A team at Stanford University creates 'AlpacaFarm', a tool that allows fast and inexpensive chat AI learning by simulating human evaluation
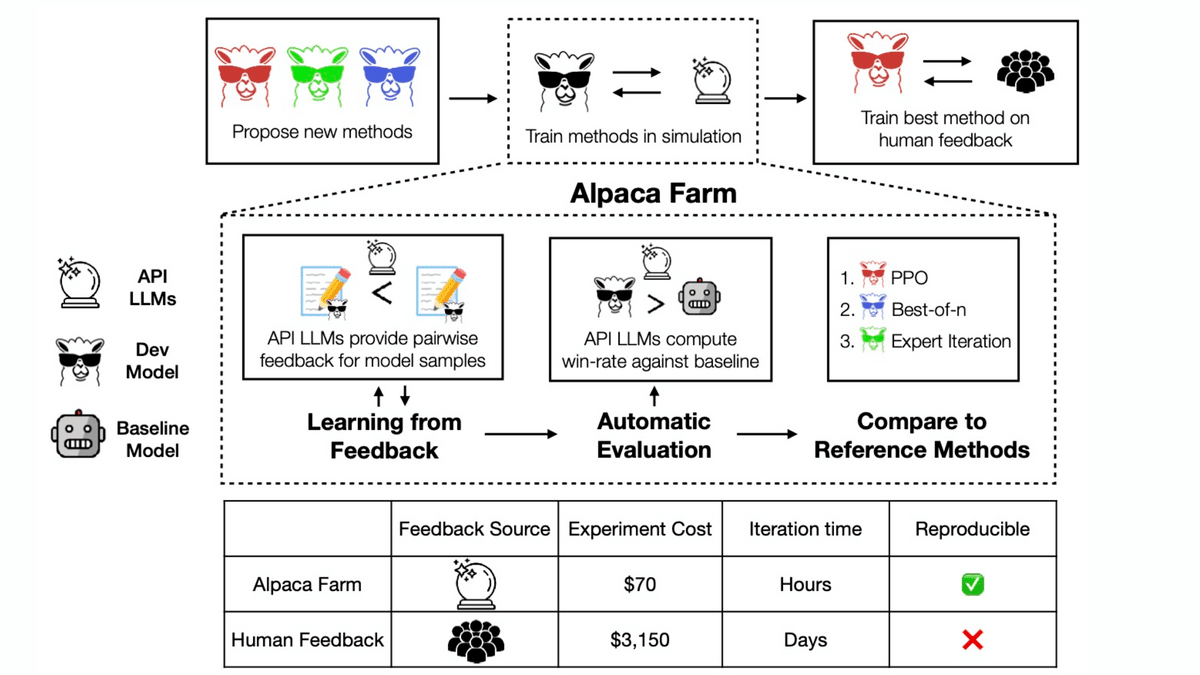
In the training of large-scale language models, 'Reinforcement Learning from Human Feedback ( RLHF )' is performed, which reflects evaluations by actual humans in the output of the model. However, since RLHF uses real people, there are drawbacks such as the cost of paying compensation and the time it takes to collect feedback. ' AlpacaFarm ' is a tool that allows you to proceed with RLHF at a low cost and at high speed by simulating 'what kind of evaluation humans return'.
