




ChatGPTにも使われる機械学習モデル「Transformer」が自然な文章を生成する仕組みとは?

ChatGPTなどの自然な会話が可能なチャットAIのベースとなっている大規模言語モデルは、Googleが開発した機械学習アーキテクチャ「Transformer」を採用しています。そんなTransformerが文脈に沿った自然な文章を出力する仕組みについて、AI専門家のLuis Serrano氏が解説しています。
What Are Transformer Models and How Do They Work?
https://txt.cohere.com/what-are-transformer-models/
Transformerは、簡単に言うと文章の文脈に合わせて続きを生成する技術です。「文章の続きを生成する技術」は古くから研究されており、携帯電話などにも予測入力機能が搭載されていますが、これら予測機能は入力履歴から頻出語句を選び出しているだけで、文脈を無視した候補が選出されることもよくあります。一例として、携帯電話の予測入力の性能を確かめるために手動で「これ」と入力してから予測入力候補の先頭のみをタップし続けてみます。
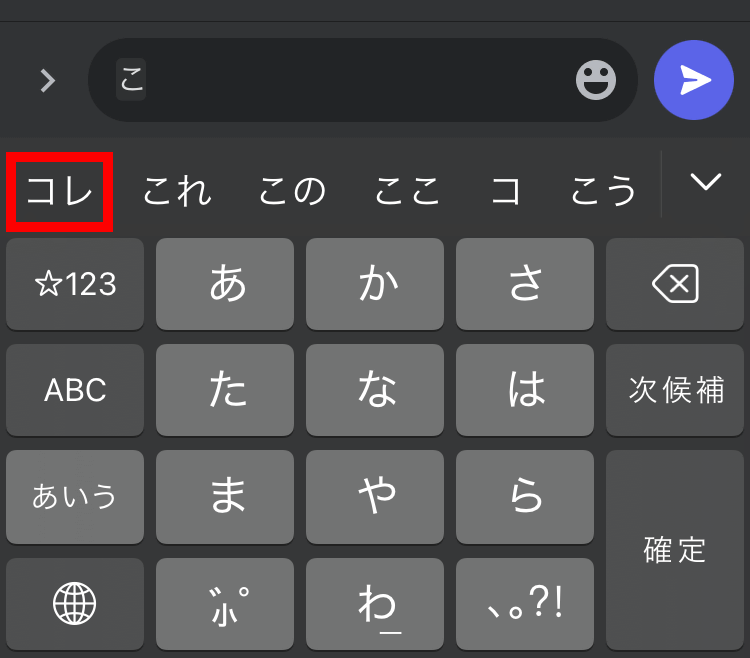
完成した文章はこんな感じ。意味不明の文章が出来上がってしまいました。
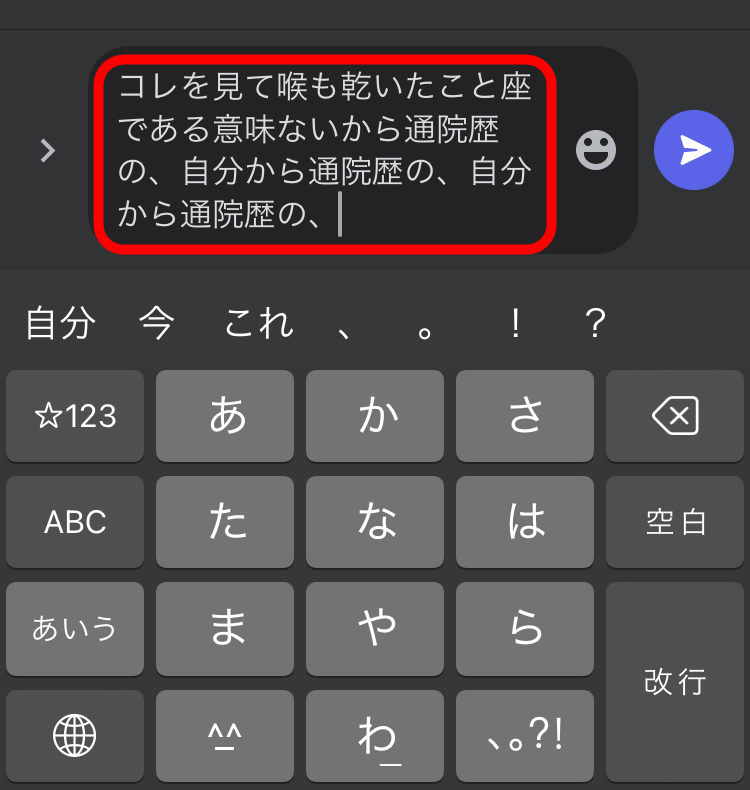
