




自然なブログを書いてしまうほど超高精度な言語モデル「GPT-3」はどのように言葉を紡いでいるのか?

OpenAIが開発する「GPT-3」は、ほとんど違和感のないブログ記事を生成できてしまうほど高い精度を誇る言語モデルです。そのGPT-3がテキストを生成する仕組みについて、オンライン学習プラットフォーム「Udacity」でAIや機械学習関連の講座を持つJay Alammar氏が解説しています。
How GPT3 Works - Visualizations and Animations – Jay Alammar – Visualizing machine learning one concept at a time.
https://jalammar.github.io/how-gpt3-works-visualizations-animations/
The Illustrated GPT-2 (Visualizing Transformer Language Models) – Jay Alammar – Visualizing machine learning one concept at a time.
https://jalammar.github.io/illustrated-gpt2/
[2005.14165] Language Models are Few-Shot Learners
https://arxiv.org/abs/2005.14165
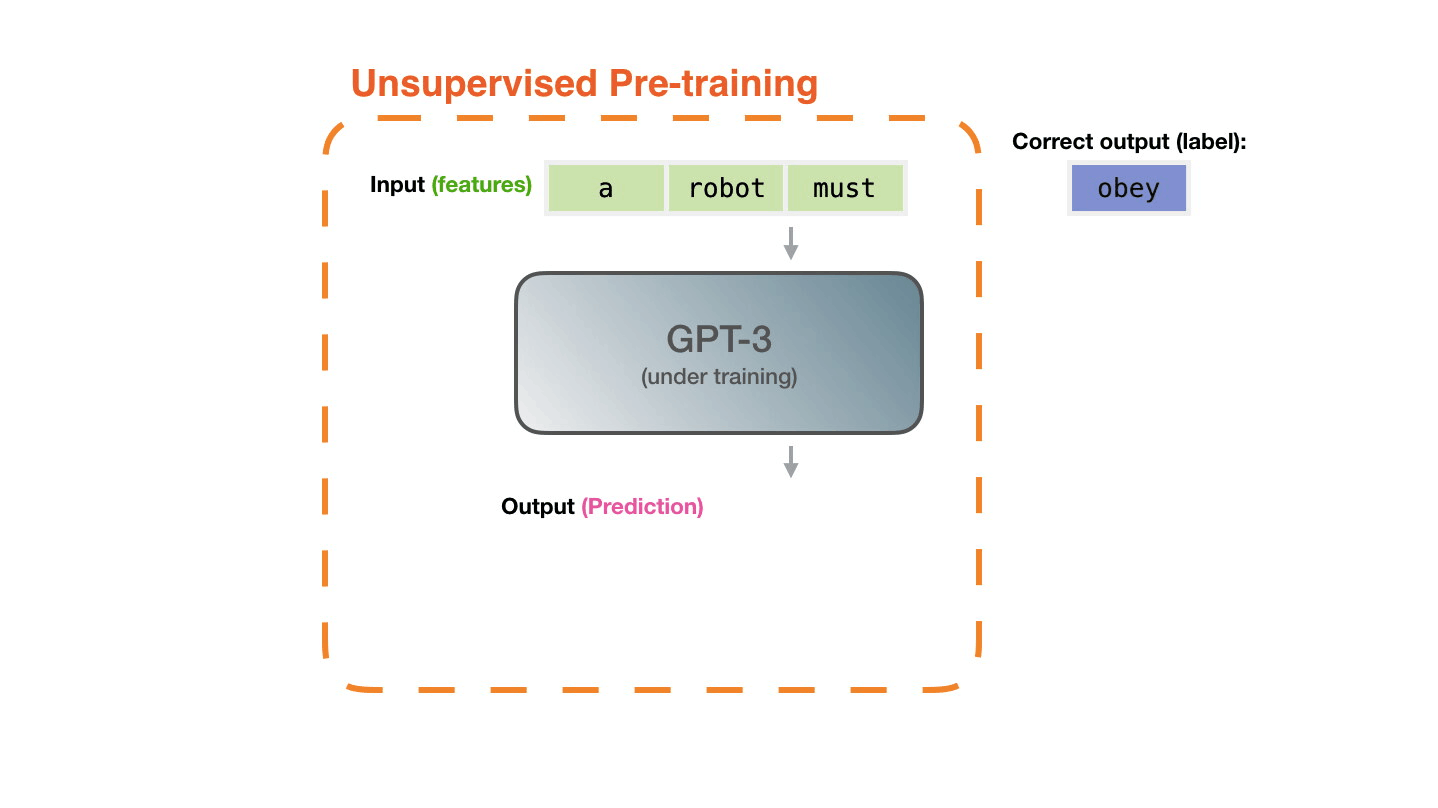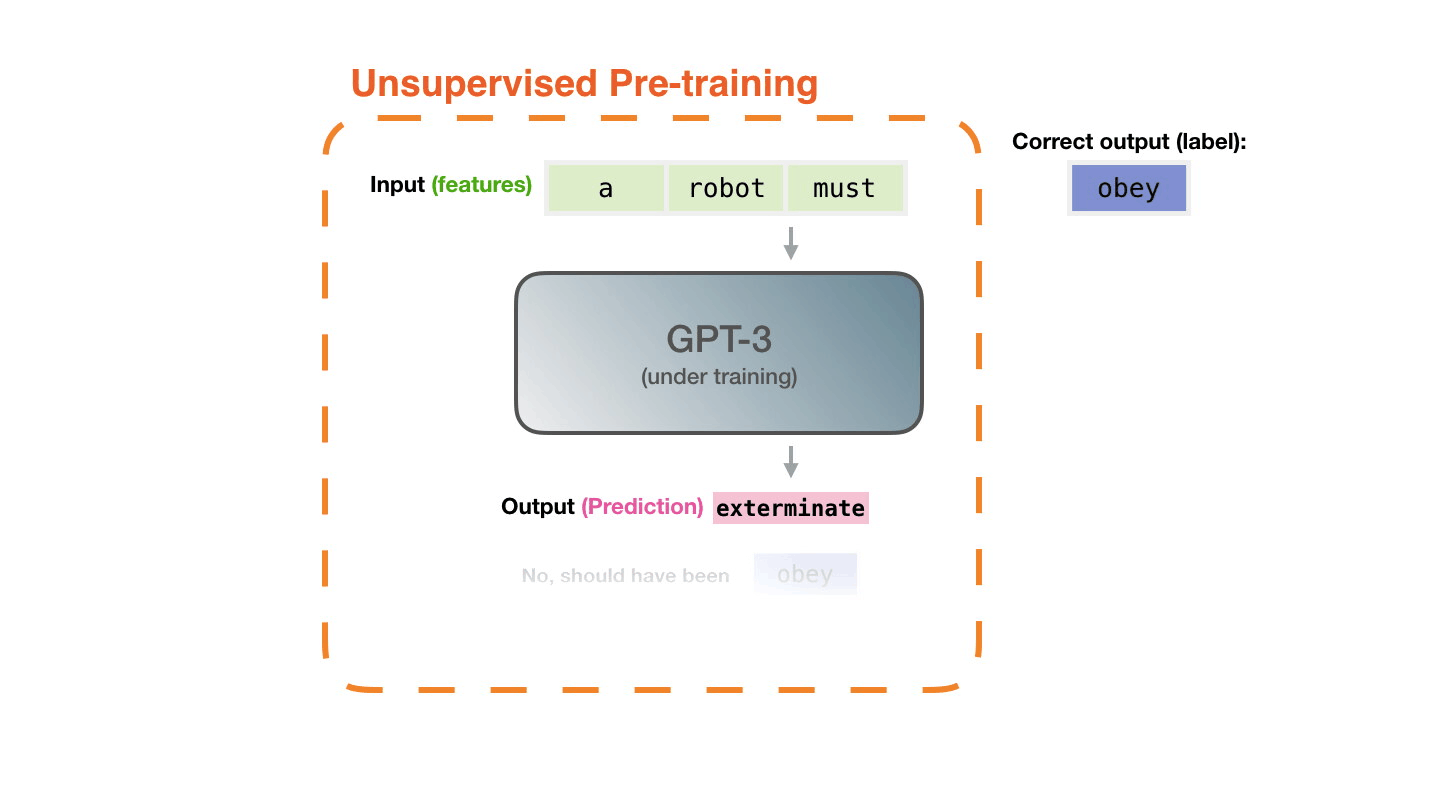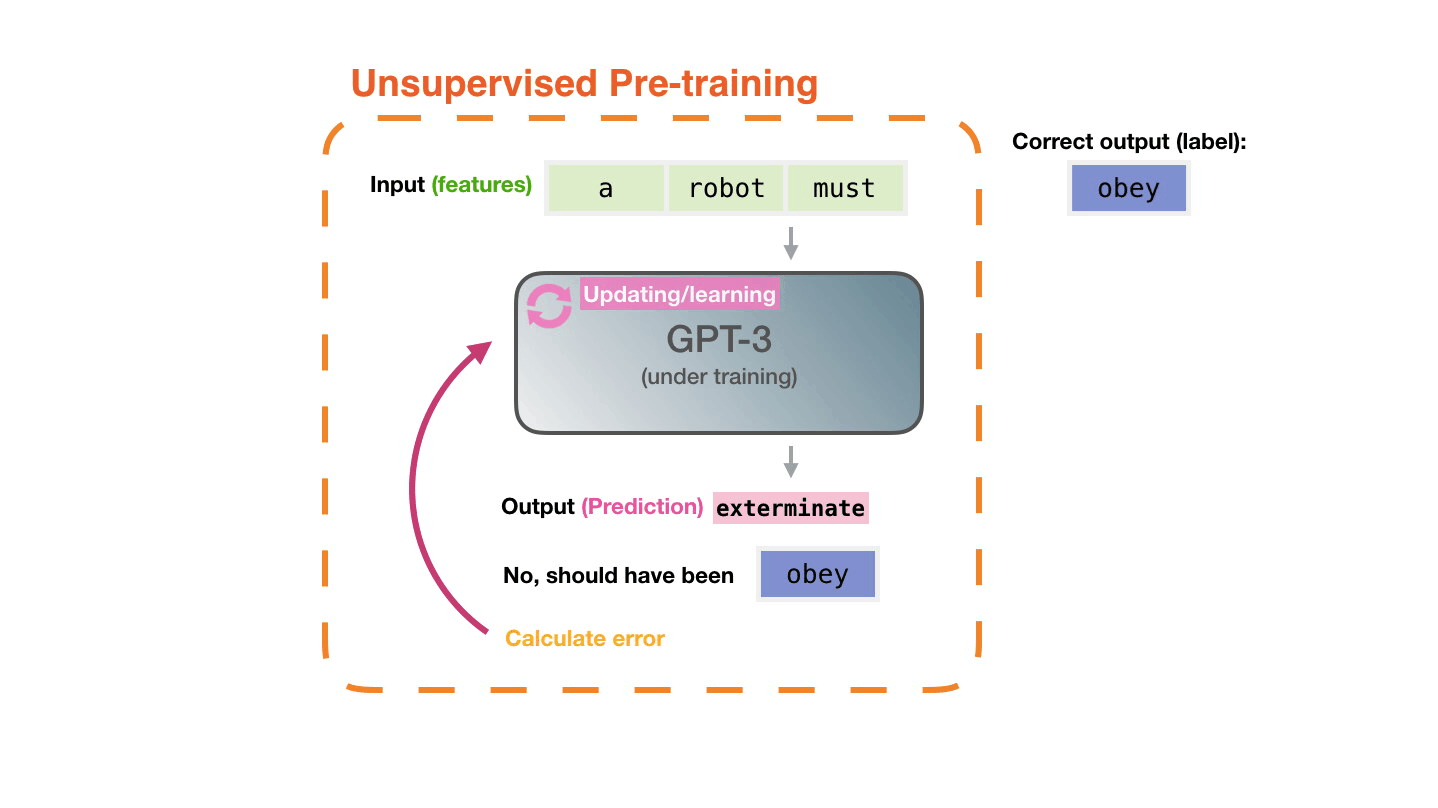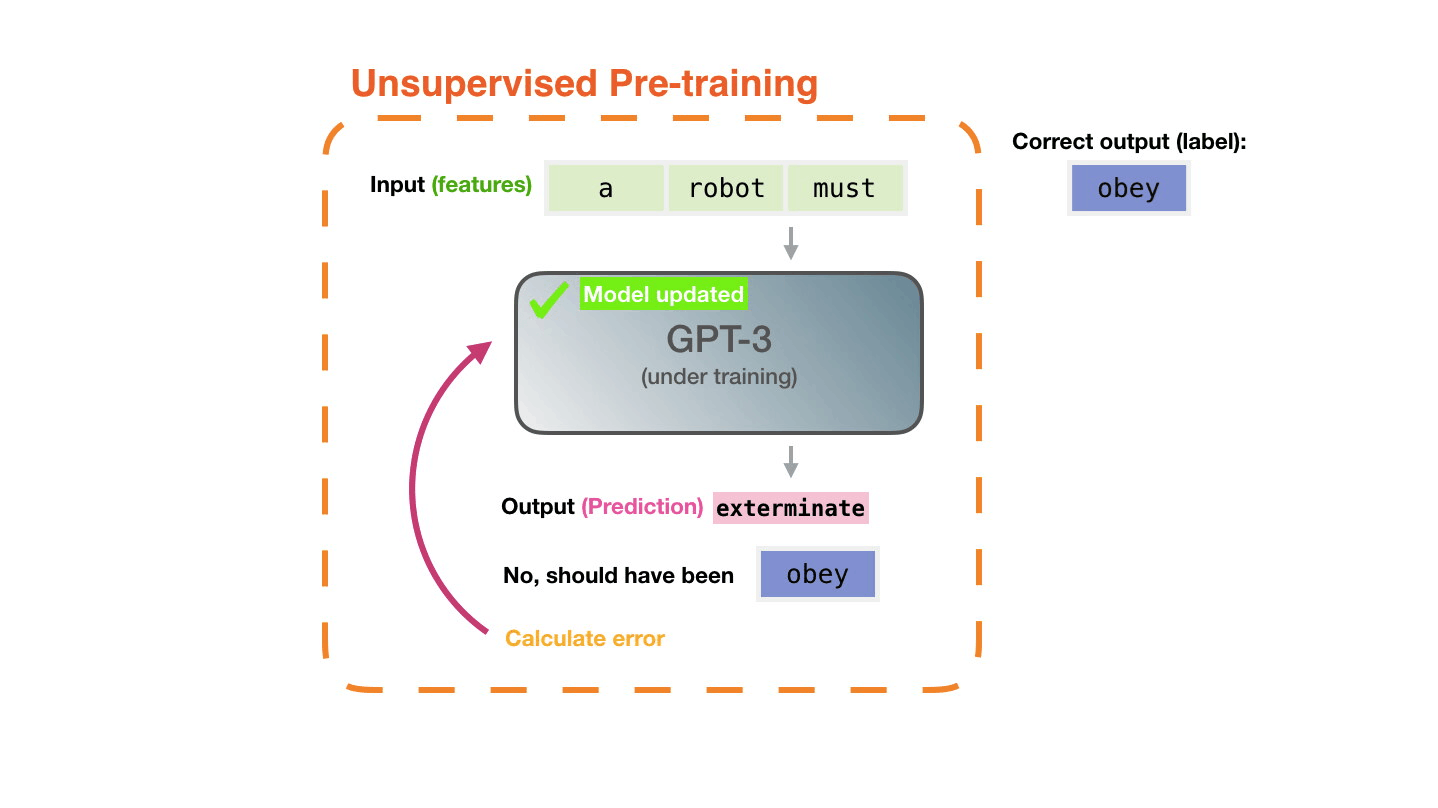
