The performance of the open source coding assistance AI 'Qwen2.5-Coder' series is comparable to GPT-4o, and can be run locally on a MacBook Pro with 64GB RAM and M2

The research team behind
Qwen2.5-Coder Series: Powerful, Diverse, Practical. | Qwen
https://qwenlm.github.io/blog/qwen2.5-coder-family/
A technical report for Qwen2.5-Coder was released in October 2024, at which time a model with 1.5 billion (1.5B) and a model with 7 billion (7B) parameters were released as open source. This time, four models with 500 million (0.5B), 3 billion (3B), 14 billion (14B), and 32 billion (32B) parameters have been newly open sourced.
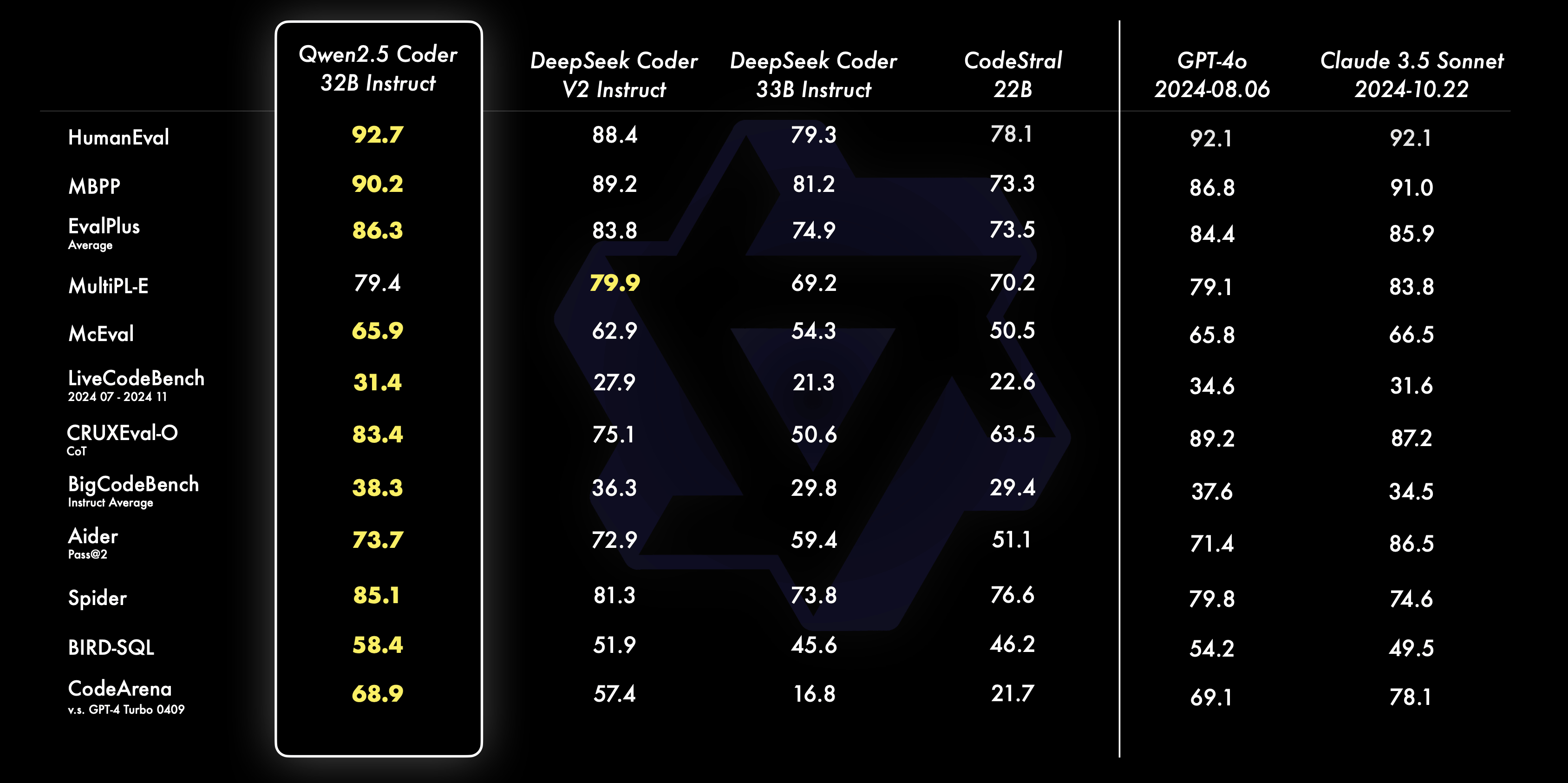
Below is a table comparing each benchmark score of Qwen2.5-Coder-32B-Instruct with other models. Qwen's research team claims that its flagship model, Qwen2.5-Coder-32B-Instruct, performed comparable to GPT-4o in code generation benchmarks such as EvalPlus , LiveCodeBench , and BigCodeBench . In terms of code correction, Qwen2.5-Coder-32B-Instruct performed comparable to GPT-4o in the Aider benchmark. In addition, the research team claims that Qwen2.5-Coder-32B-Instruct also showed superior performance in code inference, which learns the process of code execution and accurately predicts the input and output of the model.
