The content of the high-quality AI creation method ``RLHF'' that supported ChatGPT looks something like this, and the troublesome data entry and organization is convenient for the open source and self-hostable platform ``Argilla''

RLHF stands for 'reinforcement learning by human evaluation', and is a proven method that has improved the quality of large-scale language models to the level of practical use such as ChatGPT. In RLHF, humans need to input data when creating training data and evaluating answers of large-scale language models, and data management becomes difficult especially when working with multiple people. However, the platform that allows us to input and manage such data for RLHF is ' Argilla '.
Bringing LLM Fine-Tuning and RLHF to Everyone
https://argilla.io/blog/argilla-for-llms/
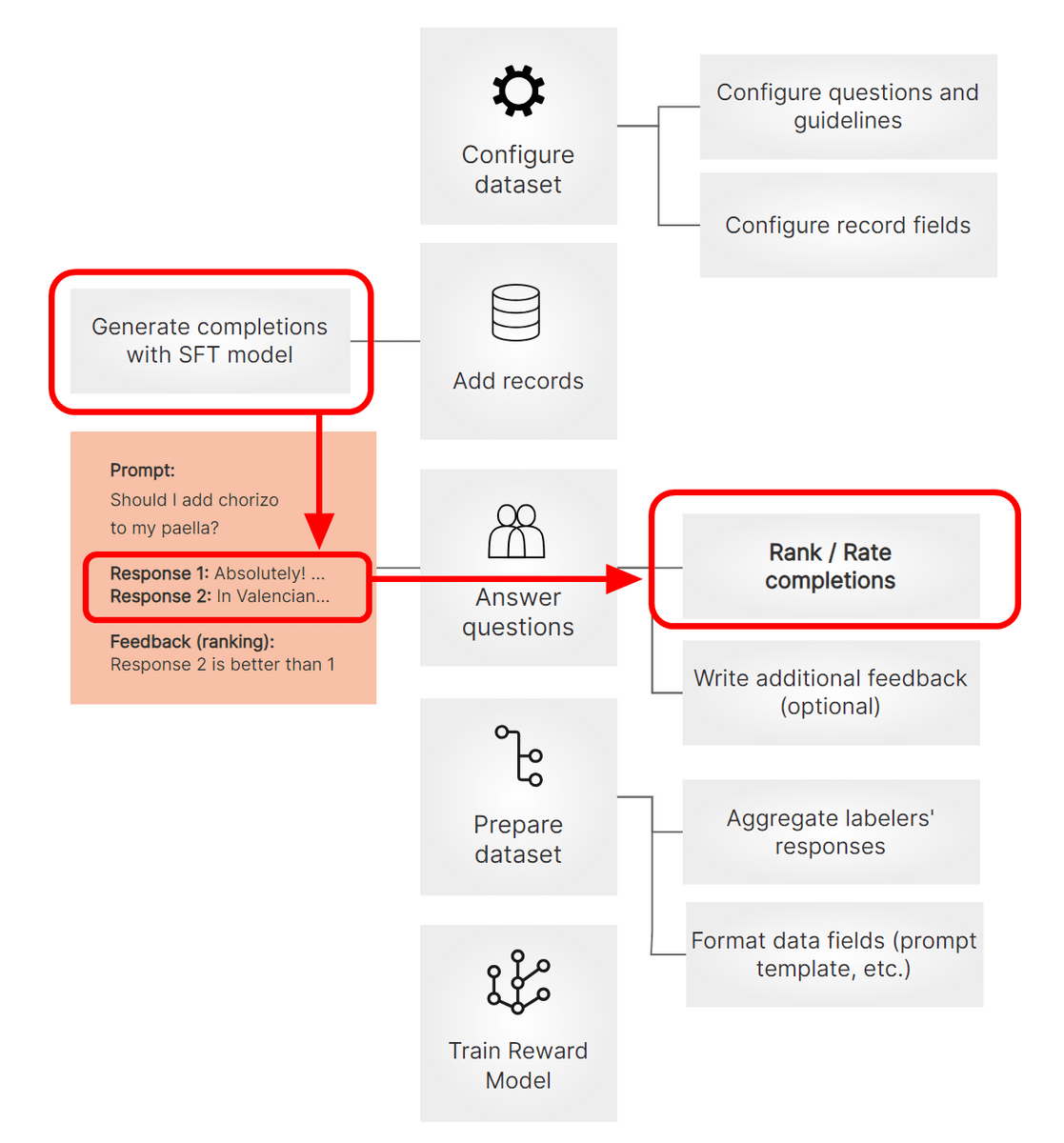
The figure below shows the procedure for creating a large-scale language model. First, pre-training is performed using a large amount of text. The models created in this way are pretrained models, and models such as GPT, PaLM, andLLaMA belong to this category. It is possible to create sentences even in this state, but in order to further improve quality, we will accumulate training called 'supervised fine tuning', 'reward model creation', and 'reinforcement learning with reward model'. By accumulating appropriate training according to the stages, a high-quality large-scale language model like ChatGPT can be created.
