Introducing the fine-tuning model 'Mistral 7B Fine-Tune Optimized', demonstrating performance exceeding GPT-4 in specific tasks

Introducing
How we built “Mistral 7B Fine-Tune Optimized,” the best 7B model for fine-tuning - OpenPipe
https://openpipe.ai/blog/mistral-7b-fine-tune-optimized
The original model is
Averaged over the four experimental tasks, Mistral 7B fine-tuned with Mistral 7B Fine-Tune Optimized produced slightly higher values than GPT-4.
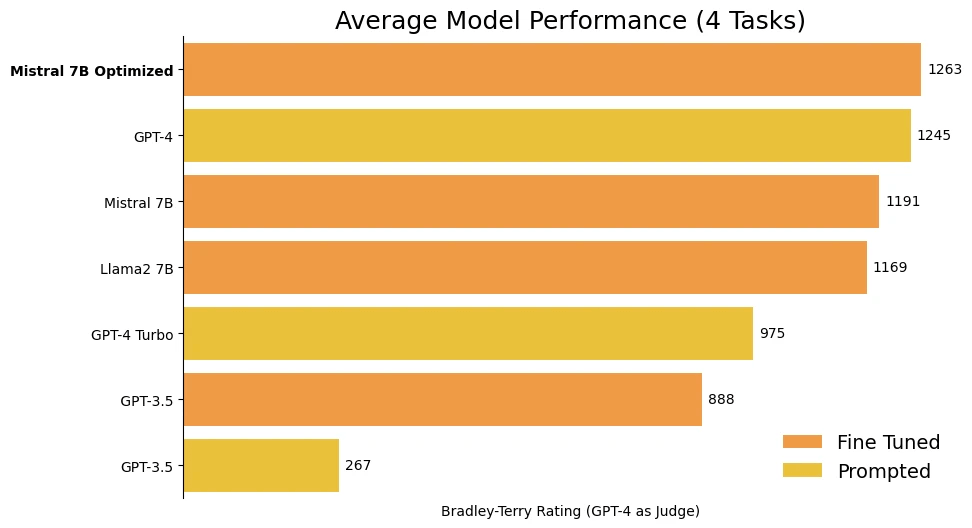
The production team, OpenPipe, points out, ``GPT-4 is a general-purpose model, and in certain tasks it may be inferior to a specialized model that has been fine-tuned.'' He explained that even if a model has low overall performance, a model that has been fine-tuned over many hours will be able to efficiently perform a single task.
It seems that as many as 18 temporary models were created during the production process, but the model that combined multiple models showed high performance, and by further improving it, Mistral 7B Fine-Tune Optimized was born.
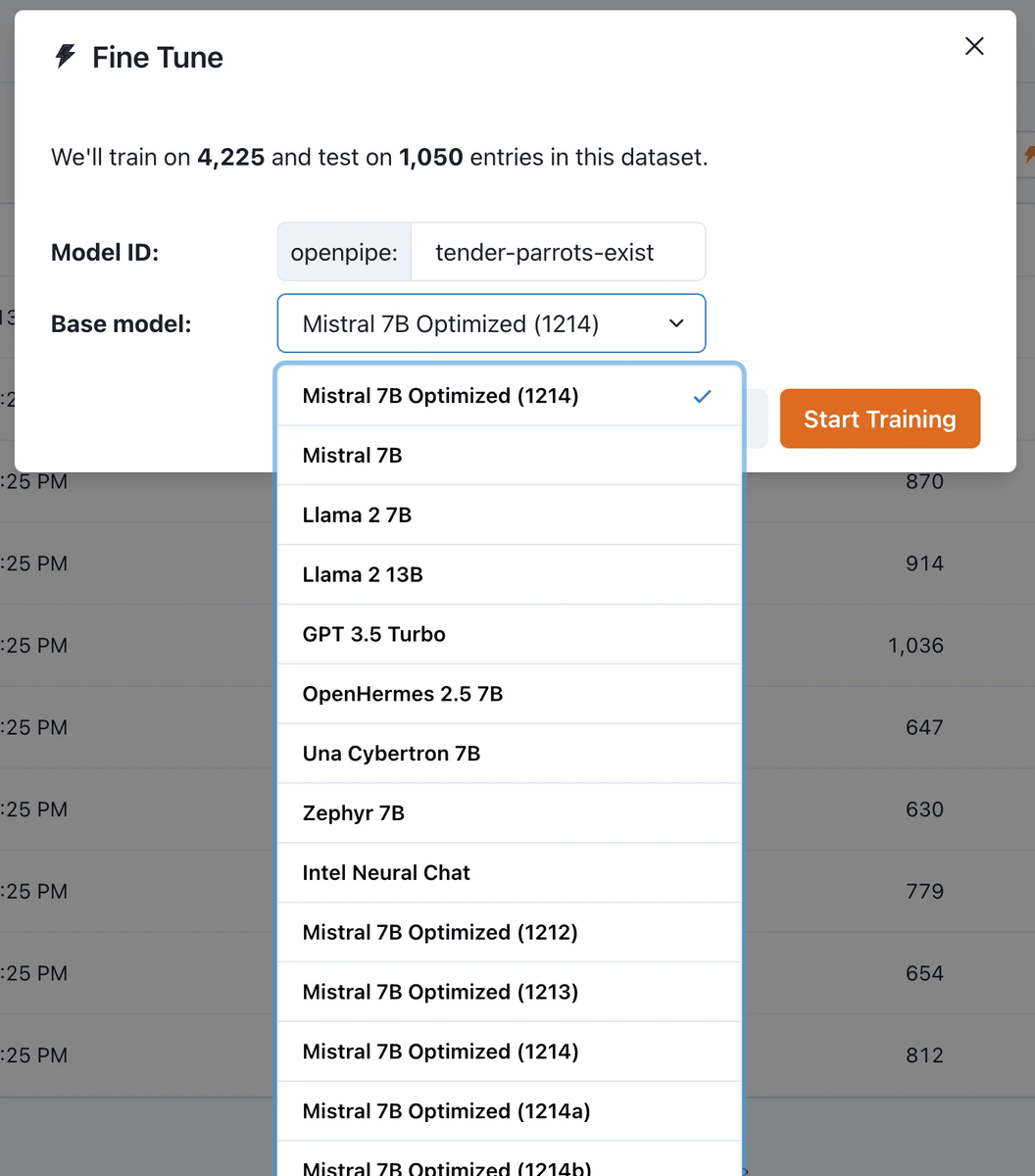
Mistral 7B Fine-Tune Optimized has already been published on Hugging Face. OpenPipe said, 'We can't wait to see what users will do with this model, but this is just the beginning. Over time, we will continue to release stronger, faster, and cheaper base models.' I did.
Related Posts:







