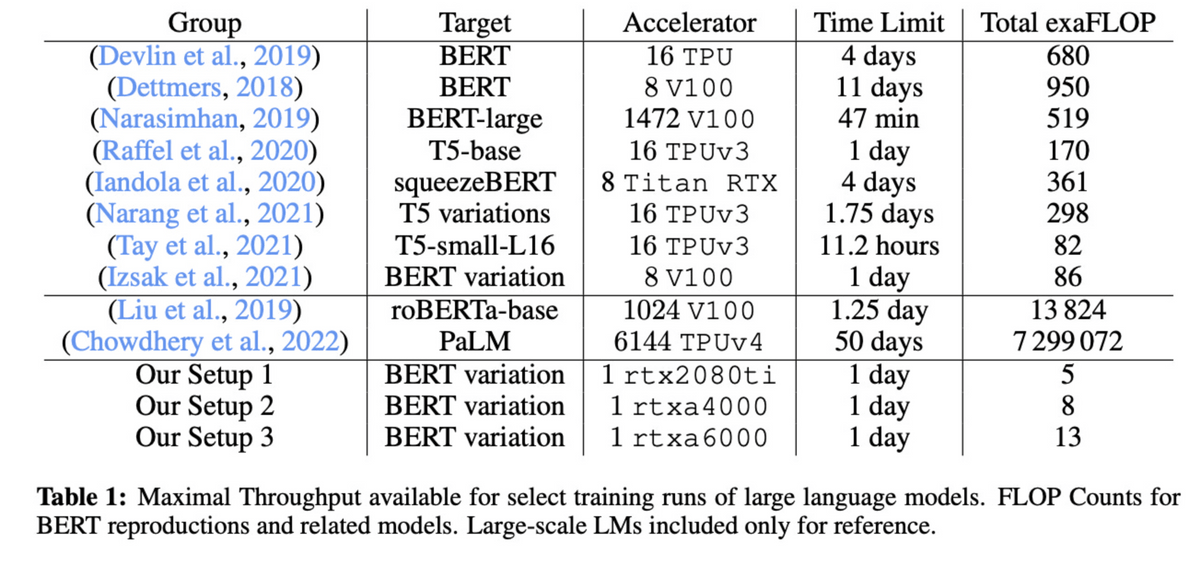
11:
It has been shown that small models can be trained quickly, but at the same time they are less efficient to train. Conversely, even if the size of the model is increased, it can be trained in a similar amount of time.
◆12:
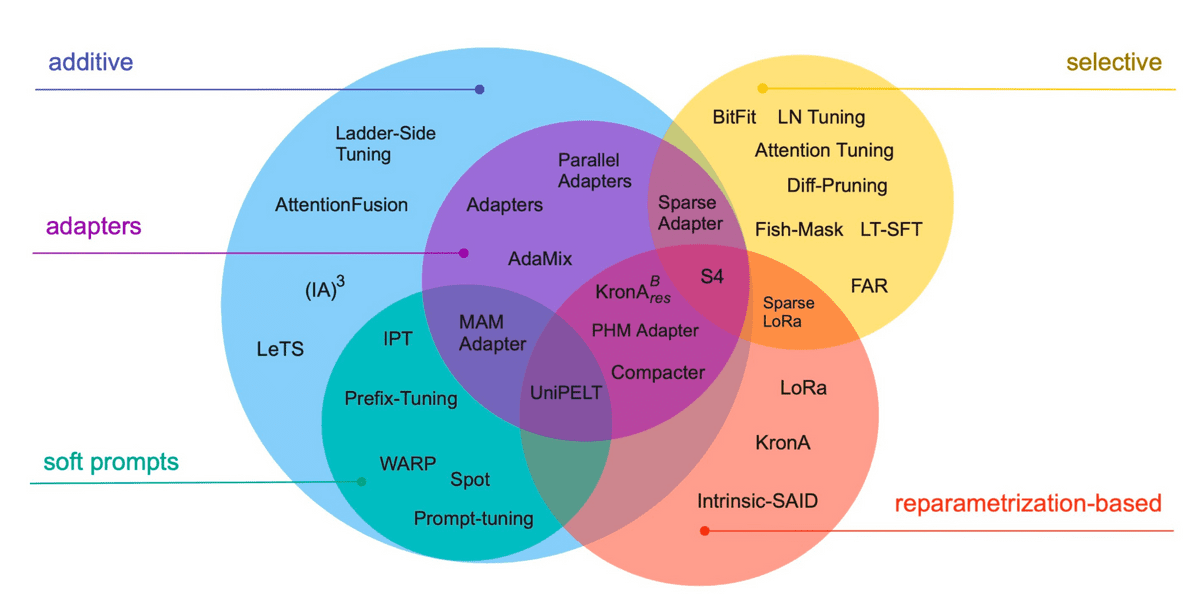
There are various methods for fine-tuning large-scale language models, but among them, “LoRA” is a method with high parameter efficiency.