Stanford CRFM
(PDF)AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback
https://tatsu-lab.github.io/alpaca_farm_paper.pdf
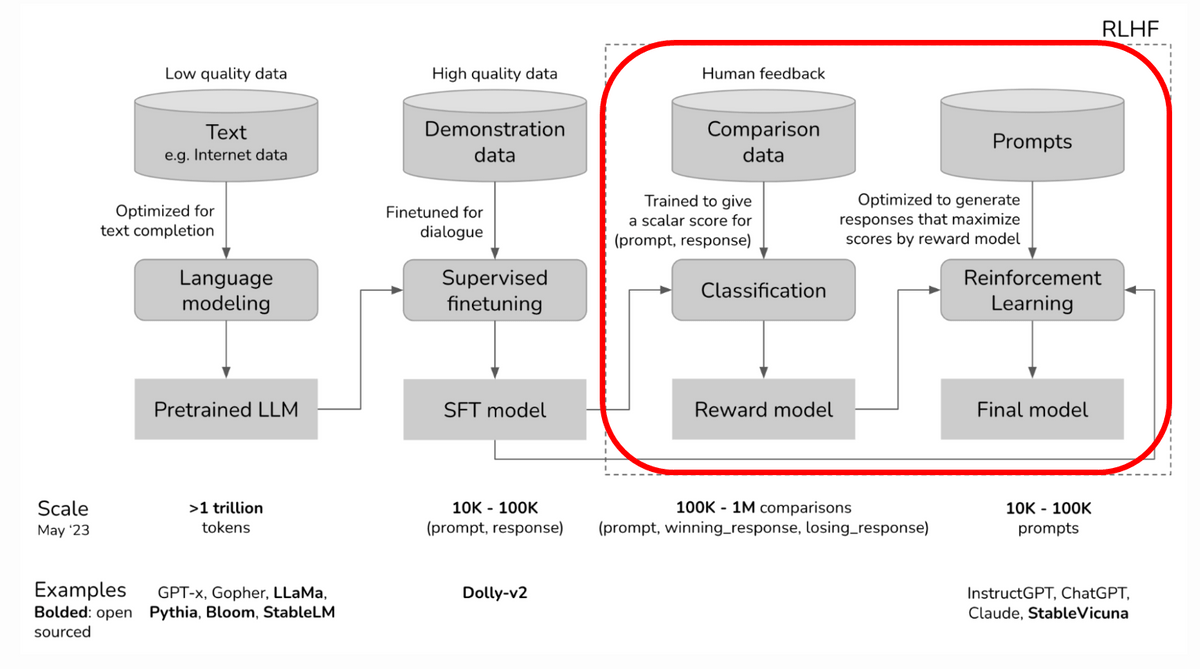
The training of a large-scale language model proceeds in the steps shown in the figure below. First, we train a model with a large amount of text to create a 'Pretrained LLM', and then perform 'supervised fine-tuning' using model data to create an 'SFT model'. On top of this, RLHF is used to further improve accuracy.
AlpacaFarm has three functions: ``evaluate the model's response'', ``comparatively evaluate the reference model and the new model'', and ``provide a comparison with the reference implementation''.