一方で、Transformerは文脈を保ちながら文章の続きを生成することができます。例えば「Write a story.」という文章を入力すると「Once」が続くと予想し、さらに「Write a story. Once」を入力すると「upon」が続くと予想、「Write a story. Once upon」を入力すると「a」が続くと予想……というように破綻しない自然な文章を生成できるというわけです。

Transformerは大きく分けて「Tokenization(トークン化)」「Embedding(埋め込み)」「Positional encoding(位置エンコーディング)」「Transformer block(Transformerブロック)」「Softmax(ソフトマックス)」といった5段階の操作を経て文章を認識&生成しています。それぞれの操作の詳細は以下の通り。
◆トークン化
Transformerでは、文章を「トークン」呼ばれる単位に細切れにしてから処理を行います。例えば「Write a story.」という文章は「Write」「a」「story」「.」といったように細切れにされます。
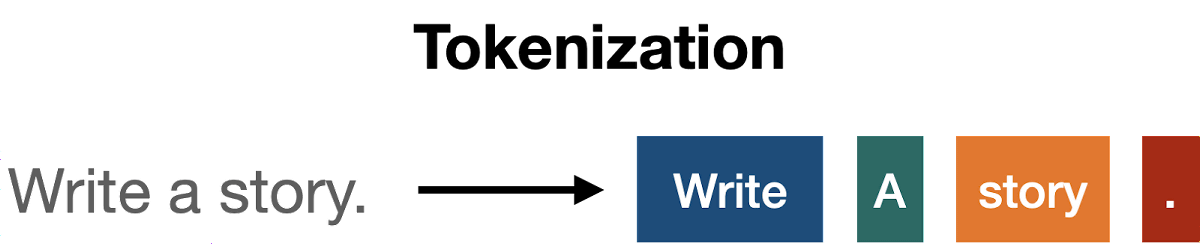
英文の場合は1単語が1トークンになることが多いですが、単語の種類や言語によってトークンの分かれ方は異なります。日本語の文章がどのようにトークン化されるかは、以下の記事を読むと理解できます。
ChatGPTなどのチャットAIがどんな風に文章を認識しているのかが一目で分かる「Tokenizer」 - GIGAZINE

◆埋め込み
トークン化が完了したら、各トークンを数値に変換する「埋め込み」が行われます。埋め込みはトークンを「トークンと数値の対応リスト(ベクトル)」に照らし合せることで行われます。