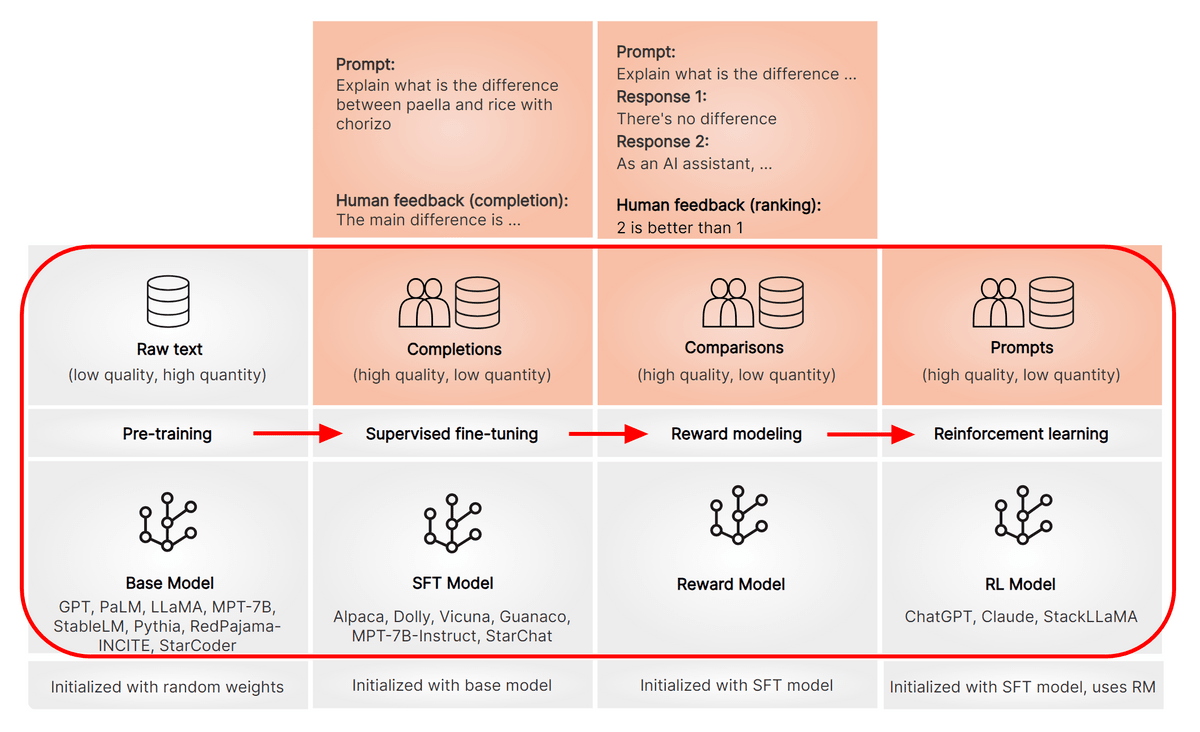
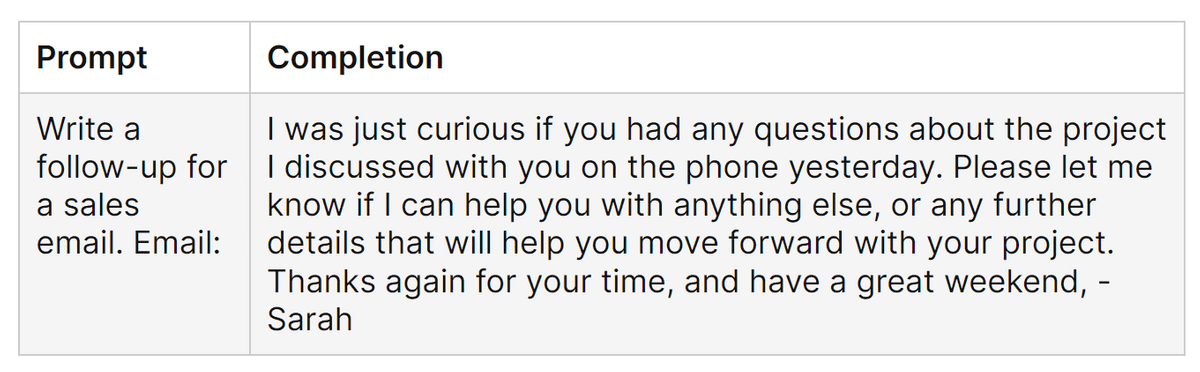
'Supervised fine-tuning' allows the model to learn 'what format is appropriate for answering'. For example, if you instruct the pre-trained model
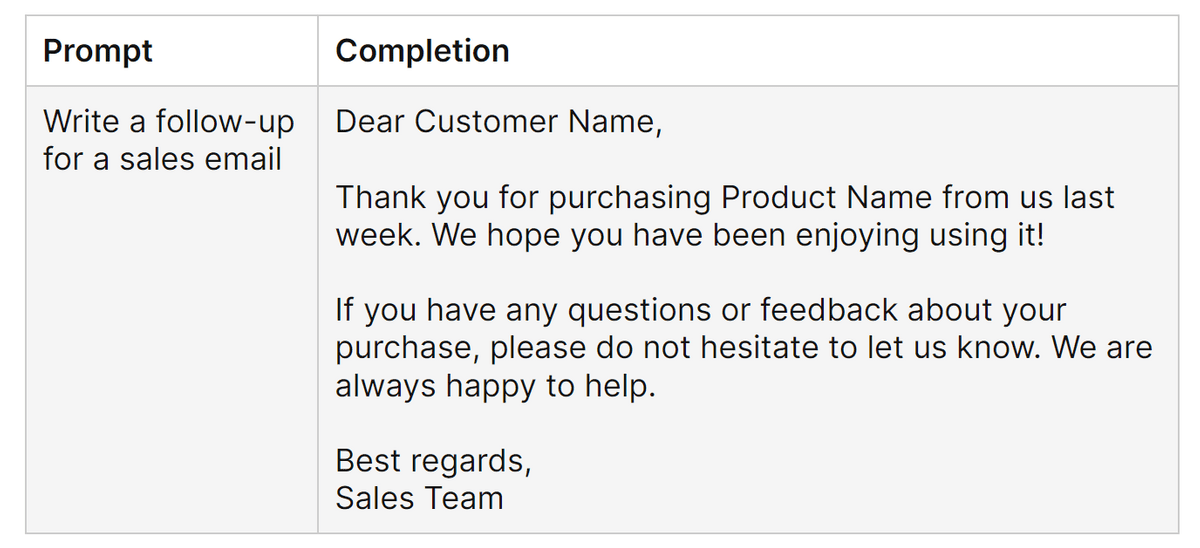
On the other hand, after performing fine tuning on Falcon-7B, if the same instruction is executed, it will be as shown in the figure below. In line with the format of general emails, the wording has also been modified to ``appropriate for customer emails''.
As mentioned above, fine-tuning is a very effective technique.
1: Formulate the format of the dataset
2: Select a question to use as teacher data from the question database
3: Humans create and edit appropriate answers
4: Format the data
5: Fine tune
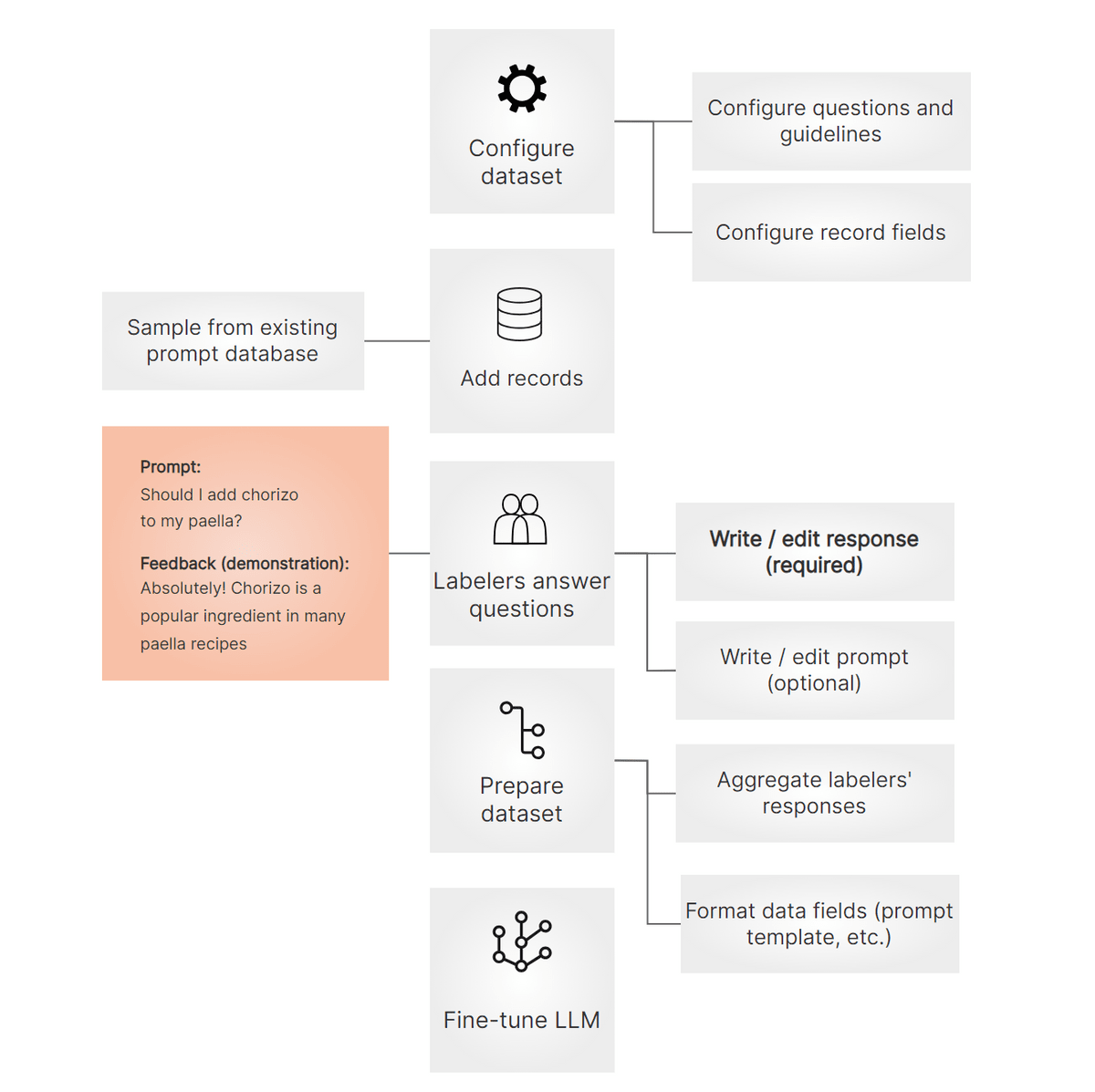
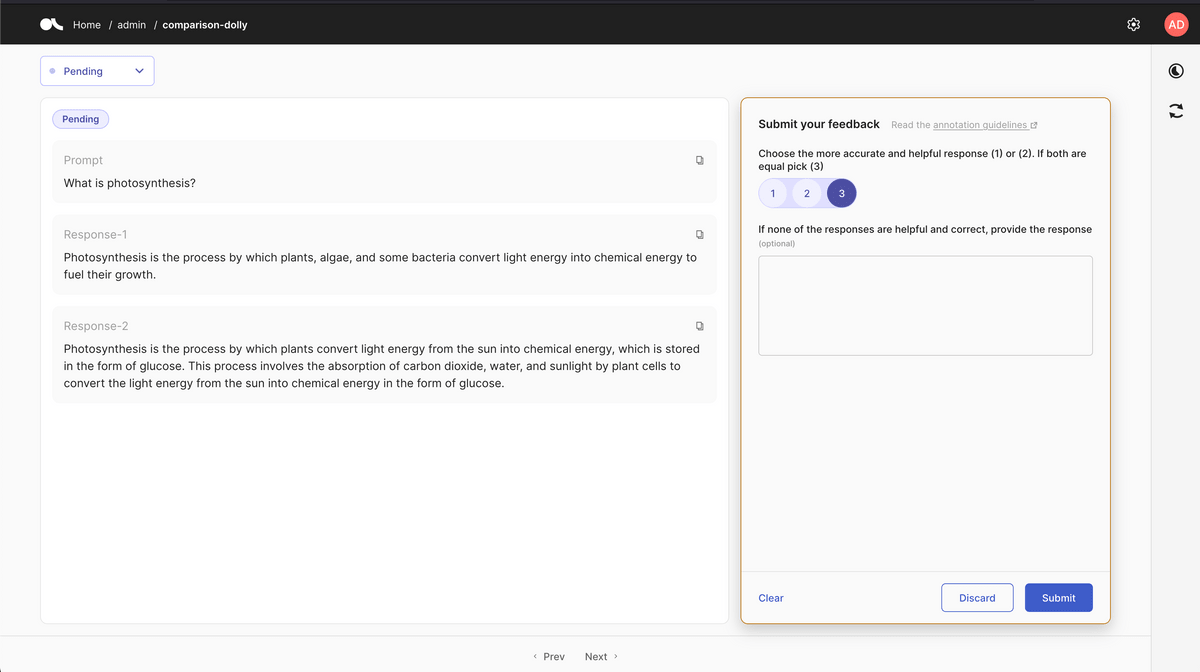
Argilla is a platform that manages the above training data. In particular, an easy-to-understand UI is prepared for the part 'humans create and edit appropriate answers', making it easy to input. Argilla can be used not only when creating data by one person, but also when a small number of people are in charge of the work, or conversely, when many people cooperate and prepare several answers for each question. It is said that it can easily respond to various situations.
