Microsoft releases a 1.58-bit large-scale language model, allowing matrix calculations to be added, dramatically reducing calculation costs
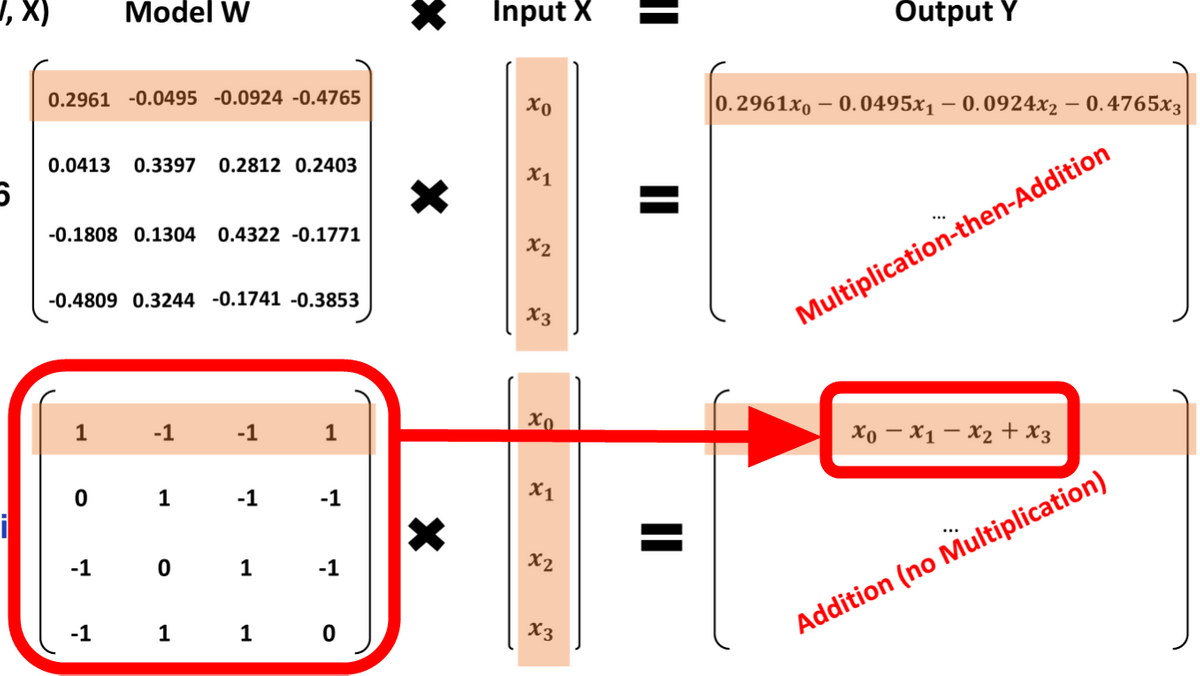
Microsoft's research team has announced that they have succeeded in drastically reducing the computational cost of large-scale language models by setting the model weights to only three values: ``-1'', ``0'', and ``1''.
[2402.17764] The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
In the conventional model, it was necessary to multiply the input by a weight such as '0.2961' and then add or subtract it, but if there are only three values, '-1', '0', and '1', no multiplication is necessary. , and all calculations can be done by addition.
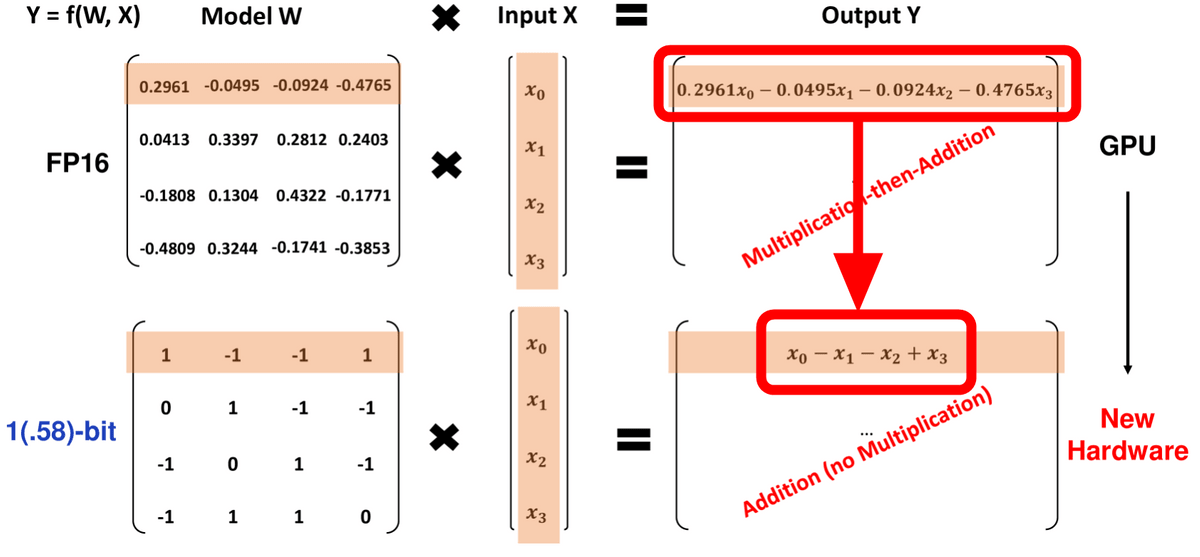
Therefore, the cost required to achieve the same performance will be drastically reduced compared to normal large-scale language models. Furthermore, since each parameter takes three values, ``-1'', ``0'', and ``1'', it is said to be a ``1.58-bit model'' based on the value of log[2](3).