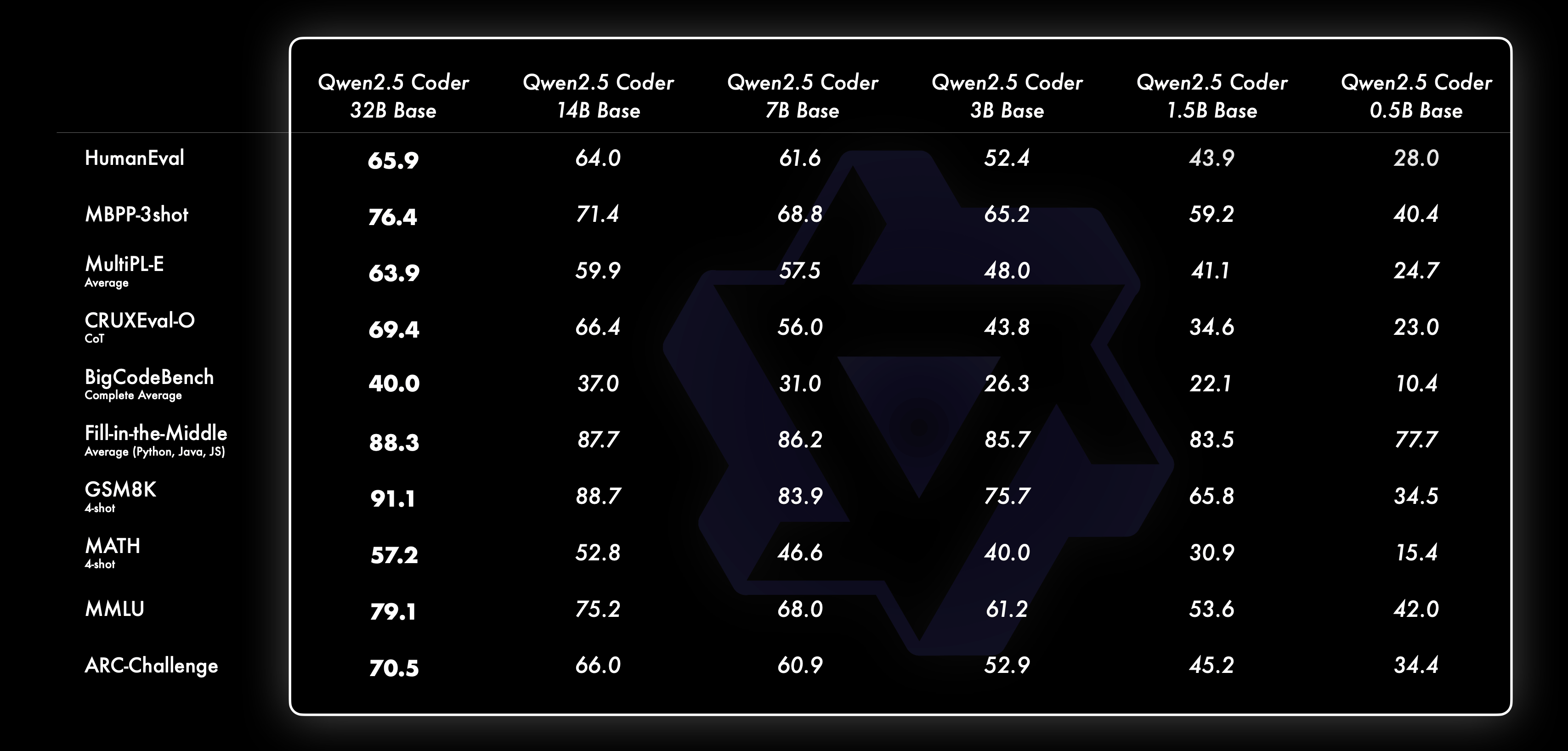
In addition, the benchmark scores for each size for the base model of Qwen2.5-Coder are as follows.