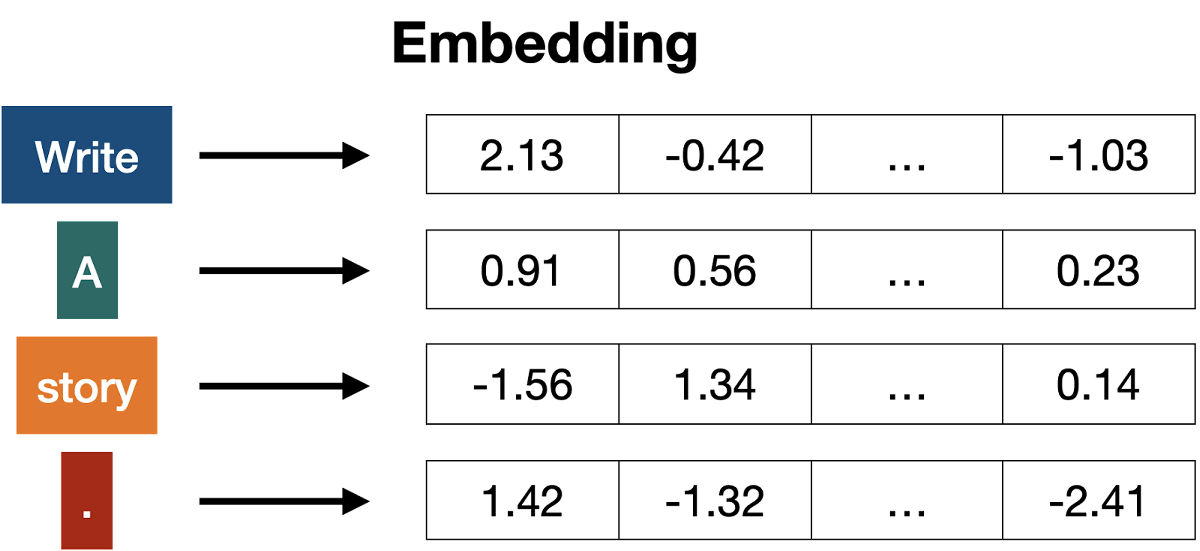
ベクトルは本来は何種類も存在しますが、ベクトルが2種類と仮定した場合、トークンの埋め込み後の状態は以下のようになります。各トークンの座標を確認すると、「リンゴ(5,5)」「バナナ(6,5)」「イチゴ(5,4)」「サクランボ(6,4)」といったように意味の近いトークンが近い座標に位置していることが分かります。このように、埋め込みによってトークンを数値化することで、各トークンが似ているかどうかが分かるようになります。
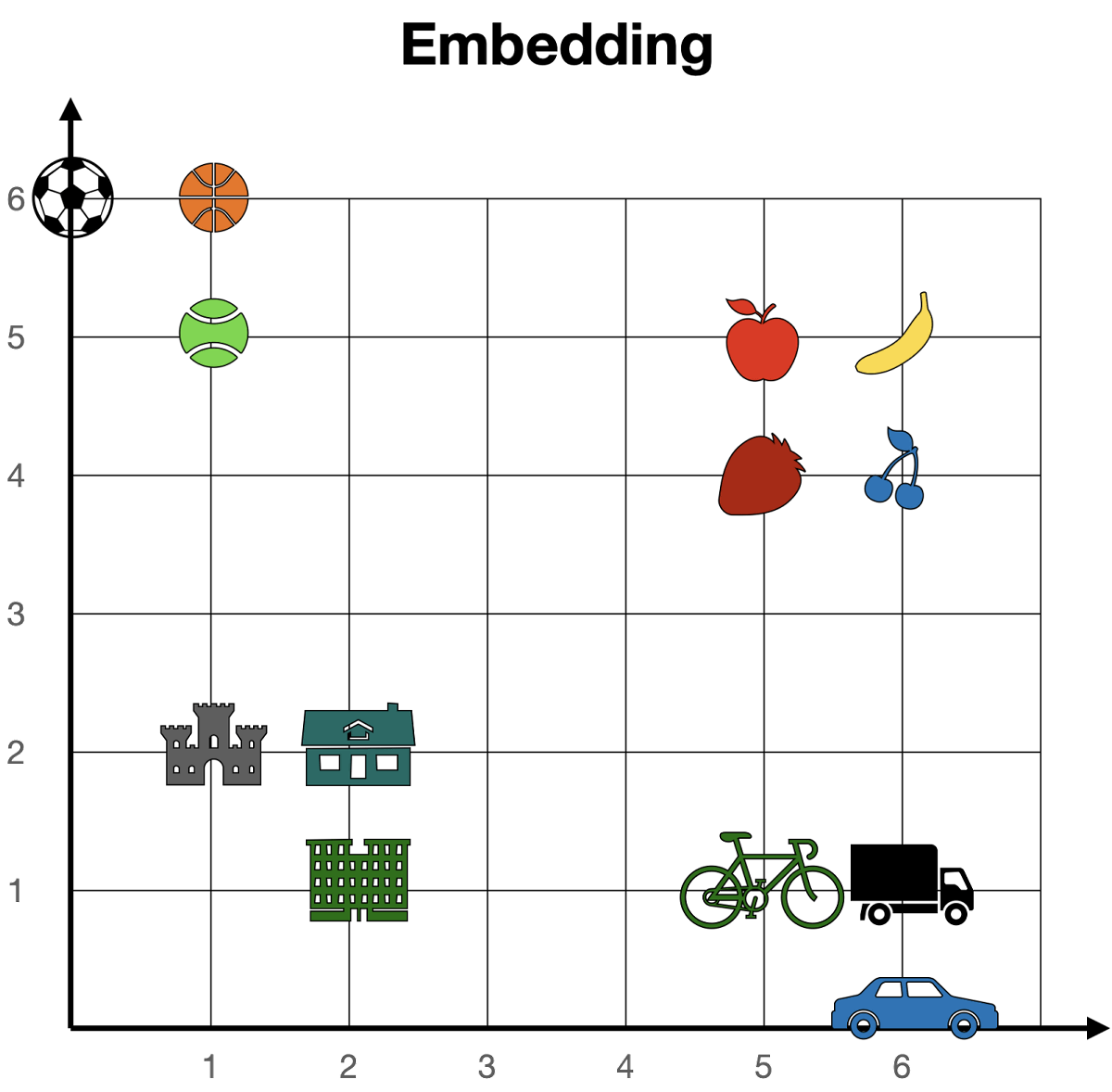
◆位置エンコーディング
各トークンを数値化したら、次に文全体を1つのベクトルに変換する必要があります。文全体を1つのベクトルにするには、各トークンの座標の合計を導きだせばOK。例えば、文章に含まれるトークンの座標が「2,3」「2,4」「1,5」の場合、文全体の座標は「2+2+1,3+4+5」=「5,12」となります。
ただし、単純に座標を合計する手法の場合、「I’m not sad, I’m happy」「I’m not happy, I’m sad」という「同じ単語が異なる順番で並ぶ文章」が同一座標に存在することになってしまいます。この同一座標問題を解決するために、Transformerでは各トークンに並び順を示す位置トークンを追加しています。例えば「Write a story.」という文章は「Write」「a」「story」「.」に分けられ、さらに位置ベクトルが追加されて「Write(1)」「a(2)」「story(3)」「.(4)」となります。
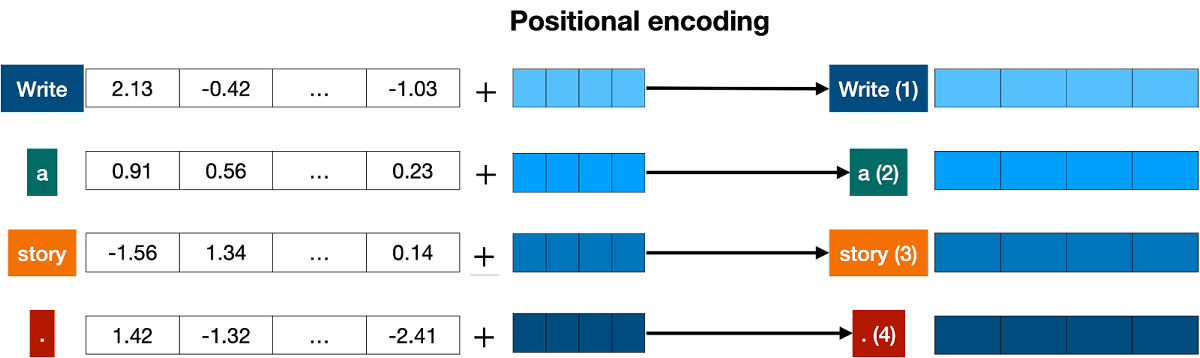
◆Transformerブロック
トークンの埋め込みと位置エンコーディングが完了したら「文脈に合わせて続きを生成する」という処理が実行されます。この処理は「Transformerブロック」と呼ばれる処理系統を何個も通過することで実行されます。
Transformerブロックの中でも重要なのが、文脈を考慮できるようにトークンに重み付けする「Attention(注意)」と呼ばれる工程です。例えば「bank」という単語には「土手」と「銀行」という2つの意味があり、「bank」という単語だけを示されても、どちらの意味なのかを判断するのは困難です。しかし、「The bank of the river(川の土手)」「Money in the bank(銀行の金)」というように、「bank」とセットになる単語によって「bank」の意味を把握することができます。そこで、Transformerでは、「土手」を意味する「bank」を「river」の近くの座標に、「銀行」を意味する「bank」を「Money」の近くの座標に配置することで、文章を破綻させることなく単語をつなげられるようになっています。

上記のような文脈に応じた重み付け処理を行った上で、Transformerブロックでは文章の続きとして適切な単語を複数導き出し、それぞれの単語にスコアを付与します。
◆ソフトマックス
