Stanford University publishes model 'Alpaca 7B' that can build chat AI comparable to GPT-3.5, open source and inexpensively reproducible

A research team at Stanford University has released a large-scale language model `` Alpaca 7B '' that achieves better command followability with open source, which is a fine-tuned 7B model of Meta's large-scale language model ``
Alpaca: A Strong Open-Source Instruction-Following Model - Stanford CRFM
https://crfm.stanford.edu/2023/03/13/alpaca.html
Stanford Alpaca, and the acceleration of on-device large language model development
According to Stanford University, while language models such as GPT-3.5 (text-davinci-003), Chat GPT, Claude, and Bing Chat are becoming more and more powerful, there are still many flaws left. . Maximum progress toward solving this problem required the involvement of academia, but the lack of an open-source model with comparable functionality to closed models such as text-davinci-003 meant that academia was unable to follow orders. It seems that it was difficult to conduct model research.
Therefore, Stanford University made fine adjustments based on the 7B model of Meta's large-scale language model 'LLaMA', which was trained only with a public dataset, and developed and released a language model called 'Alpaca'. Fine adjustment took 3 hours using 8
Alpaca exhibits many similar behaviors to text-davinci-003, but is surprisingly small, easy, and cheap to reproduce.
In fact, a web demo is available on the following site and you can try it.
Alpaca
https://alpaca-ai-custom5.ngrok.io/
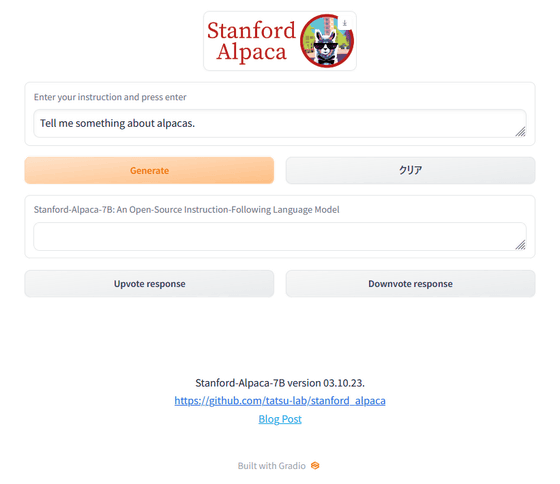
Please note that the use of Alpaca is limited to academic purposes and commercial use is prohibited. This is because the base LLaMA is a non-commercial license, the instruction data is based on text-davinci-003, which prohibits the development of models that compete with OpenAI, and the safety measures are not sufficient to spread it to the general public. It seems that it is due to three reasons that it can not be done.
Related Posts:






in Note, Posted by logc_nt