What kind of language model is `` RWKV '' that removes the `` limit of input amount '' that was a constraint of the conventional large-scale language model?

Almost all large-scale language models in commercial use as of July 2023, such as ChatGPT and Bard, are models that use the transformer architecture. There is a problem that the input size is limited because the amount of calculation increases. In response to such problems, one of the authors blogs about the architecture ' RWKV ' that can achieve performance comparable to the transformer type while achieving support for large data and reduction of memory usage during inference.
The RWKV language model: An RNN with the advantages of a transformer |
How the RWKV language model works | The Good Minima
https://johanwind.github.io/2023/03/23/rwkv_details.html
RWKV is based on RNN (recurrent neural network) . RNN is a mechanism that sequentially processes the input tokens one by one and updates the state vector.

It is possible to tokenize the text and load it sequentially into a single state vector, or predict the next token based on the final result to perform the text generation task. The article below provides an easy-to-understand explanation of how text is tokenized.

Since RNN has the property of ``processing inputs one by one'', it was difficult to parallelize them on a large scale using GPUs. Therefore, instead of RNN that processes inputs sequentially, a 'transformer' that processes all input tokens simultaneously using a mechanism called 'attention' was created. Since it became possible to parallelize computation massively, even large models and datasets can be trained at high speed, resulting in many excellent large-scale language models such as ChatGPT.
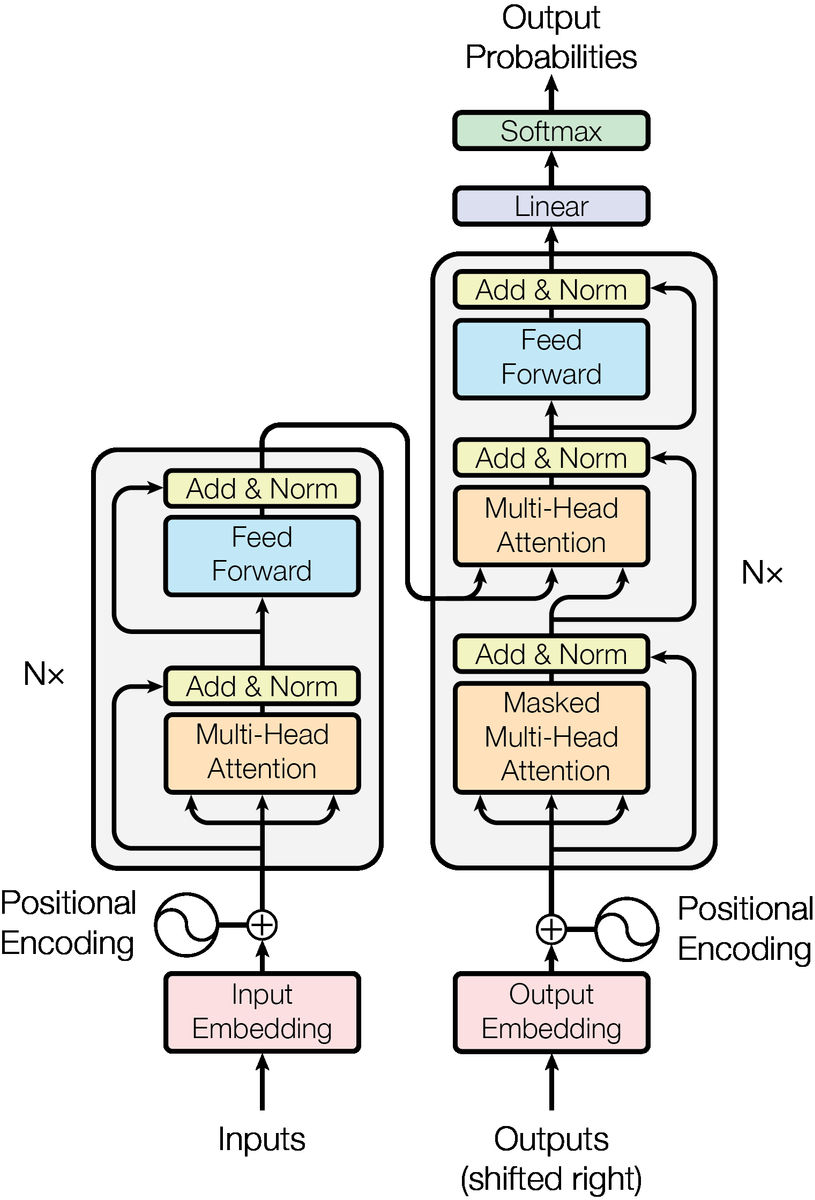