GPT-3では、まず3000億もの字句を含む大規模なデータセットを用いて学習を行っているとのこと。正解を与えずに特徴のパターンを学習させる「教師なし学習(Unsupervised Pre-training)」により、データセットから「次に来る単語」を予測するように学習が行われます。例えば「a」「robot」「must」という単語の並びの次に来る単語を、次の単語が何かという正解なしに学習していくというわけです。Alammar氏によると、GPT-3の学習には460万ドル(約4億9000万円)のコストがかかり、1台のGPUを使用した場合は計算に355年かかるとのこと。
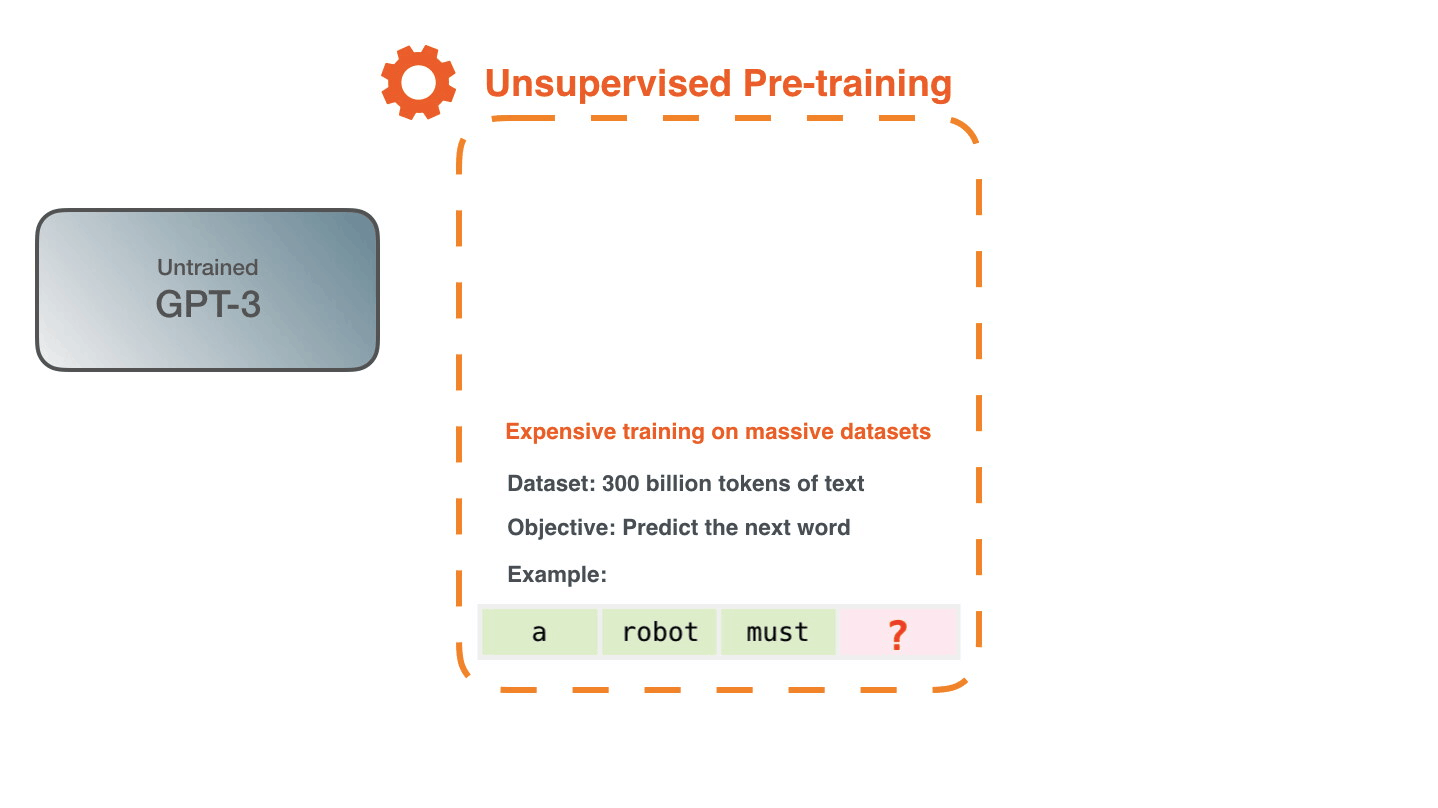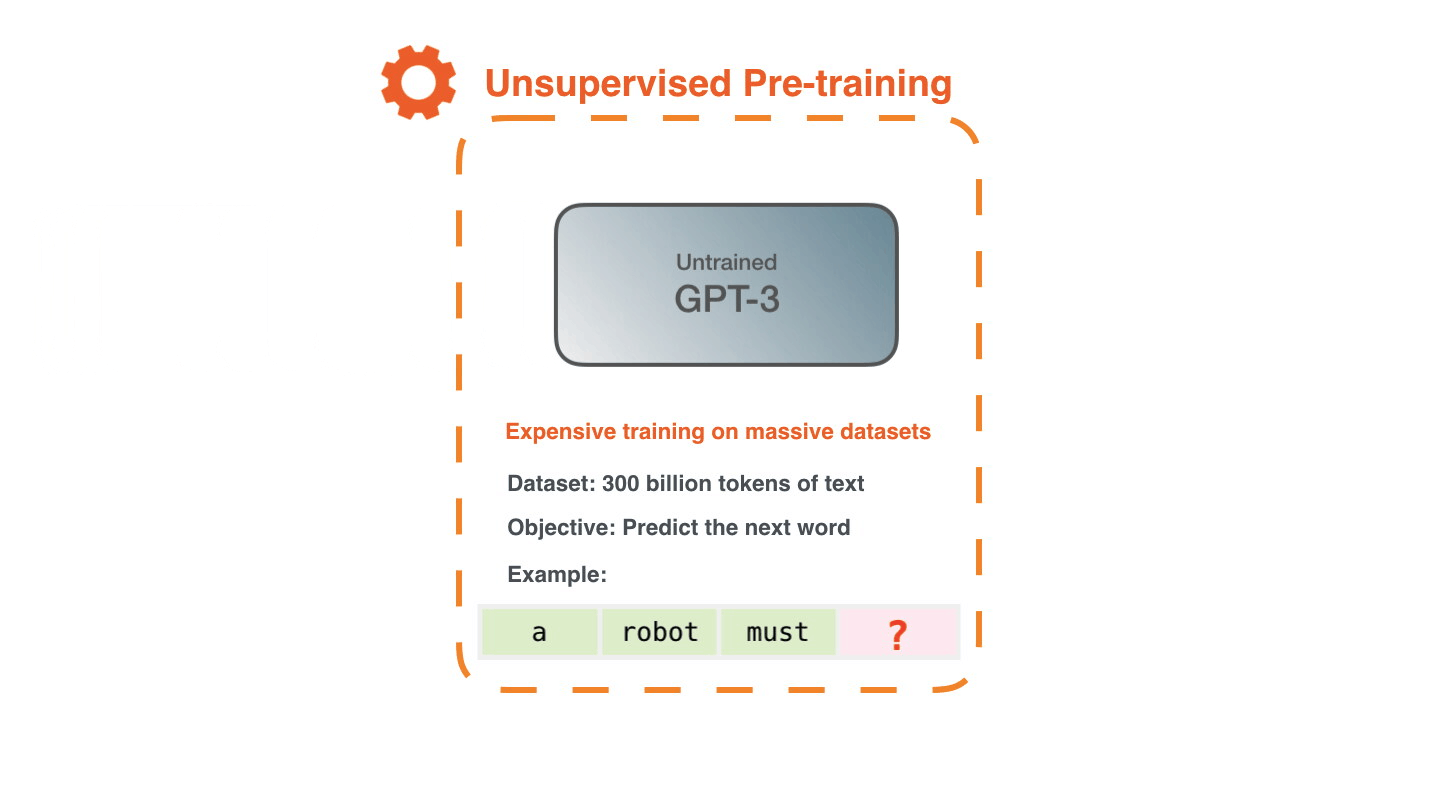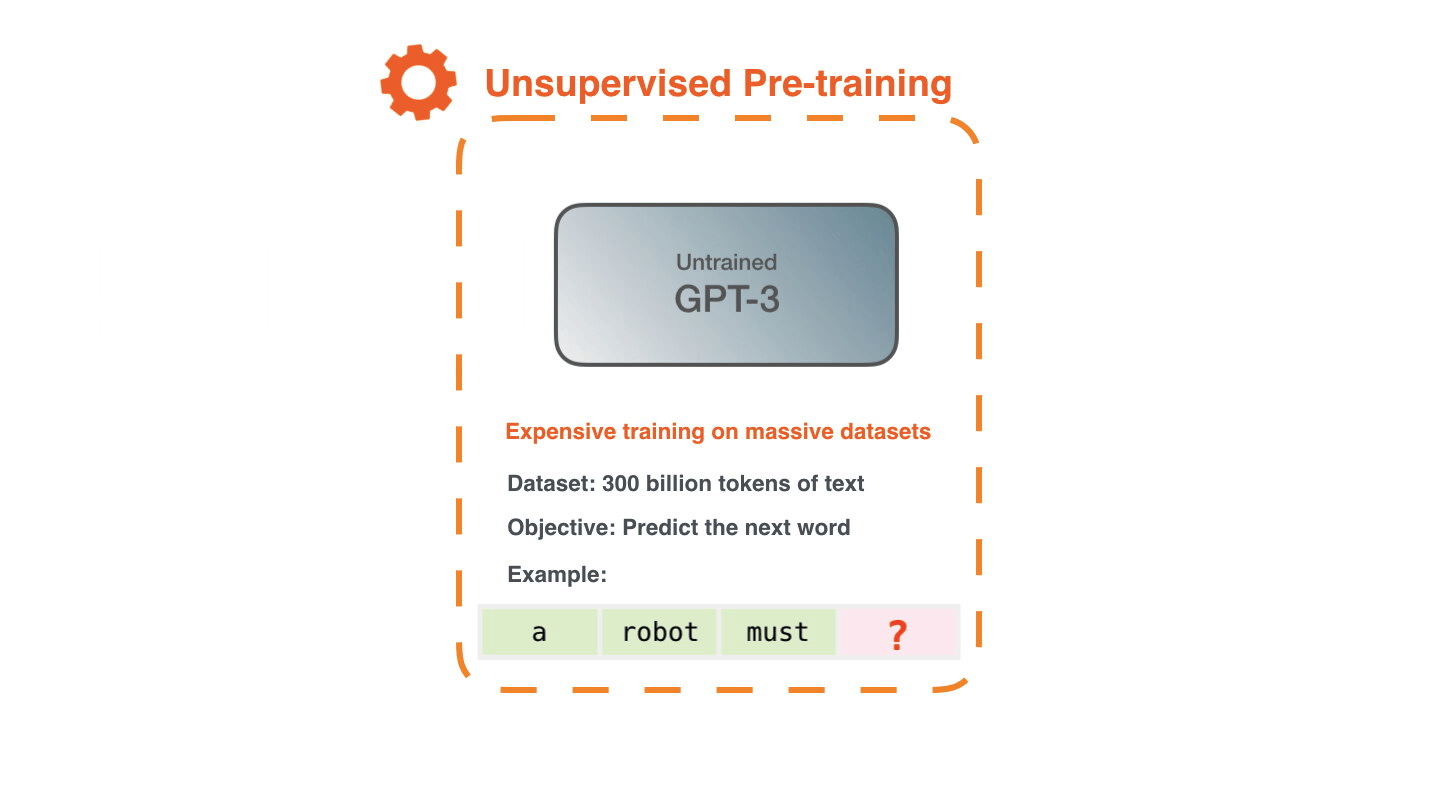