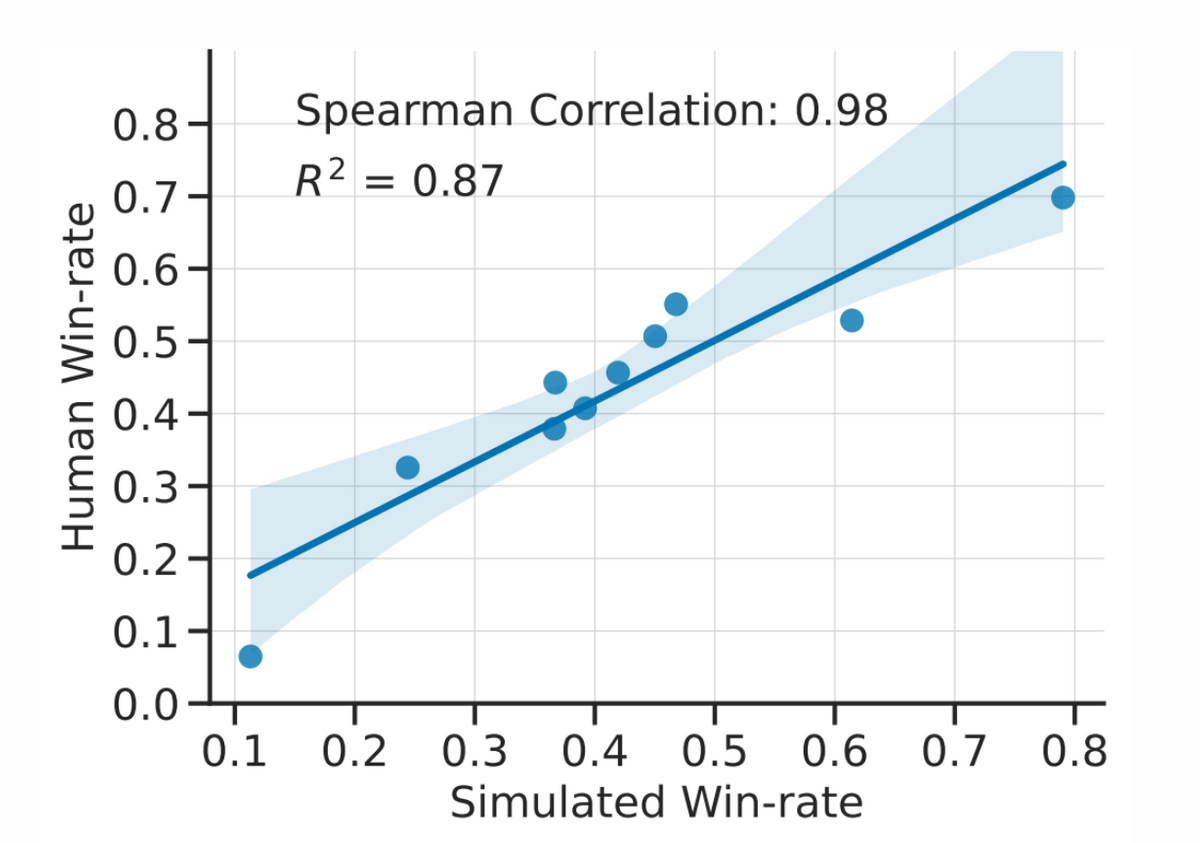
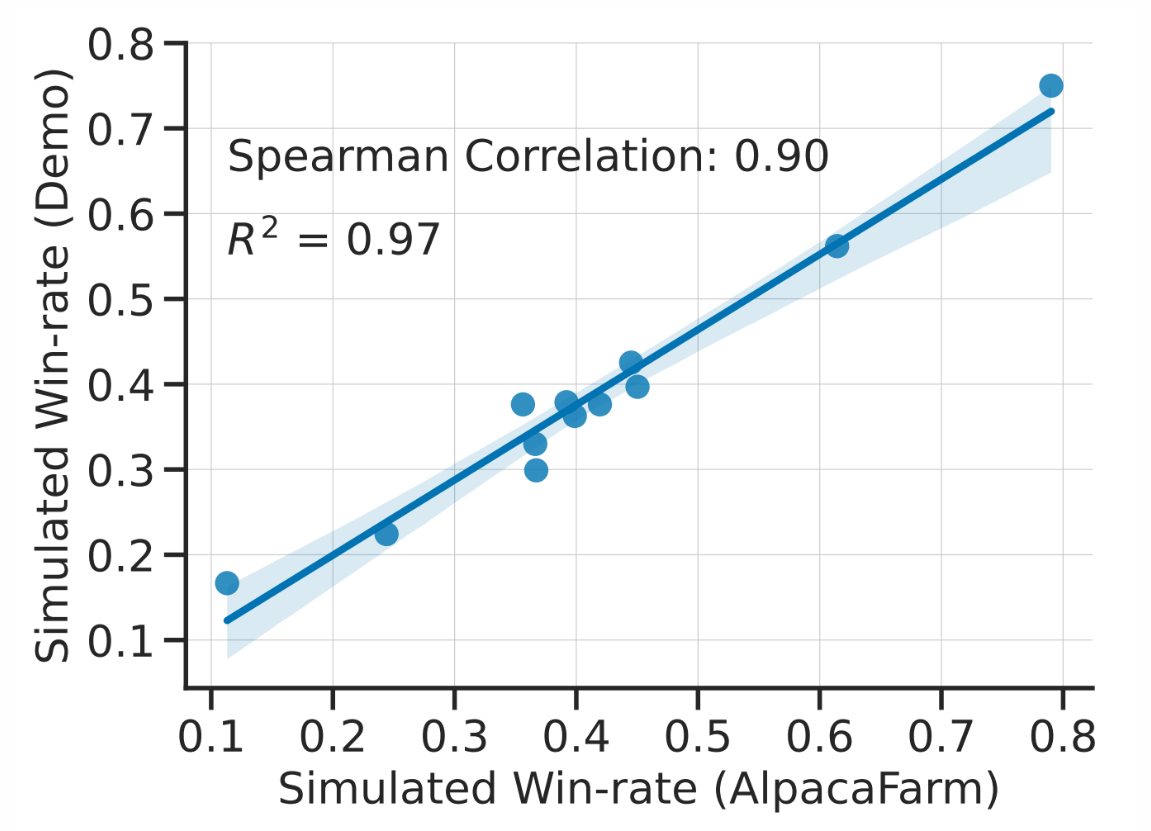
The matching rate between humans and AlpacaFarm regarding the evaluation of the model's response is shown in the figure below. The figure below is a plot of the rate at which the response of the model to be evaluated is judged to be superior to that of the model that is the reference. Conversely, it can be seen that AlpacaFarm also highly evaluates models that humans highly evaluate. It is said that the same evaluation can be performed at 1/45th the cost and in a much shorter time than when an actual human being evaluates.
