




ChatGPTを支えた高品質AI作成手法「RLHF」の中身はこんな感じ、面倒なデータ入力・整理はオープンソースでセルフホスト可能なプラットフォーム「Argilla」が便利

RLHFとは「人間の評価による強化学習」のことで、大規模言語モデルをChatGPTなどの実用レベルに至る品質にまで高めた実績のある手法です。RLHFでは教師データを作成したり、大規模言語モデルの回答を評価したりする際に人間がデータを入力する必要があり、特に複数人で作業する場合にデータの管理が大変になってしまうものですが、そうしたRLHF用データの入力や管理を行ってくれるプラットフォームが「Argilla」です。
Bringing LLM Fine-Tuning and RLHF to Everyone
https://argilla.io/blog/argilla-for-llms/
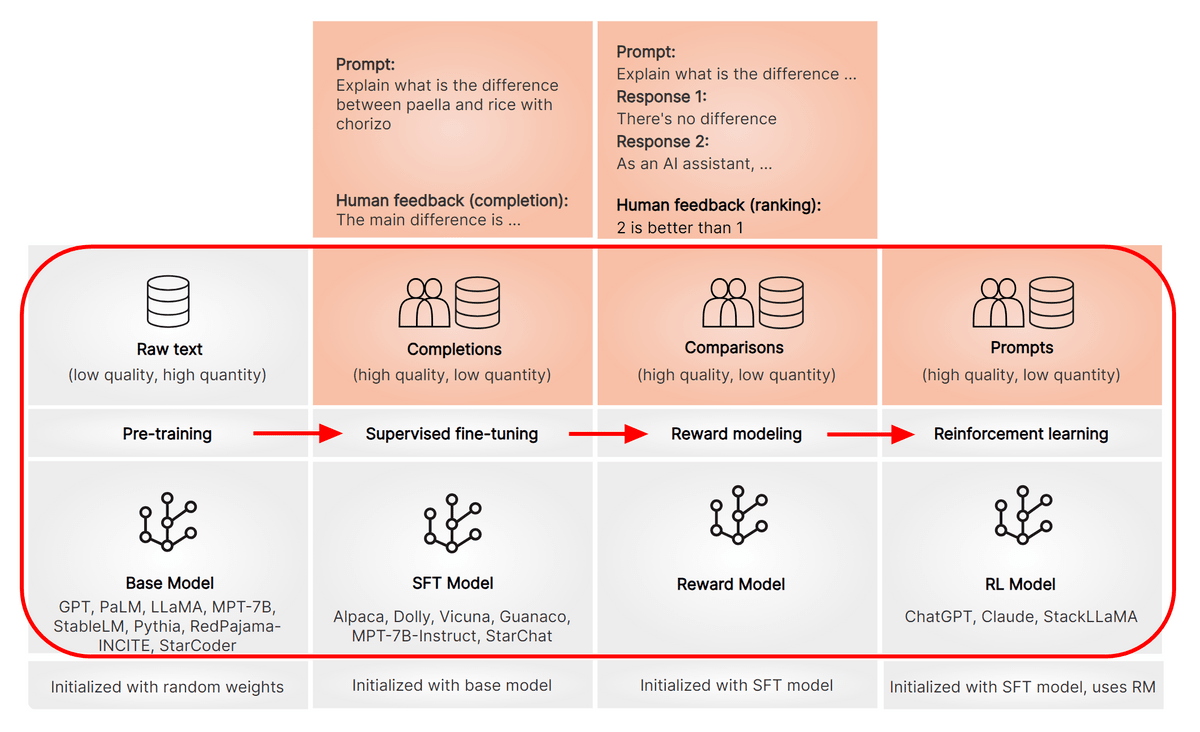
大規模言語モデルを作成する時の手順を示したのが下の図です。まず大量のテキストを用いて事前学習を行います。こうして作成されたモデルが事前学習済みモデルで、GPTやPaLM、LLaMAなどのモデルがこのカテゴリに属しています。この状態でも文章を作成することは可能ですが、さらに品質を高めるために「教師ありファインチューニング」「報酬モデル作成」「報酬モデルによる強化学習」というトレーニングを積み重ねていくというわけ。段階に応じて適切なトレーニングを積み重ねていくことでChatGPTのような高品質な大規模言語モデルが作成できます。
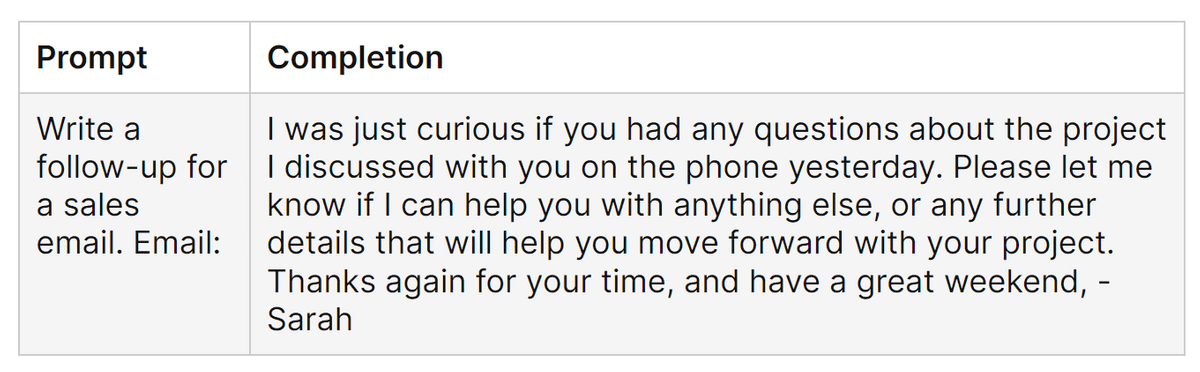
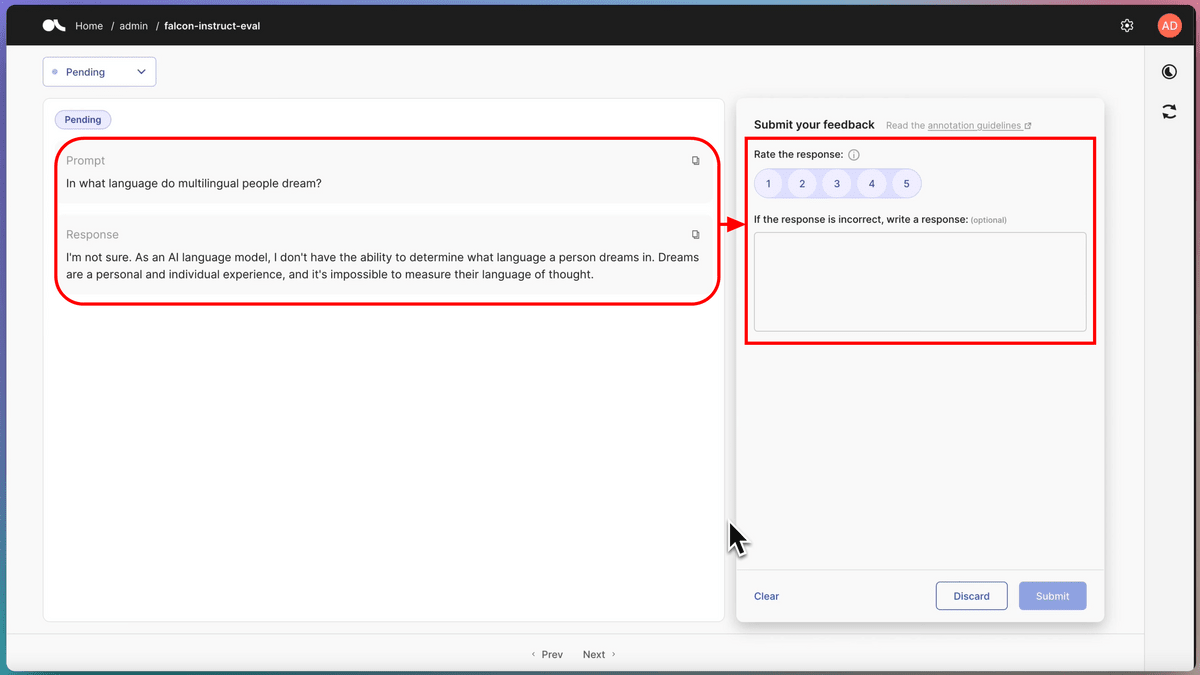
「教師ありファインチューニング」ではモデルに「どのような形式で回答するのが適切か」を学ばせることができます。例えば、事前学習済みモデルであるFalcon-7Bに「営業のフォローアップメールを書いて」と命令すると、下図のようなただの文章が返ってきます。