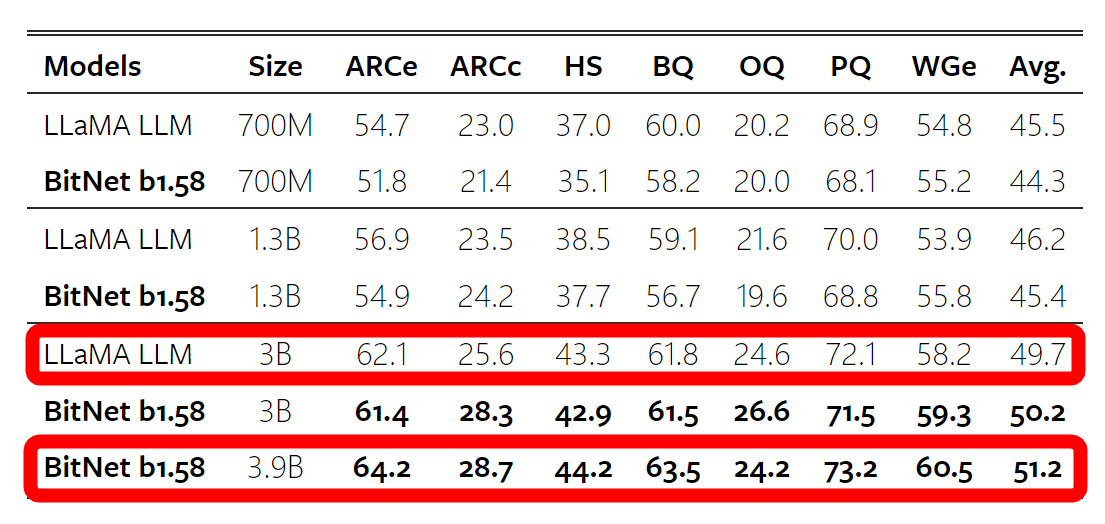
The results of comparing the performance of so-called zero shot, which processes data not included in the training data, with LLaMA in various benchmarks are shown in the figure below. BitNet's performance is equal to or lower than that of LLaMA of the same size, but BitNet's 3.9B model exceeds LLaMA's 3B model in most indicators, and by slightly increasing the model size, it can improve the performance of conventional models. It has been suggested that it is possible to maintain
It seemed like a good match in terms of performance, but BitNet won by a landslide in terms of the amount of memory required and latency. Compared to LLaMA's 3B model, BitNet's 3.9B model requires 3.32 times less memory and 2.4 times less latency.
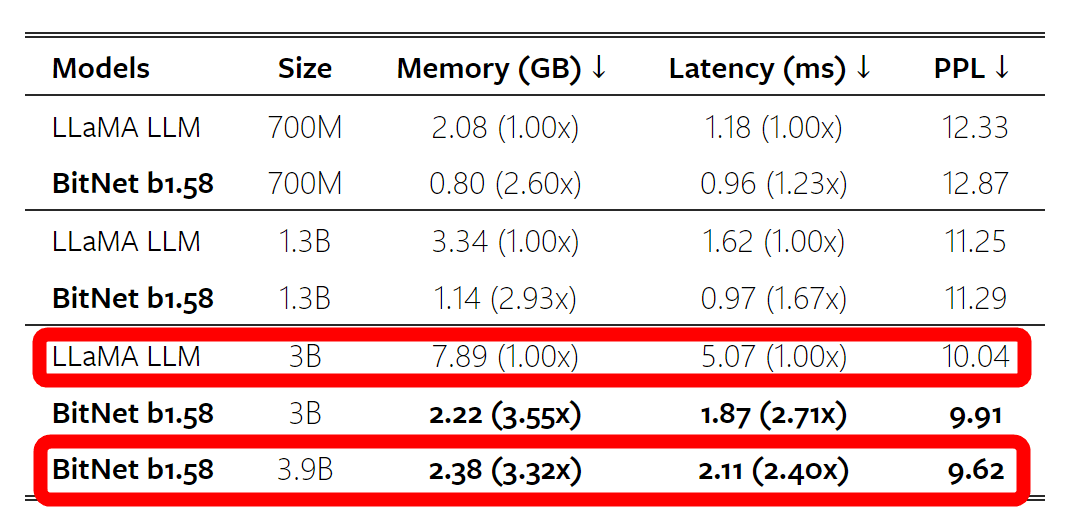
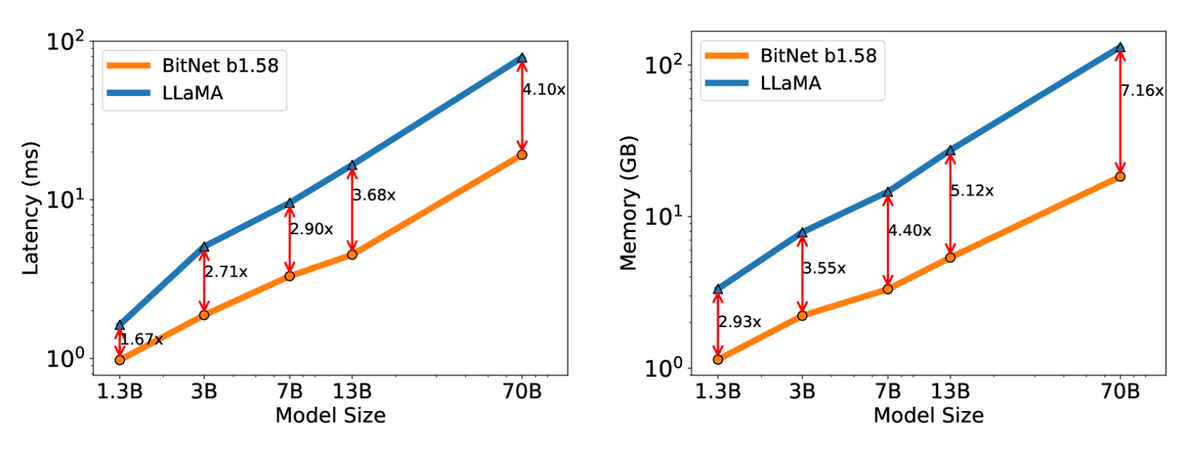