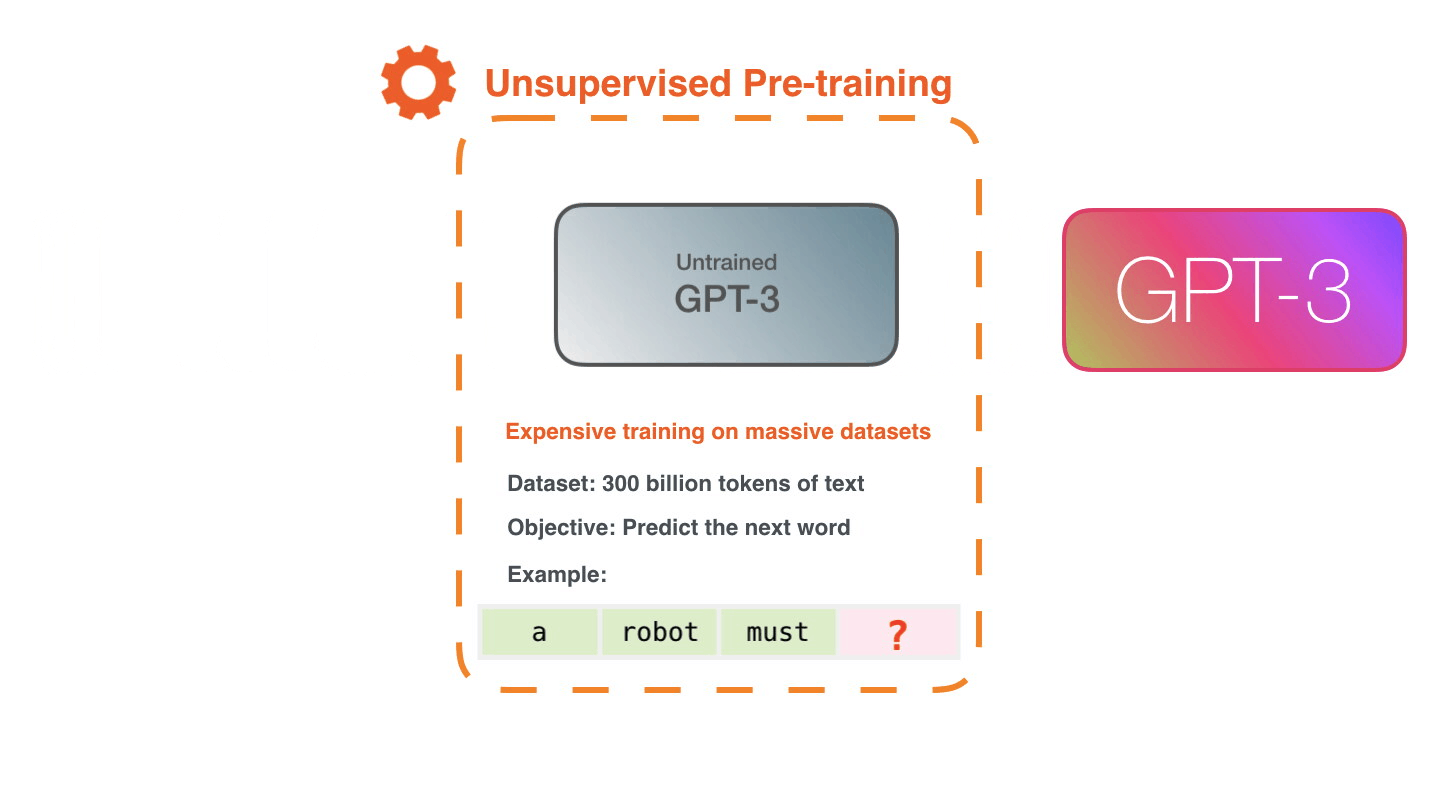
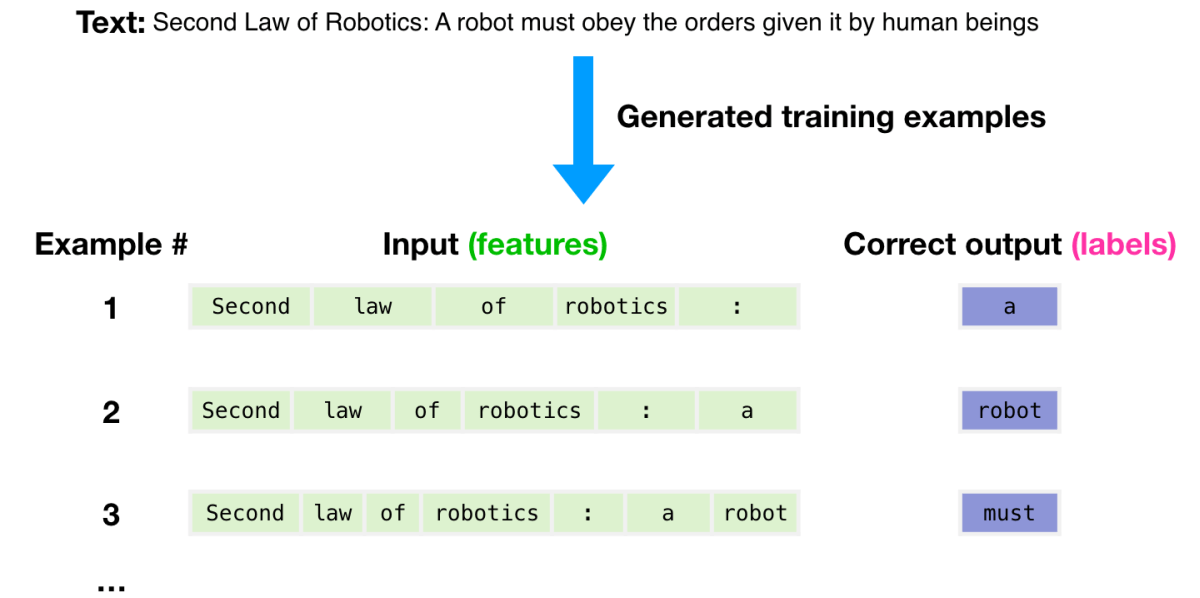
データセットに含まれるテキスト例「Second Law of Robotics: A robot must obey the orders given it by human beings」の切り取り方を変えれば、いくつもの学習例を作ることができます。この学習例を大量に生成し、GPT-3に学習させていきます。