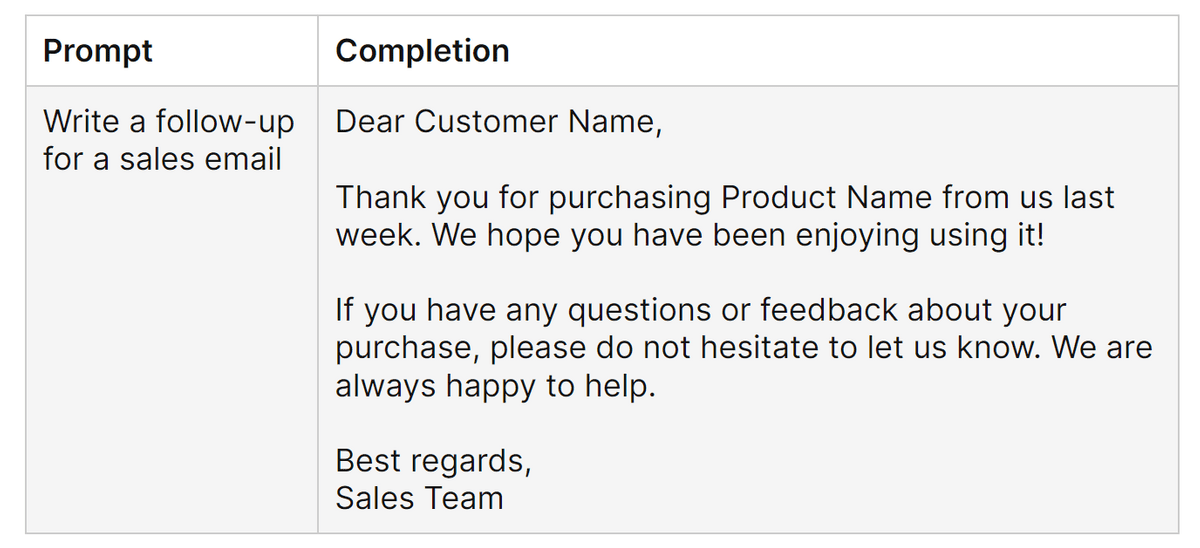
一方、Falcon-7Bにファインチューニングを行ったのちに同様の命令を行うと下図の通りに。一般的なメールの形式に沿った上で、言葉遣いも「顧客向けのメール文面に適したもの」に修正されています。
上記のようにファインチューニングは非常に効果的な手法なのですが、大規模言語モデルの品質を高めるためにはただ多くのデータを集めれば良いというわけではなく、多様ながらも一貫している高品質データを用意することが大切という研究結果が出ています。そのため、ファインチューニングの教師データは下記のような手順で人間が高品質なものを用意する必要があるとのこと。
1:データセットの形式を策定する
2:質問データベースから教師データとして利用する質問を選ぶ
3:人間が適切な回答を作成・編集する
4:データの形式を整える
5:ファインチューニングする