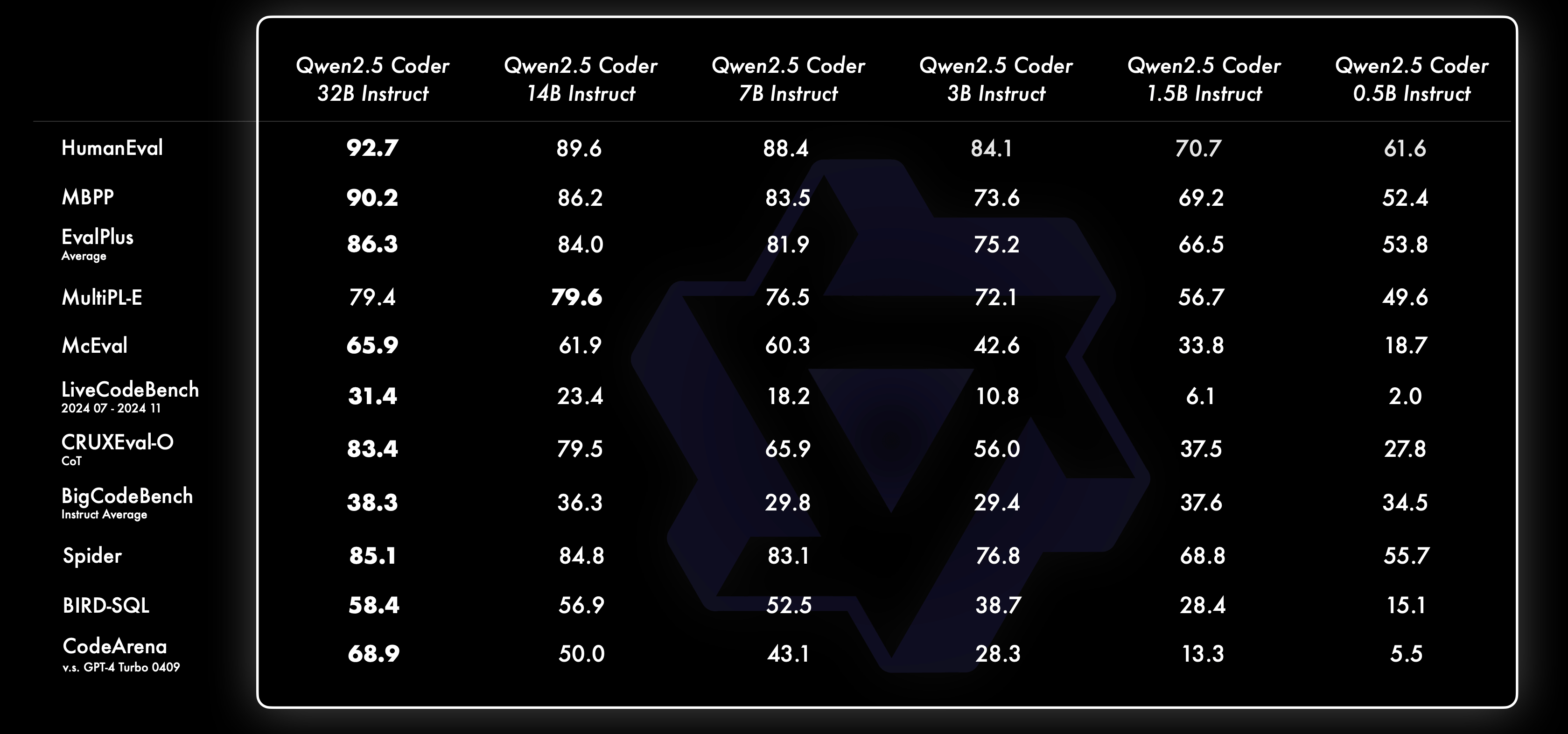
Below are the results of benchmarking each size using the fine-tuned Qwen2.5-Coder Instruct model.