LoRA is explained in the middle of the article below.

◆13: Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning (2022)
Pre-trained language models perform well in various tasks, but fine-tuning is necessary if you want them to specialize in specific tasks. In this paper, a number of techniques for efficient fine-tuning are reviewed.
◆14:
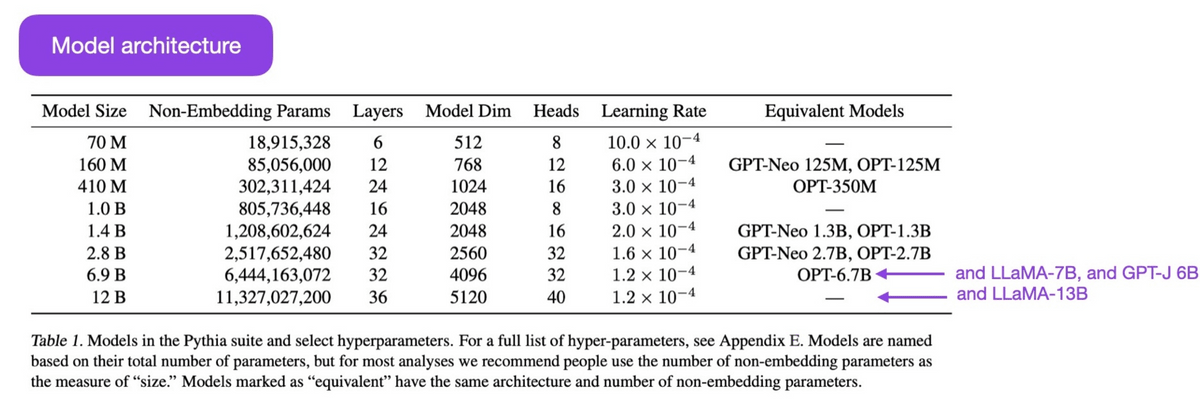
After seeing how performance improves as we increase the number of parameters in the language model, we find that it gets better at tasks like comprehension, fact-checking, and identifying toxic words. On the other hand, the results of logic and mathematical reasoning tasks did not change much.
◆15:
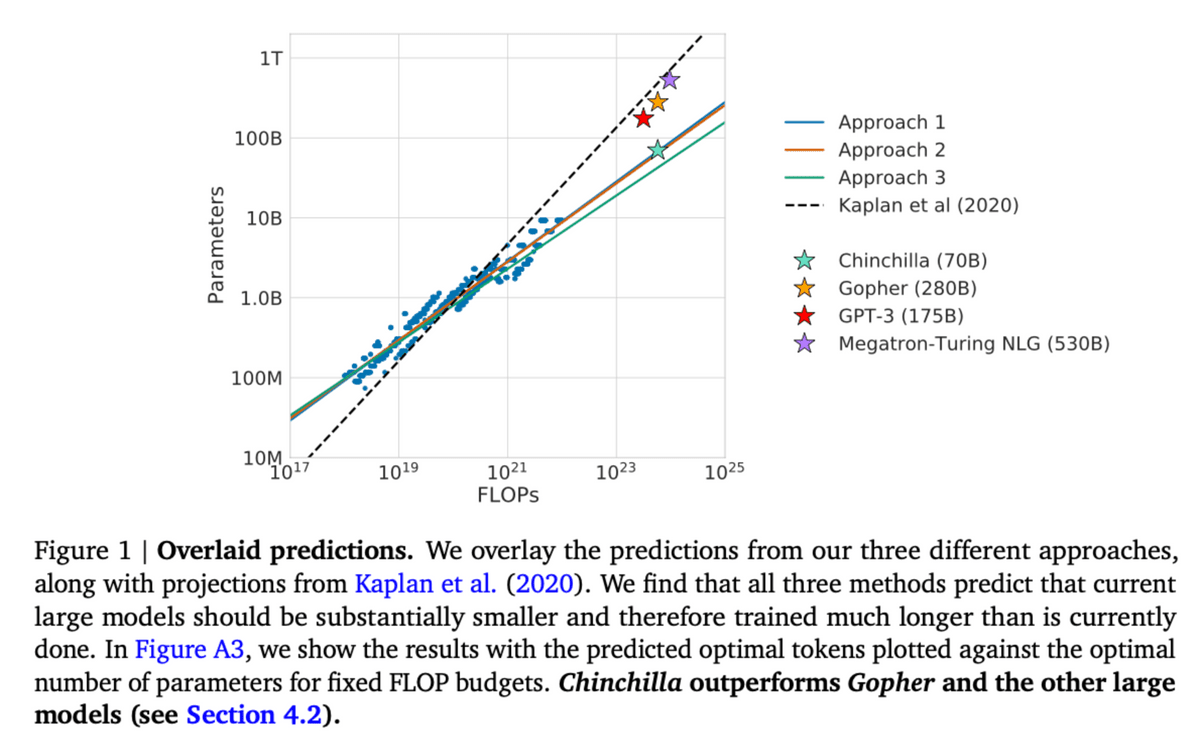
We showed a new relationship between the number of parameters in the model and the number of training data for performance improvement on the generation task. He points out that models such as GPT-3 and Gopher are undertrained.
◆16:
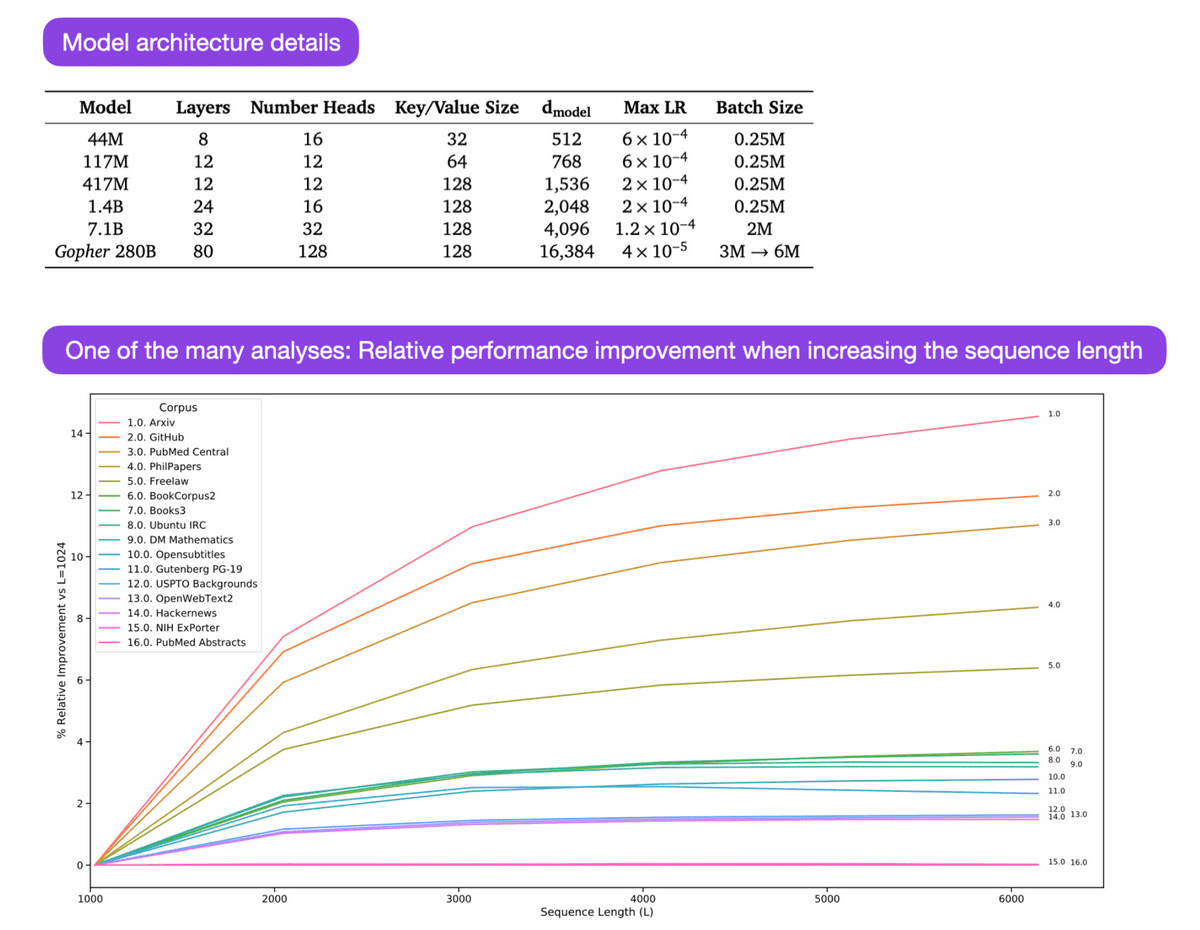
I studied how language models acquire abilities in the process of training.
This paper presents the following:
Training on duplicate data neither benefits nor harms
The order of training has no effect on memorization
・Words used many times in pre-training improve performance on related tasks
Doubling the batch size halves the training time but does not affect convergence.
・Guide the language model to the intended direction
◆17:
We introduced ``Reinforcement learning with human feedback (RLHF)'' that incorporates humans into the reinforcement learning loop. It is called the InstructGPT paper, using the name of the language model used in this paper.
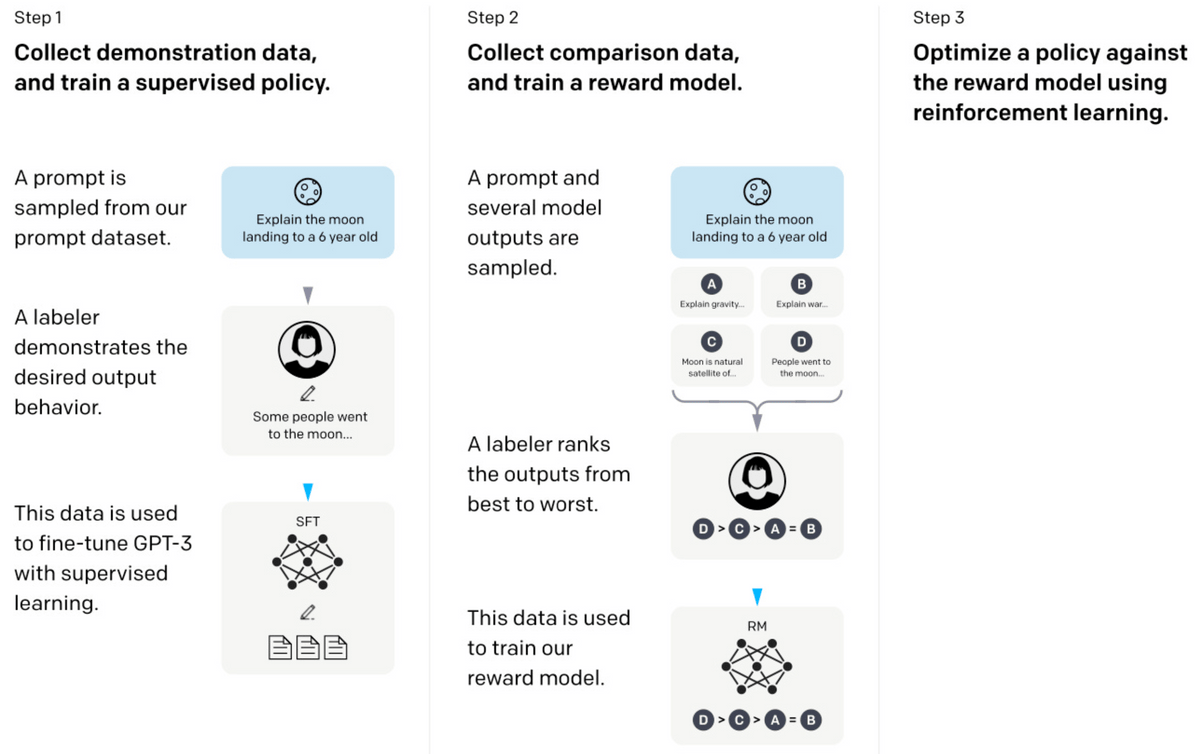
18:
We developed a rule-based self-training mechanism to create a 'harmless' AI.