However, in calculating attention, it is necessary to calculate all pairs between input tokens, so the time required for processing is proportional to the square of the amount of input tokens, and when generating text, all tokens There are limitations on the length of the input tokens, such as the attention vector that requires a large amount of memory. On the other hand, in the case of RNN, the amount of computation is proportional to the number of input tokens to the first power, so it is possible to 'read' a fairly long sentence.
RWKV is an architecture that 'takes the best of both' that enables parallelization by simultaneously processing input tokens like a transformer, and it is also possible to perform high-speed calculation even with long inputs like RNN. About. It has a structure as shown in the figure below, and is characterized by being divided into a 'Time Mixing' block and a 'Channel Mixing' block. The name 'RWKV' of this architecture is where the R vector representing the receptivity of past information, the W vector representing the time coefficient, and the vectors similar to 'Key' and 'Value' used in attention are used. are named after their respective initials.
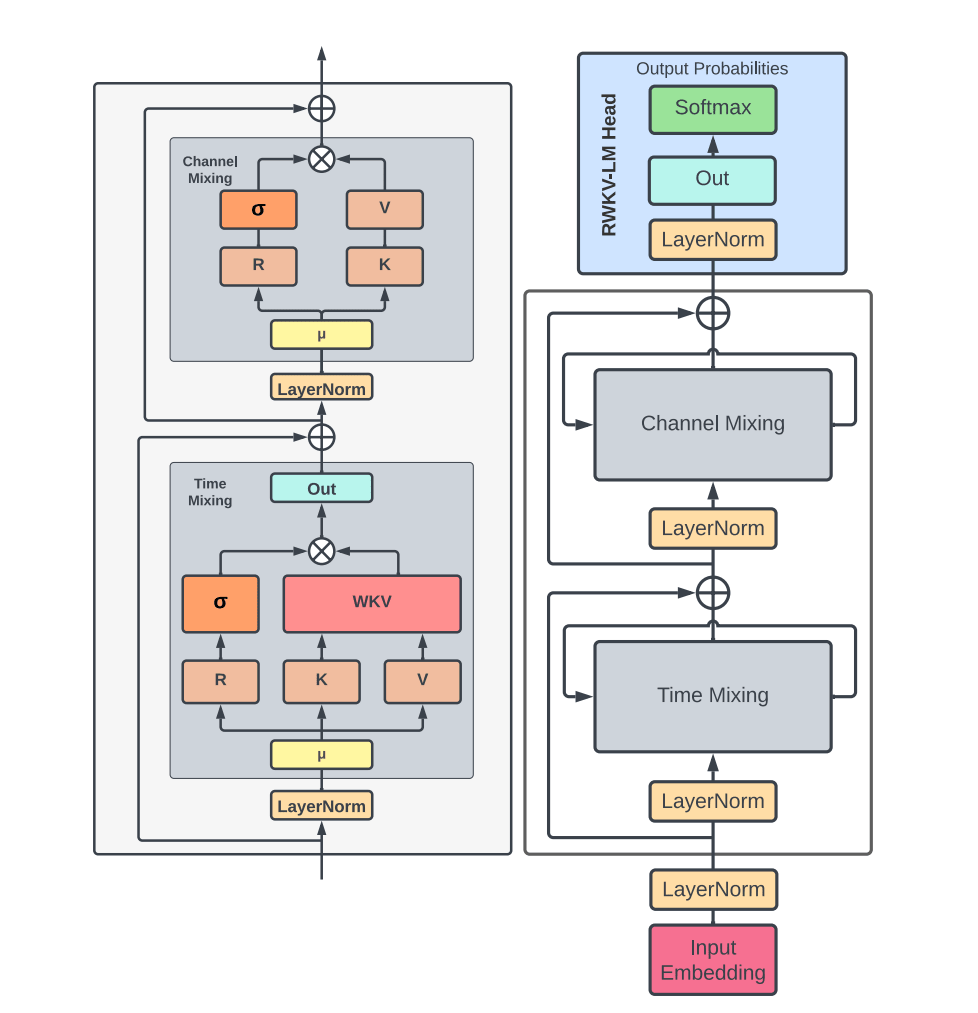
By separating layers in the structure of RWKV, it is possible to start computing the next node before the computation of the previous node of the RNN finishes. As shown in the figure below, when the calculation of the 'My→name' Time Mixing block in the leftmost column is performed, the calculation of the next 'name→is' column Time Mixing block can be started. In this way, even though it is an RNN, it enables large-scale parallelization. In addition, parallelization is performed only during learning, and memory consumption can be greatly reduced by performing sequential calculations during inference.