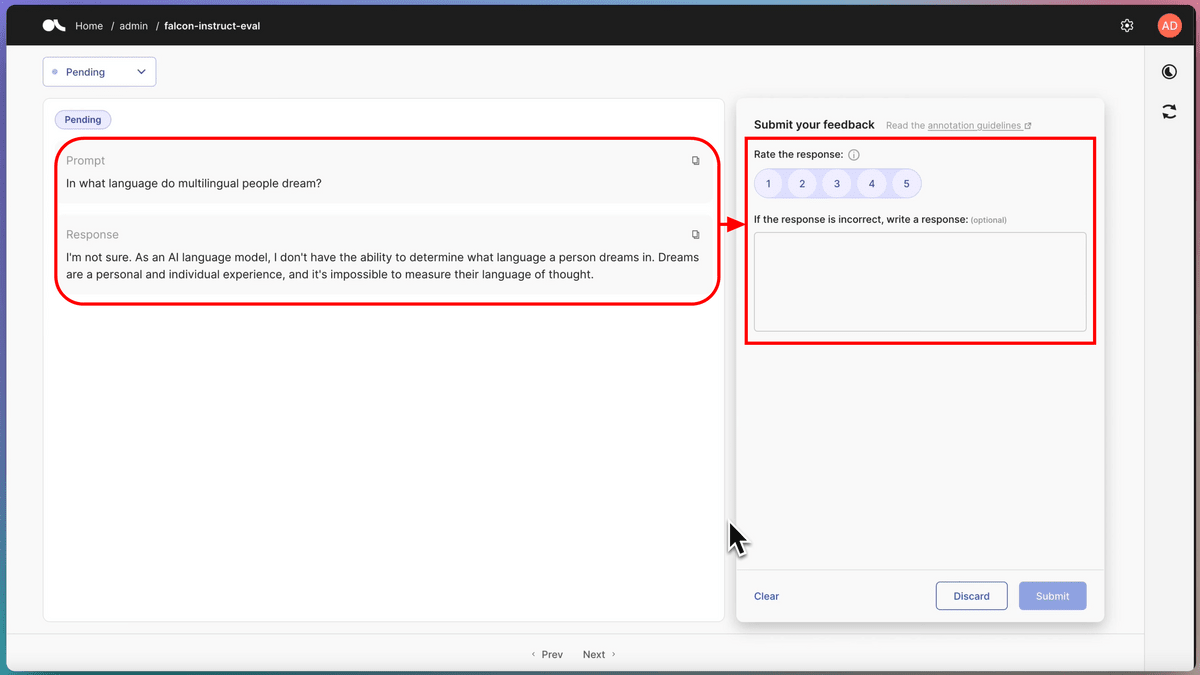
After fine-tuning, create a reward model. The main difference from fine-tuning is as shown in the red frame in the figure below, where a human evaluates 'which answer is more appropriate' by outputting multiple answers from the fine-tuned model. Rather than directly training a large language model on this data, we create a model for answer evaluation of the large language model once called the “reward model”, and then train the large scale language model to give answers that give high marks. Train a scale language model. In this way, a high-quality large-scale language model like ChatGPT is created.
Of course, Argilla also provides a simple and straightforward UI for inputting ratings for reward model creation.
Argilla's code is published on GitHub , and it is possible to self-host with a single Docker command. In addition, it is expected that a fully managed Argilla cloud service will be deployed , and applications for early access were being accepted at the time of writing the article.
Related Posts:





in Software, Posted by log1d_ts