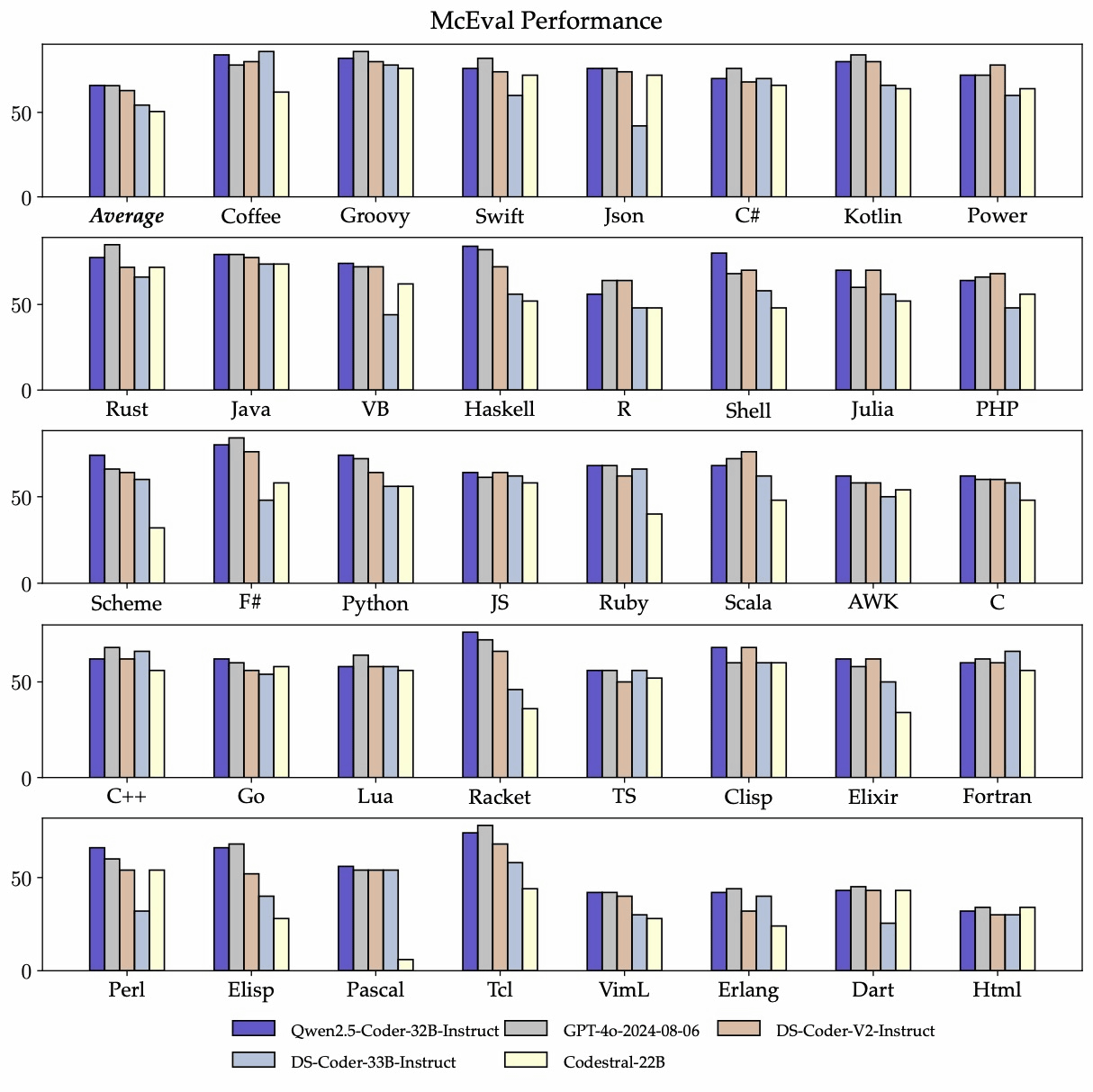
Qwen2.5-Coder-32B-Instruct has demonstrated excellent performance in over 40 programming languages, and achieved a score of 65.9 on
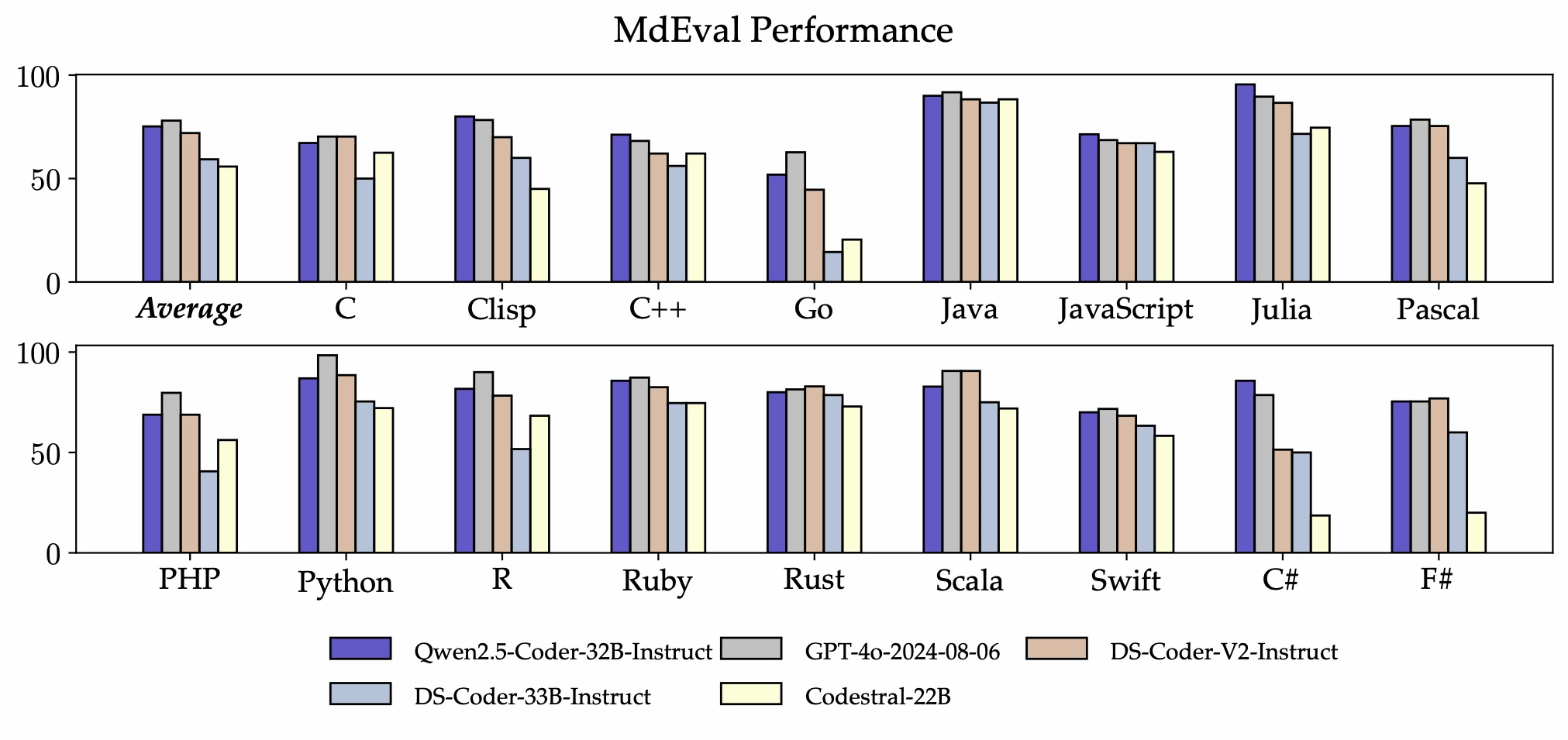
In addition, the research team reports that in the multilingual code correction benchmark MdEval , Qwen2.5-Coder-32B-Instruct achieved a score of 75.2, ranking first among all open source models.