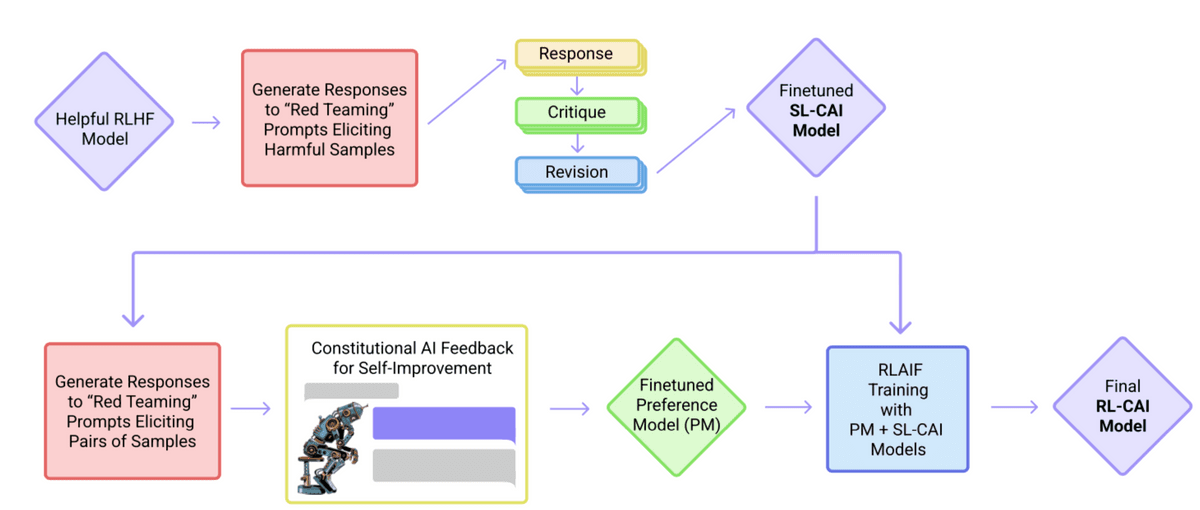
◆19:
When fine-tuning a language model, there is a problem that it is difficult to scale if humans have prepared instruction data. This paper describes a mechanism for preparing the instruction data itself in the language model. Although the performance is better than the original language model and the model trained with human-prepared data, it loses to the model that performed RLHF.
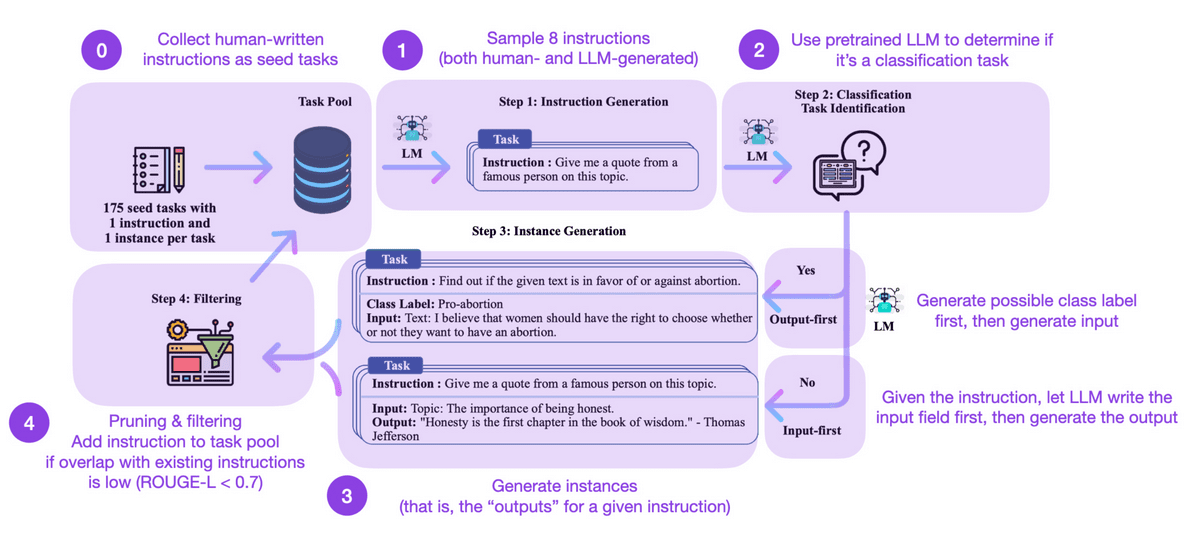
・Reinforcement learning with human feedback (RLHF)
RLHF is considered the best option available as of May 2023, Raschka said. Mr. Rashka expects that the influence of RLHF will continue to increase in the future, so he will introduce additional RLHF papers for those who want to learn more about RLHF.
◆20:
This paper introduces the policy gradient method.
◆21: Proximal Policy Optimization Algorithms (2017)
We have developed Proximal Policy Optimization (PPO), which improves the policy gradient method and increases data efficiency and scaling.
◆22: Fine-Tuning Language Models from Human Preferences (2020)
Introduced PPO to RLHF.
◆23: Learning to Summarize from Human Feedback (2022)
We created a model that achieves better results than normal supervised learning through three-step training: 'pre-learning' → 'fine-tuning' → 'PPO'.
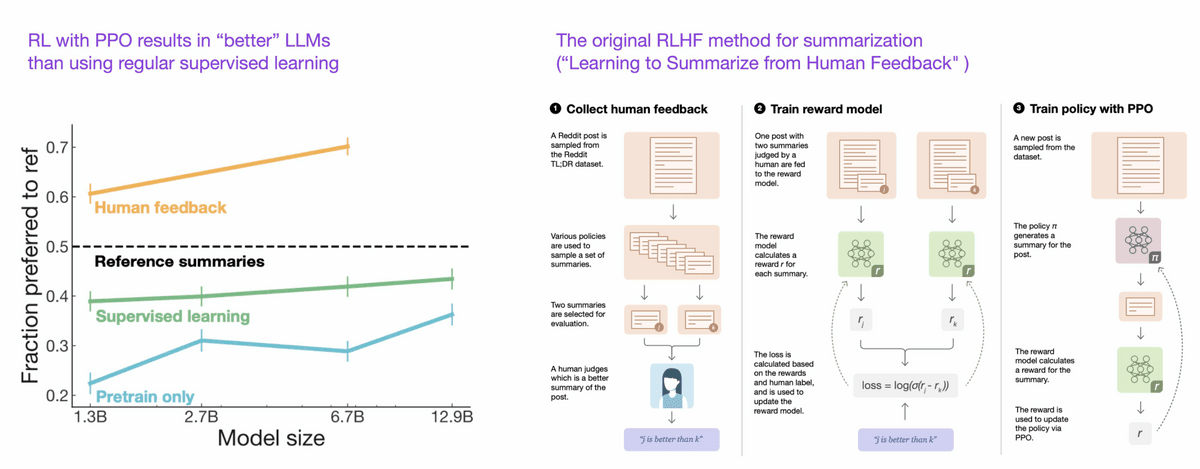
◆24: Training Language Models to Follow Instructions with Human Feedback (2022)
Paper No. 17 has reappeared. Training is performed in the same three steps as above, but text generation is emphasized instead of text summarization, and the number of evaluation options is increased.
Related Posts:






in Software, Posted by log1d_ts