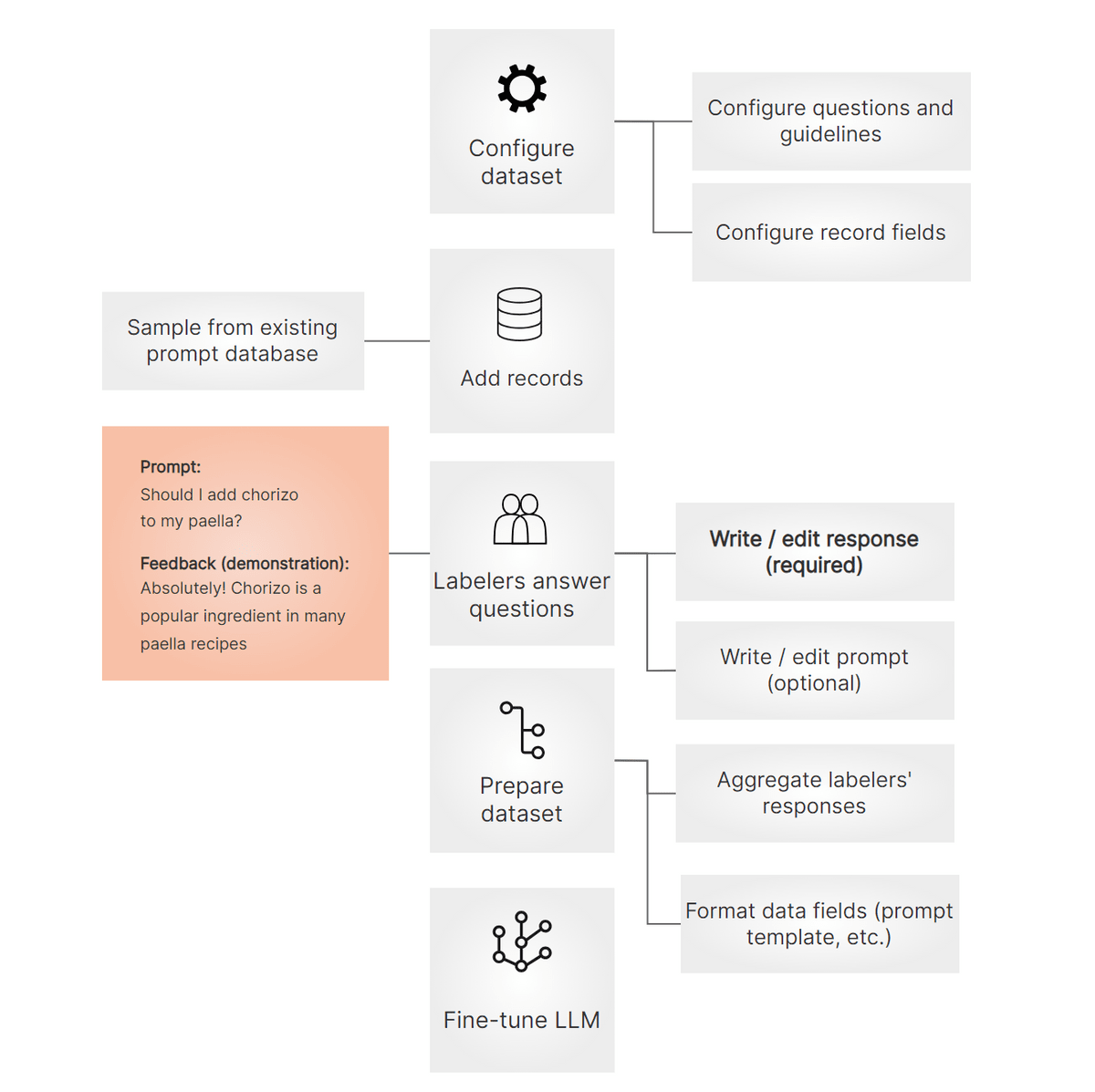
Argillaは上記のようなトレーニング用データの管理を行ってくれるプラットフォームです。特に「人間が適切な回答を作成・編集する」の部分では分かりやすいUIが用意されており、簡単に入力できるようになっています。Argillaを利用すると、1人でデータを作成する場合だけでなく、少人数で完全に担当を分ける場合や、逆に多くの人に協力してもらって質問ごとにいくつかの回答を用意する場合などさまざまな状況に簡単に対応できるとのこと。
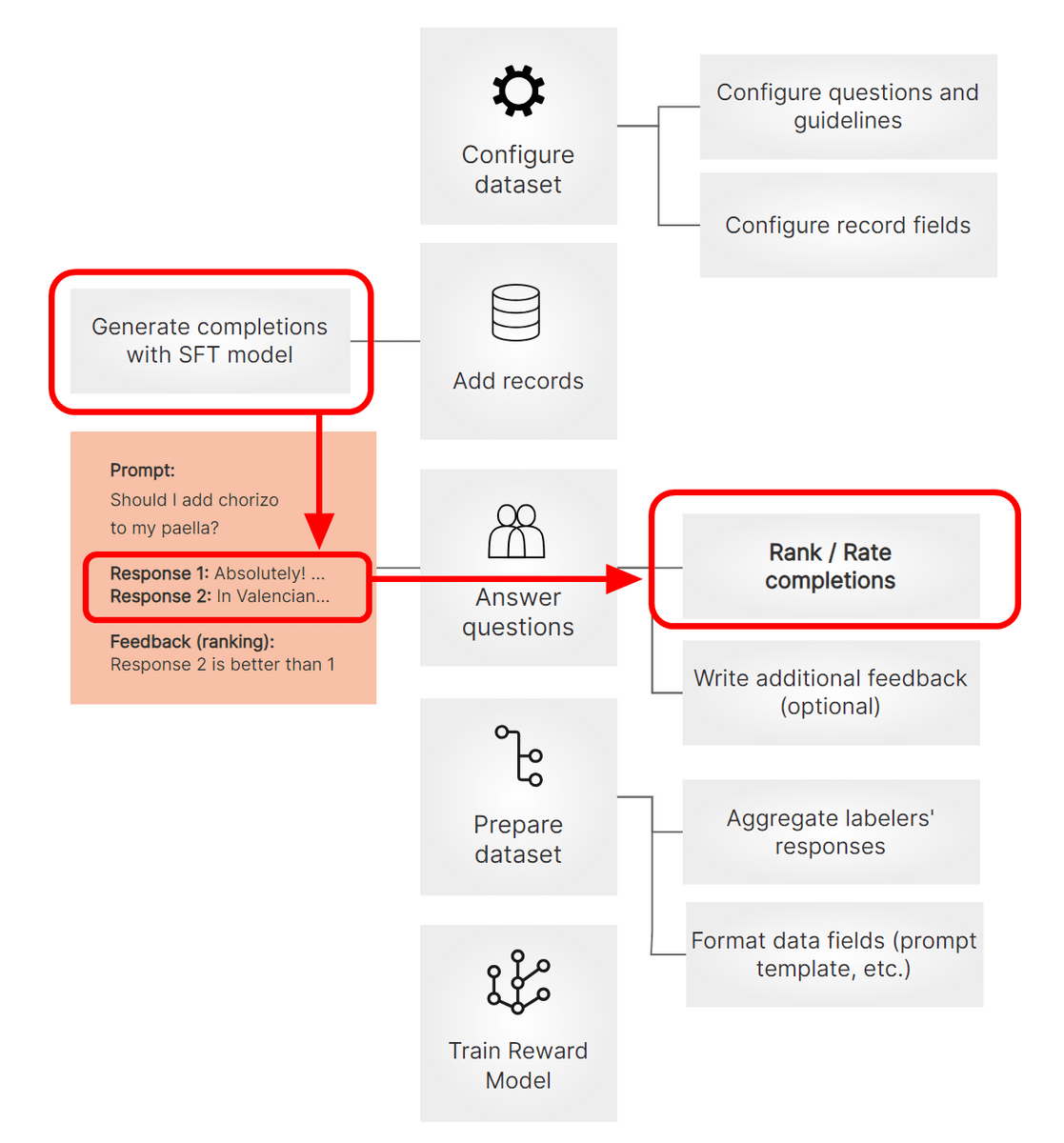
ファインチューニングの次は「報酬モデル作成」を行います。ファインチューニングとの主な違いは下図の赤枠部分の通りで、ファインチューニング済みのモデルから複数の回答を出力させて「どちらの回答がより適切か」を人間が評価しています。