Researchers publish information useful for enhancing large-scale language models (LLMs) with LoRA

LoRA is a mechanism that allows image generation models and large-scale language models (LLMs) to learn additional information and fine-tune the models. AI researcher
Practical Tips for Finetuning LLMs Using LoRA (Low-Rank Adaptation)
https://magazine.sebastianraschka.com/p/practical-tips-for-finetuning-llms
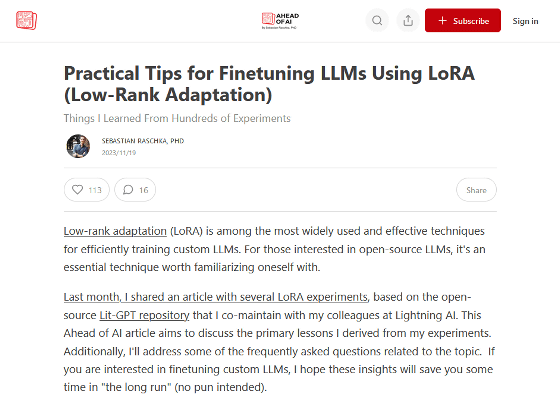
◆LoRA's effects are consistent
Below is a table showing the benchmark results when LLM ' Llama 2 ' developed by Meta was enhanced with LoRA. 'LoRA defaul 1,' 'LoRA defaul 2,' and 'LoRA defaul 3' are LoRA models created at different times, but their benchmark scores are quite similar.
◆Using QLoRA can significantly reduce VRAM usage during additional learning
QLoRA is a technology that enables additional learning with less memory consumption than LoRA. Below is a table summarizing the learning time and VRAM consumption when Mr. Rashka applied additional learning to LLM with RoLA and QRoLA. Additional training using QLoRA took 39% longer training time compared to LoRA, but consumed 33% less VRAM.
| method | LoRA | QLoRA |
|---|---|---|
| study time | 1.85 hours | 2.79 hours |
| VRAM usage | 21.33GB | 14.18GB |
Below is a table comparing the benchmark scores of LLM additionally learned with LoRA and QLoRA. There doesn't seem to be a big difference in performance whether you use LoRA or QLoRA.

The detailed mechanism of QLoRA is explained in the following article.
``QLoRA'', a method that makes it possible to train language models with a large number of parameters even with small GPU memory, has appeared, what kind of method is it? -GIGAZINE

◆Learning rate schedule is also effective for LoRA
In machine learning, it is known that a 'learning rate schedule' that adjusts the learning rate according to the progress of learning is effective. Rashka's experiments have confirmed that learning rate scheduling improves LLM performance in LoRA as well.
◆The optimization algorithm is not much different between Adam and SGD.
In machine learning, there can be a big difference in memory usage depending on the optimization algorithm, but in LoRA, there is no big difference in memory usage whether you use Adam or SGD.
◆Performance decreases when additional learning with LoRA is repeated
In machine learning, learning may be repeated many times to fine-tune the model. On the other hand, it has become clear that model performance deteriorates when learning with LoRA is repeated multiple times. Below is a table summarizing the benchmark scores of models that have been subjected to additional learning by LoRA once and those that have been subjected to two times. You can see that the performance of the model that underwent additional learning twice has decreased.

◆LoRA is more effective when applied to many layers
LoRA is said to improve performance by applying LoRA not only to a single layer but also to the projection layer and linear layer.
◆Alpha should be set to twice the Rank
When additionally learning LoRA, you can set the 'Alpha' and 'Rank' values to adjust the scaling effect. According to Rashka, the appropriate Alpha value is twice the Rank value.
◆Additional learning using LoRA can be performed on a single GPU
Developing a high-performance LLM requires large-scale computational resources, making it difficult for individuals to develop it from scratch. Additional learning using LoRA can be performed on a single GPU, so even individual developers can create their own customized LLMs.
Mr. Rashka's article also introduces a lot of useful information about RoLA in LLM.
Related Posts:





in Software, Posted by log1o_hf