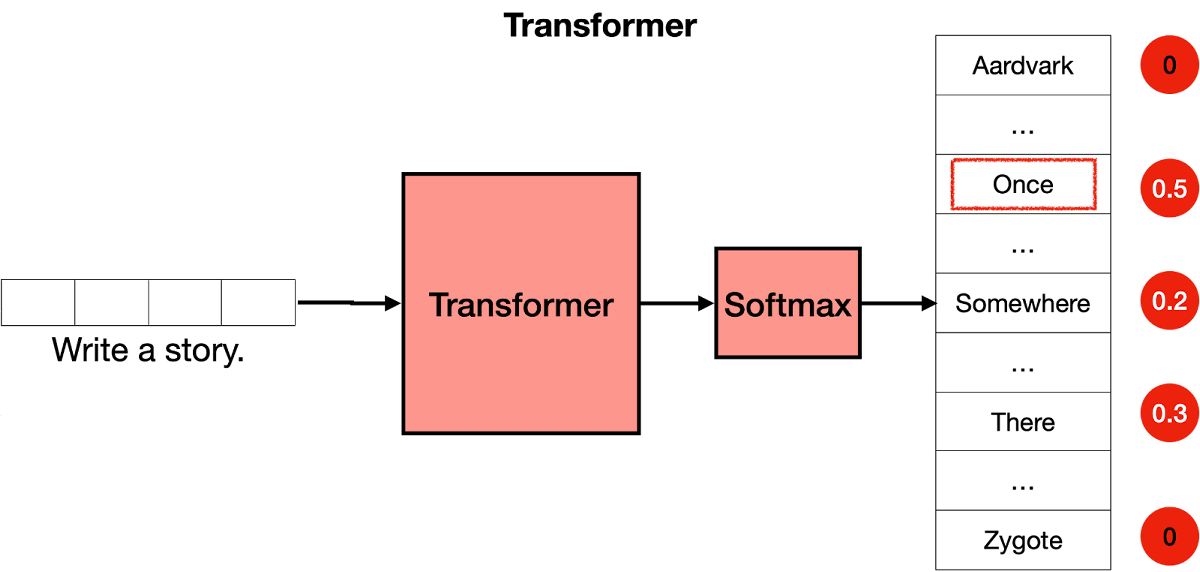
Transformerブロックで文章の続きとして適切な単語の候補を導き出したら、各候補のスコアを確率に変換するソフトマックス処理を実行します。そして、最も確率の高い単語が文章の続きとして出力されます。以下の例の場合、「Write a story.」という文章を入力した結果「Once」「Somewhere」「There」といった単語が候補として導き出され、候補の中で最も確率の高い「Once」が文章の続きとして出力されています。そして、「Once」を出力したら「Write a story. Once」が新たに入力され、次々と文章の続きが生成されるというわけです。
・関連記事
より高い品質の翻訳を実現するGoogleの「Transformer」がRNNやCNNをしのぐレベルに - GIGAZINE
言語処理のニューラルネットワークモデルが脳の働きと同じ構造をしているという仮説 - GIGAZINE
自然なブログを書いてしまうほど超高精度な言語モデル「GPT-3」はどのように言葉を紡いでいるのか? - GIGAZINE
ChatGPTなどのチャットAIがどんな風に文章を認識しているのかが一目で分かる「Tokenizer」 - GIGAZINE
・関連コンテンツ







in ソフトウェア, Posted by log1o_hf
You can read the machine translated English article What is the mechanism by which the machi….