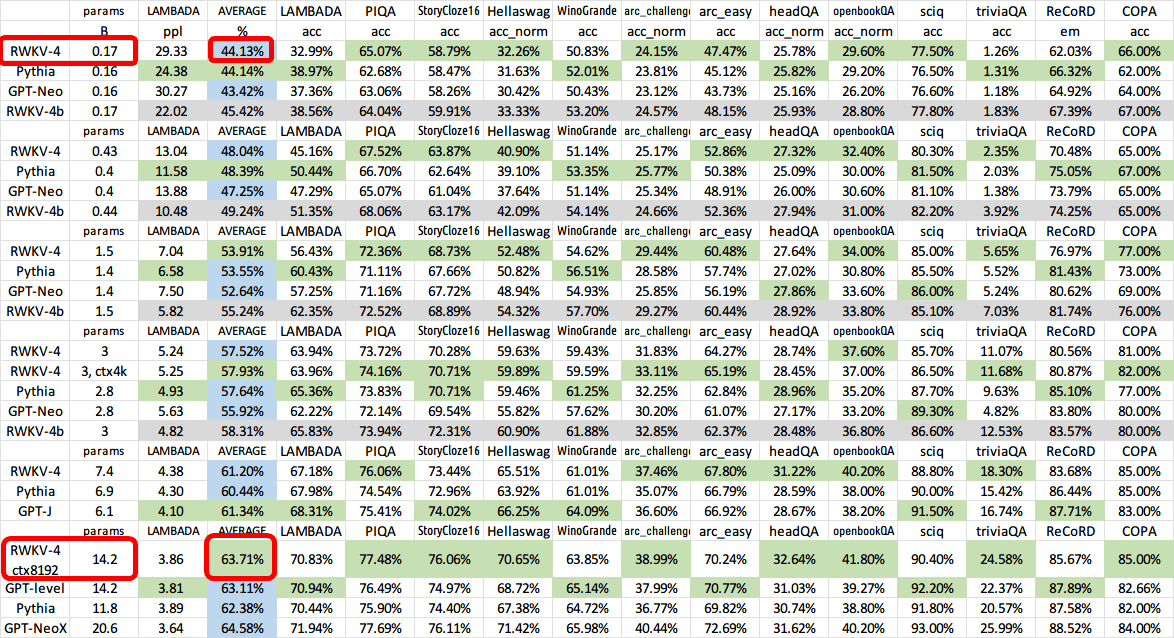
In performance evaluations using
Regarding the implementation of RWKV, Johan Wind, one of the authors of the RWKV paper, has released a minimum implementation of about 100 lines of RWKV with explanations , so if you are interested, please check it out.
Related Posts:






in Software, Posted by log1d_ts