The research team then built an internal annotated code preference evaluation benchmark called 'Code Arena' to evaluate how well Qwen2.5-Coder-32B-Instruct is consistent with human preferences. This benchmark is similar to
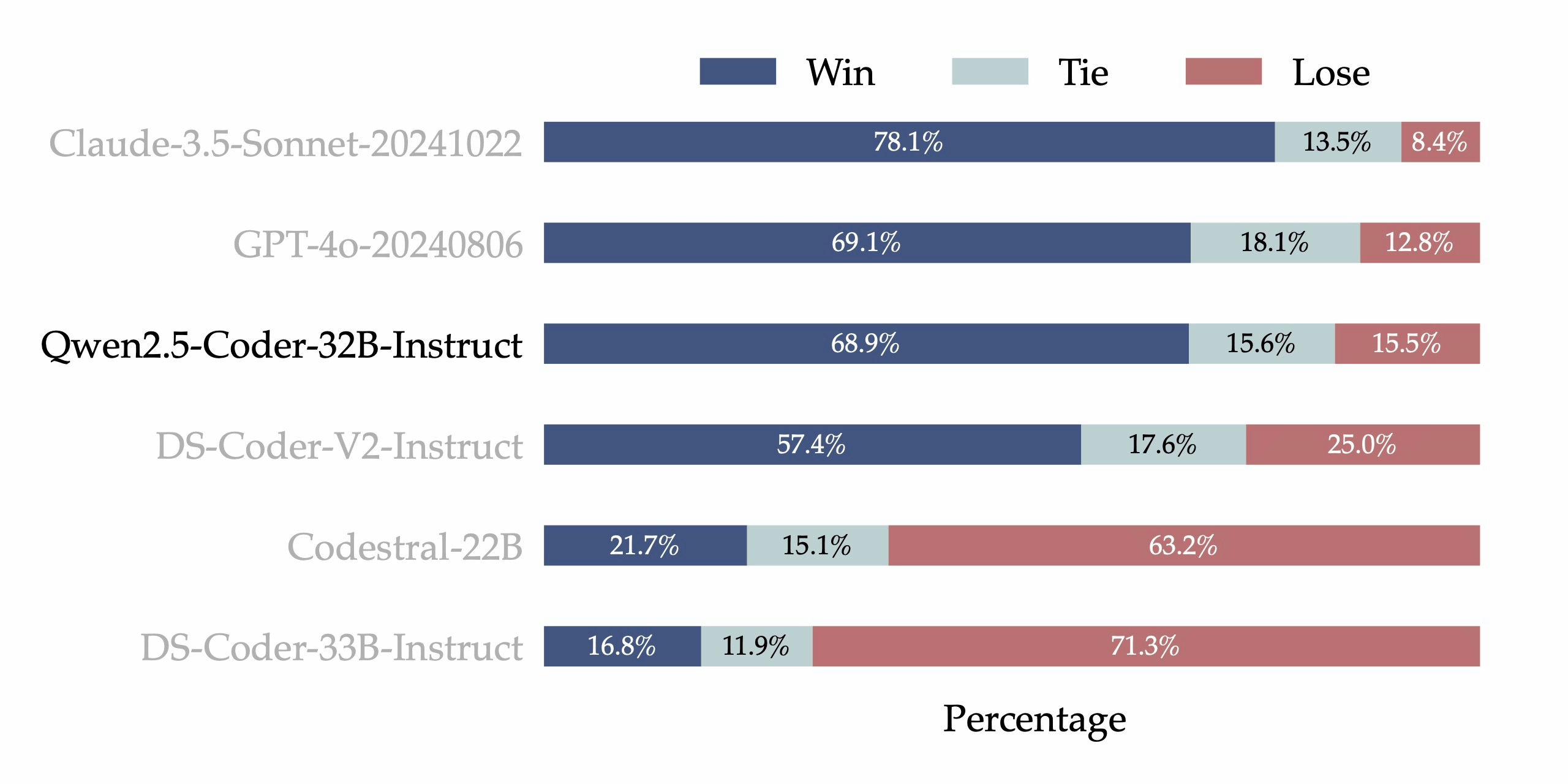
According to the research team, the results of this Code Arena mean that Qwen2.5-Coder-32B-Instruct can generate output that is in line with human programming preferences and expectations. In other words, in real development situations, Qwen2.5-Coder-32B-Instruct may be able to generate more practical and useful suggestions and code for humans. However, it should be noted that this evaluation is based solely on GPT-4o.
Web developer Simon Willison actually ran Qwen2.5-Coder-32B-Instruct on a MacBook Pro with 64GB of memory and tested it. 'The size of Qwen2.5-Coder-32B-Instruct is small enough that I can run the model on my MacBook Pro without having to close other applications, and the speed and quality of the results are comparable to the best models,' he reported.
Related Posts:






in Software, Posted by log1i_yk