Furthermore, the difference in latency and memory consumption increases as the model size increases, and when comparing 70B models, BitNet's latency can be reduced to 4.1 times that of LLaMA, and memory consumption can be reduced to 1/7.16. thing.
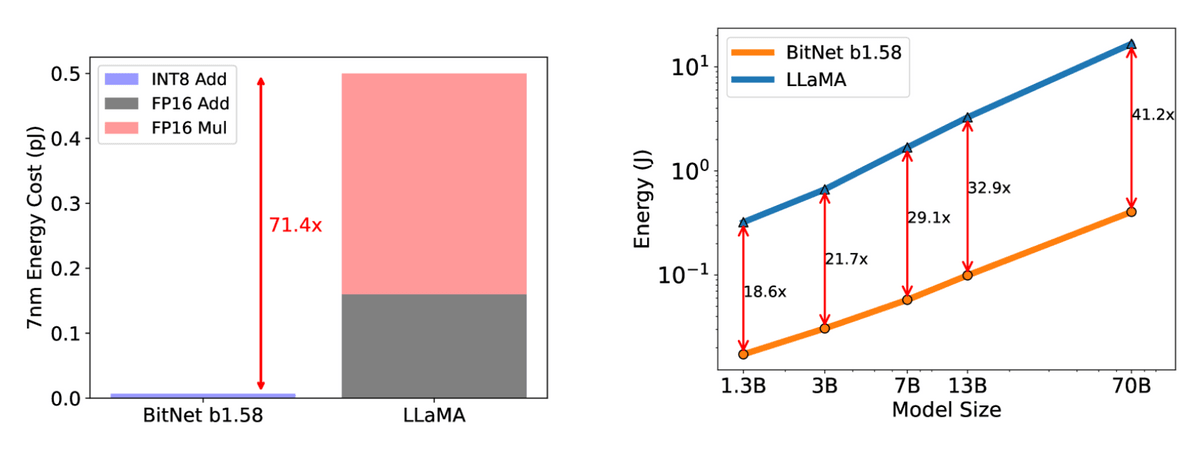
In addition, the cost of matrix operations has been drastically reduced to 1/71.4, and BitNet has succeeded in reducing the total energy consumption to 1/41.2 of LLaMA in the 70B model.
Batch size improved by 11 times and throughput increased by 8.9 times.

The benchmark after training using 2 trillion tokens is shown below, confirming that even a 1.58-bit model has strong generalization ability.

By using this method, the amount of multiplication required for matrix operations can be significantly reduced, so the paper states that it ``opens the door to new hardware designs for large-scale 1-bit language models.'' .
Related Posts:








in Software, Posted by log1d_ts