このデータで大規模言語モデルを直接トレーニングするのではなく、一度「報酬モデル」と呼ばれる大規模言語モデルの回答評価用のモデルを作成し、その報酬モデルが高い評価を与える回答をするように大規模言語モデルをトレーニングします。こうしてChatGPTのような高品質な大規模言語モデルが作成されるというわけです。
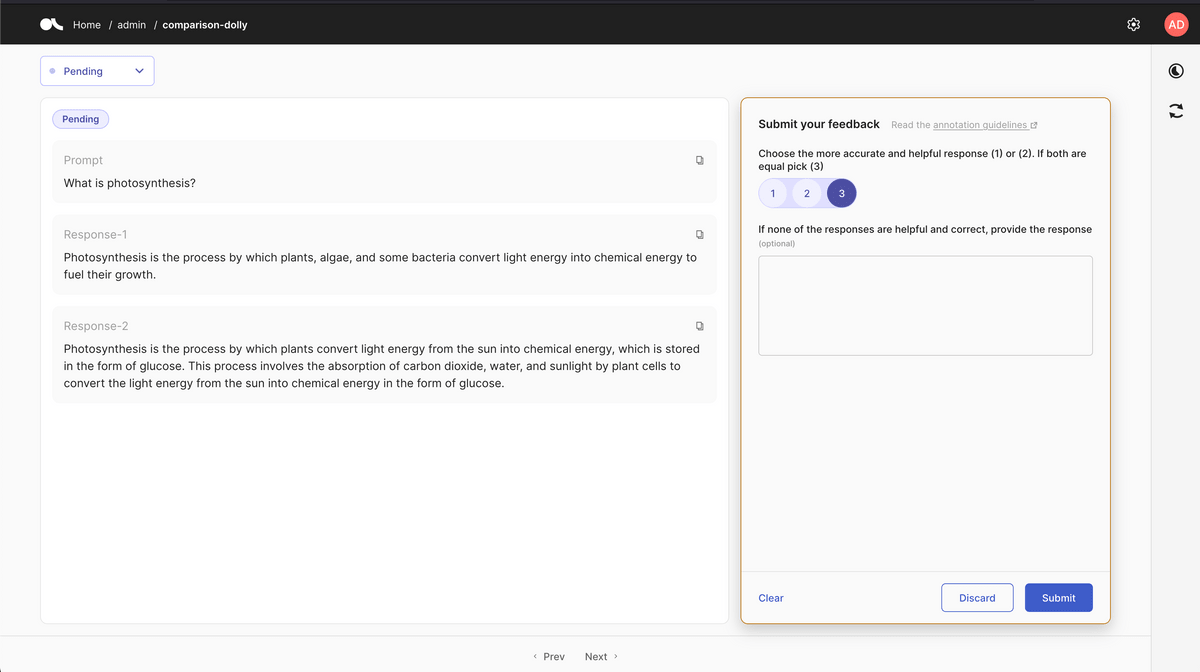
もちろん、Argillaは報酬モデル作成用の評価の入力においてもシンプルで分かりやすいUIを提供してくれます。
ArgillaのコードはGitHubにて公開されており、Dockerのコマンド一発でセルフホストすることが可能になっています。また、フルマネージドなArgillaのクラウドサービスが展開される見込みで、記事作成時点では早期アクセスの申し込みを受付中となっていました。
・関連記事
独自のデータセットでGPTのような大規模言語モデルを簡単にファインチューニングできるライブラリ「Lit-Parrot」をGoogle Cloud Platformで使ってみた - GIGAZINE
人間による評価をシミュレートすることで高速&安価にチャットAIの学習を進められるツール「AlpacaFarm」がスタンフォード大学のチームによって作成される - GIGAZINE
ChatGPTなどの大規模言語モデルはどんな理論で成立したのか?重要論文24個まとめ - GIGAZINE
ChatGPTをオープンソースで再現、わずか1.6GBのGPUメモリですぐに使用でき7.73倍高速なトレーニングが可能 - GIGAZINE
GPUメモリが小さくてもパラメーター数が大きい言語モデルをトレーニング可能になる手法「QLoRA」が登場、一体どんな手法なのか? - GIGAZINE
・関連コンテンツ






in ソフトウェア, Posted by log1d_ts
You can read the machine translated English article The content of the high-quality AI creat….