Microsoft releases small language model 'Phi-2', performance equivalent to or better than models up to 25 times the size although it is small

The language model “ Phi-2 ” announced at the event “Microsoft Ignite 2023” in November 2023 has been released. Although it is a small model with 2.7 billion parameters, it can demonstrate the same performance as a model with up to 25 times the size.
Phi-2: The surprising power of small language models - Microsoft Research
Today, we share our teams' latest contributions, Phi-2 and promptbase.
— Microsoft Research (@MSFTResearch) December 12, 2023
Phi-2 outperforms other existing small language models, yet it's small enough to run on a laptop or mobile device. https://t.co/wLhUeRsByL
'Phi' is a series of small-scale language models based on Transformer developed by the machine learning infrastructure team at Microsoft Research. The first model, Phi-1, had 1.3 billion parameters and achieved state-of-the-art performance in Python coding among existing small language models. 'Phi-1.5' is a model that improves general inference and language understanding abilities based on Phi-1, and although the number of parameters is small at 1.3 billion, it has the same performance as a model 5 times larger. .
The newly released Phi-2 is a 2.7 billion parameter model, and is said to have achieved the most advanced performance among basic language models with less than 13 billion parameters. In addition, when measuring various benchmarks, it demonstrated performance equivalent to or better than models that are up to 25 times larger. Since the model size is small, costs such as training and inference can be reduced, making it suitable for studying language models.
To get smaller models to perform as well as larger models, Microsoft focused on training data and methods. The training data used was a dataset for teaching common sense/general knowledge such as science, daily life, and psychology, and a web dataset carefully filtered based on educational value and content quality. Additionally, by first training Phi-1.5 and transferring that knowledge to Phi-2, we succeeded in accelerating training convergence and improving benchmark scores. The amount of training data was 1.4 trillion tokens, and training was conducted over 14 days using 96 NVIDIA A100 GPUs.
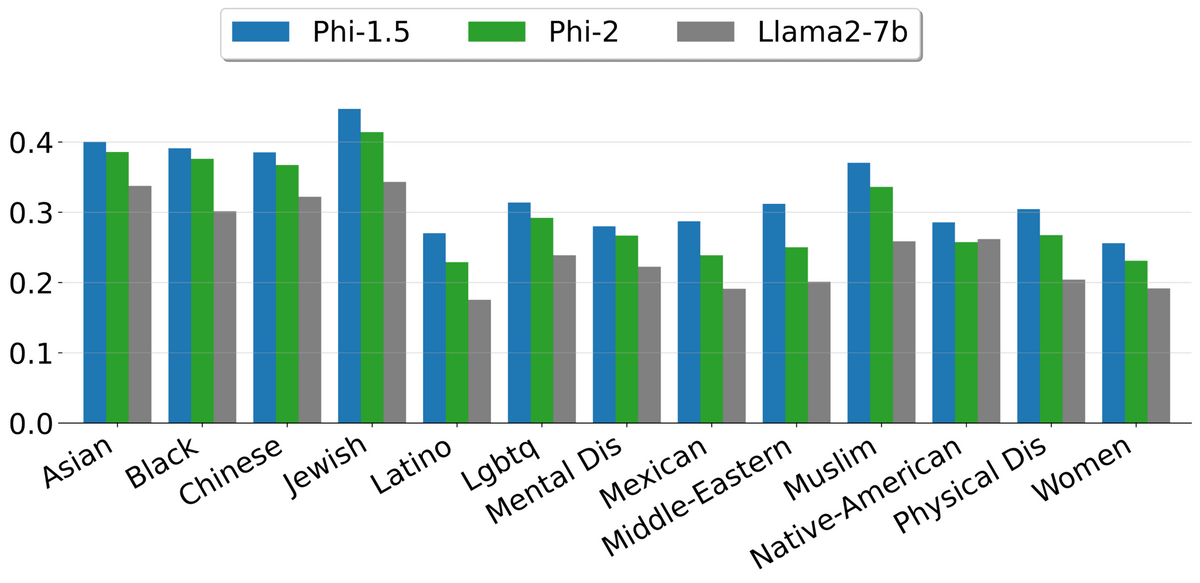
The figure below shows the safety score calculated based on ToxiGen, and the higher the score, the easier it is to generate harmless sentences. Although Phi-2 is a base model that has not been adjusted by
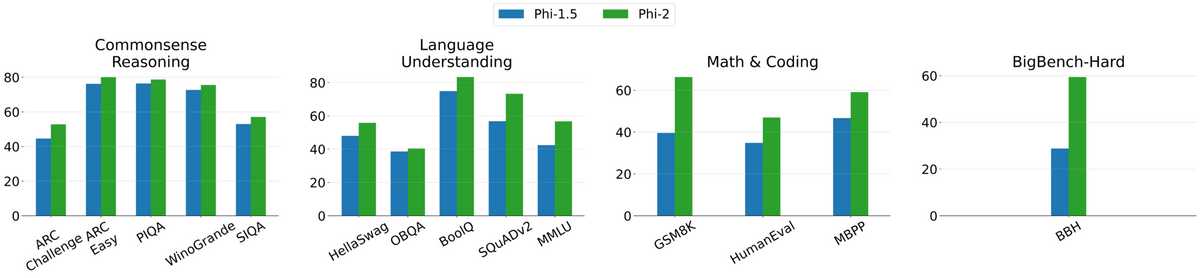
Benchmark results compared with other models are as follows. Phi-2 has demonstrated particularly good performance in reasoning tasks that require multiple steps, such as programming and mathematics.
| model | size | BBH | common sense reasoning | language understanding | Math | programming |
|---|---|---|---|---|---|---|
| Llama-2 | 7B | 40.0 | 62.2 | 56.7 | 16.5 | 21.0 |
| 13B | 47.8 | 65.0 | 61.9 | 34.2 | 25.4 | |
| 70B | 66.5 | 69.2 | 67.6 | 64.1 | 38.3 | |
| Mistral | 7B | 57.2 | 66.4 | 63.7 | 46.4 | 39.4 |
| Phi-2 | 2.7B | 59.2 | 68.8 | 62.0 | 61.1 | 53.7 |
A comparison with 'Gemini Nano 2', the smallest model of Gemini that appeared on December 6, 2023, is shown in the figure below. It can be confirmed that Phi-2 has performance equal to or better than Gemini Nano 2.
| Model | Size | BBH | BoolQ | MBPP | MMLU |
|---|---|---|---|---|---|
| Gemini Nano 2 | 3.2B | 42.4 | 79.3 | 27.2 | 55.8 |
| Phi-2 | 2.7B | 59.3 | 83.3 | 59.1 | 56.7 |
As per the benchmark, it seems that simple physics problems can be solved without difficulty. I was also able to calculate the square root almost accurately.

Please note that Phi-2 is provided under a license for research use only, so commercial use is not possible.
Related Posts:







in Software, Posted by log1d_ts