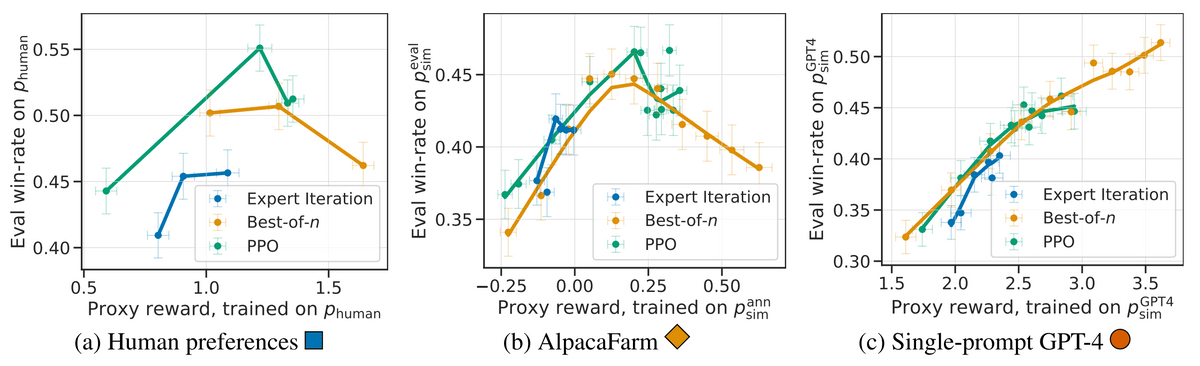
In addition, AlpacaFarm simulations are subject to phenomena such as overoptimization similar to RLHF using real humans. The left end of the figure below is RLHF by humans, and although the performance of the model rises once, the phenomenon that the performance decreases when RLHF is continued appears in the mountain-shaped graph. The same phenomenon can be reproduced by RLHF by AlpacaFarm in the middle, and it can be seen that the same evaluation as human evaluation is returned. The graph of RLHF using GPT-4 on the far right is rising to the right and has failed to reproduce.
In the evaluation between models, which is the second function of AlpacaFarm, a new dataset for evaluation was created based on multiple public datasets. It is stated that the set was adjusted to be as similar as possible to the real-world usage data collected when the demo version of Alpaca 7B was released. We generated responses for the Davinci003 and RLHF models with real-world use case prompts and new assessment prompts to simulate 'which one would generate a better answer?'
The results are shown in the figure below, and show that the compilation of existing public datasets is a good approximation of the performance of simple real-world instructions.
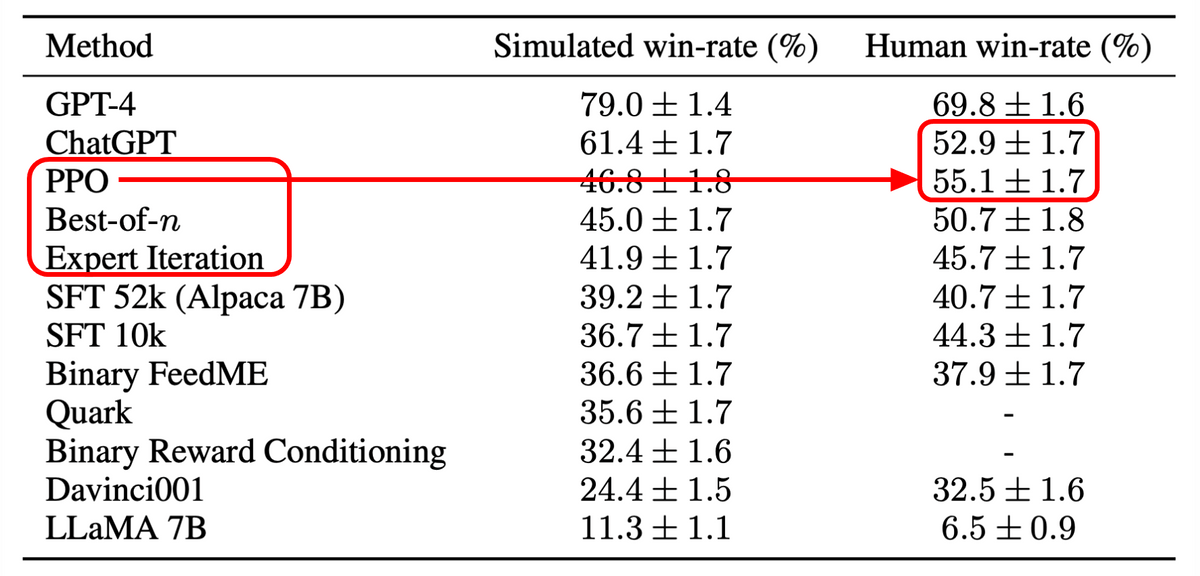
The final feature of AlpacaFarm is that it has three common learning algorithms, ``PPO'', ``Best-of-n'' and ``Expert Iteration'', as reference implementations. The AlpacaFarm development team put Alpaca in these 3 RLHF models and other models to compare their win rate against Davinci003. As a result, PPO was rated higher than ChatGPT in human evaluation.
The code used in this experiment is published on GitHub . If you are interested, please check it out.
Related Posts:







