Apple releases 'OpenELM', an open source language model that runs locally on iPhones and iPads

Apple's research team has released an open source language model called ' OpenELM (Open-source Efficient Language Models) '. The released model also includes code to convert it to run on Apple devices, making it possible to 'run the language model locally on Apple devices.'
[2404.14619] OpenELM: An Efficient Language Model Family with Open-source Training and Inference Framework
OpenELM: An Efficient Language Model Family with Open-source Training and Inference Framework - Apple Machine Learning Research
https://machinelearning.apple.com/research/openelm

The released OpenELM is available in four models: 270M (number of parameters: 270 million), 450M (number of parameters: 450 million), 1_1B (number of parameters: 1.1 billion), and 3B (number of parameters: 3 billion). Compared to OpenAI's GPT-4 , Anthropic's Claude 3 , and Meta's Llama 3 , OpenELM is a relatively small model, but because it is small, it has low execution costs and is optimized to run on smartphones and laptops.
One of the features of OpenELM is that it uses a technique called 'layer-wise scaling,' which efficiently allocates parameters throughout the model by changing the number of parameters in each layer of the Transformer .
Specifically, the dimensionality of the latent parameters for attention and feedforward is reduced in layers close to the input, and gradually expanded as the layers approach the output. This allows an appropriate number of parameters to be assigned to each layer within a limited number of parameters. In conventional language models, it is common for all layers to have the same settings, but this layer-wise scaling allows different settings for each layer, making it possible to utilize parameters more effectively.
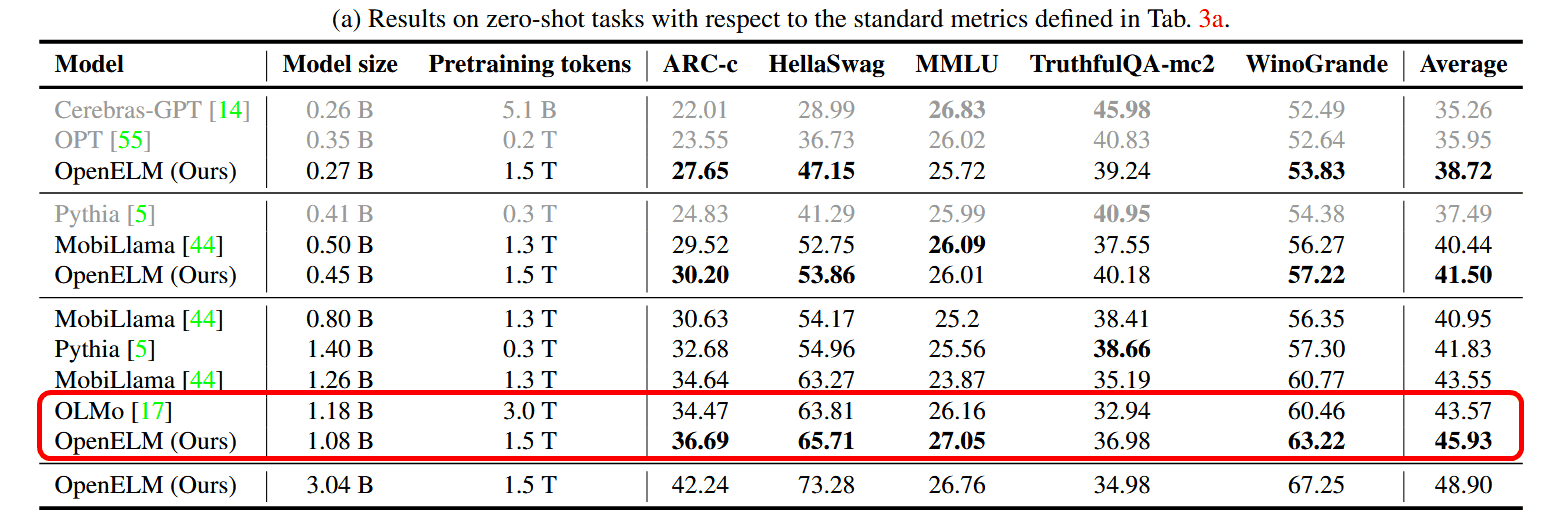
According to the research team, when trained only on public datasets, OpenELM achieved higher accuracy than open models with a similar number of parameters. For example, OpenELM, which has about 1.1 billion parameters, was 2.36% more accurate than OLMo , a model with about 1.2 billion parameters, despite requiring half the amount of training data as OLMo.
In addition, by applying 'Instruction Tuning,' which gives instructions to the language model to perform a specific task and learns it specifically for that task, the accuracy of OpenELM was improved by 1 to 2%. The research team reported that by applying Instruction Tuning, OpenELM not only improved its general language understanding ability but also its performance in specific tasks. In addition, OpenELM can apply parameter-efficient fine-tuning methods such as Low-Rank Adaptation (LoRA) and Decomposed Low-Rank Adaptation (LoRA).
Additionally, code is provided to convert trained models into Apple's MLX (Machine Learning Accelerator) libraries, meaning trained OpenELM models can be run efficiently on Apple devices such as iPhones and iPads.
OpenELM is developed as open source, and the repository is hosted on the online AI platform Hugging Face. To ensure reproducibility and transparency of OpenELM, the research team provides not only the weights of the OpenELM model, but also the training code, training logs, multiple checkpoints, the public dataset used to train the model, detailed hyperparameters of the training, and the code to convert it into an MLX library.
apple/OpenELM Hugging Face
https://huggingface.co/apple/OpenELM
Apple has not revealed how it plans to deploy OpenELM in the future, but the IT news site The Verge is hopeful that it could 'efficiently perform text-related tasks, such as composing emails, on Apple devices.'
Related Posts:







in Software, Smartphone, Posted by log1i_yk