高精度と話題のGPT-3でも、学習途中では間違えるとのこと。間違った予測と正解の誤差を計算し、誤差を学習していくという作業をGPT-3は何百万回も繰り返すとAlammar氏は説明しています。
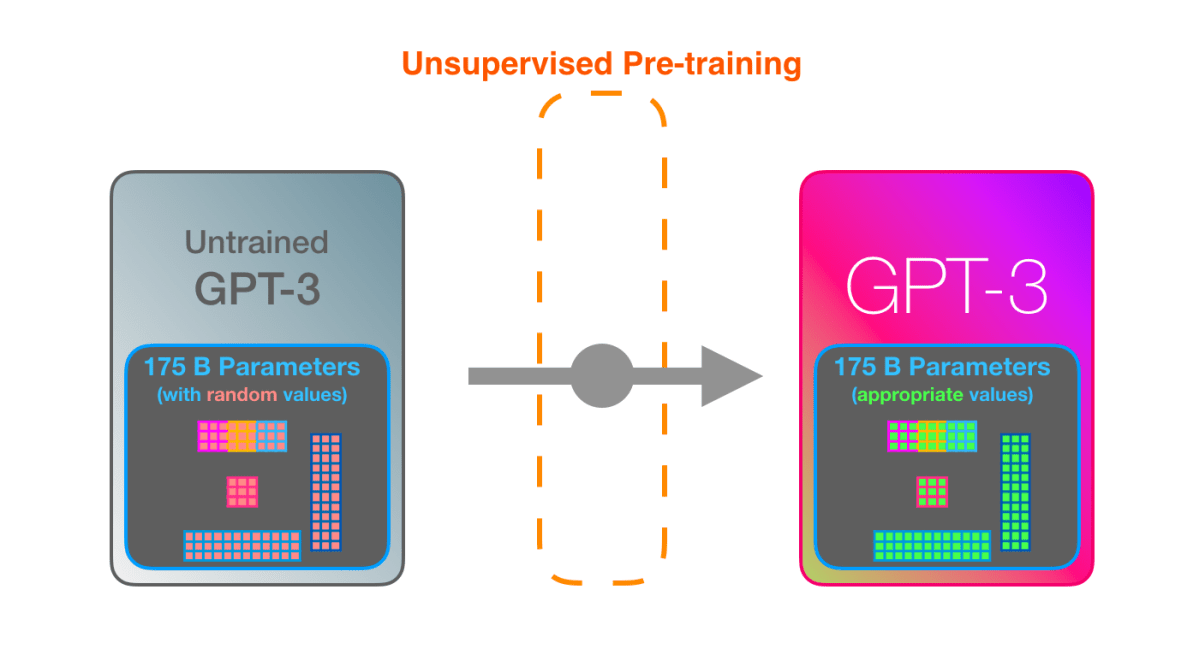
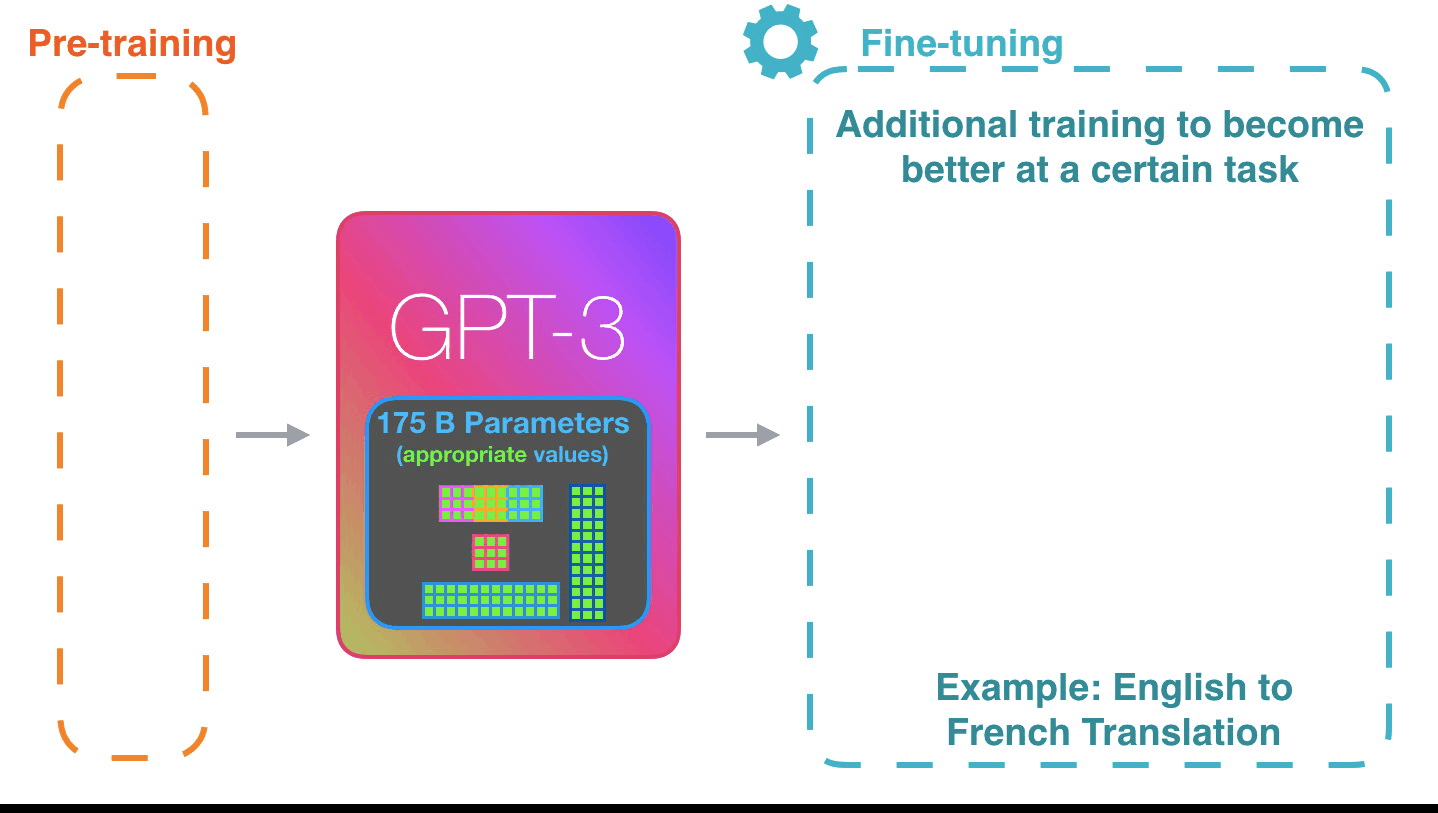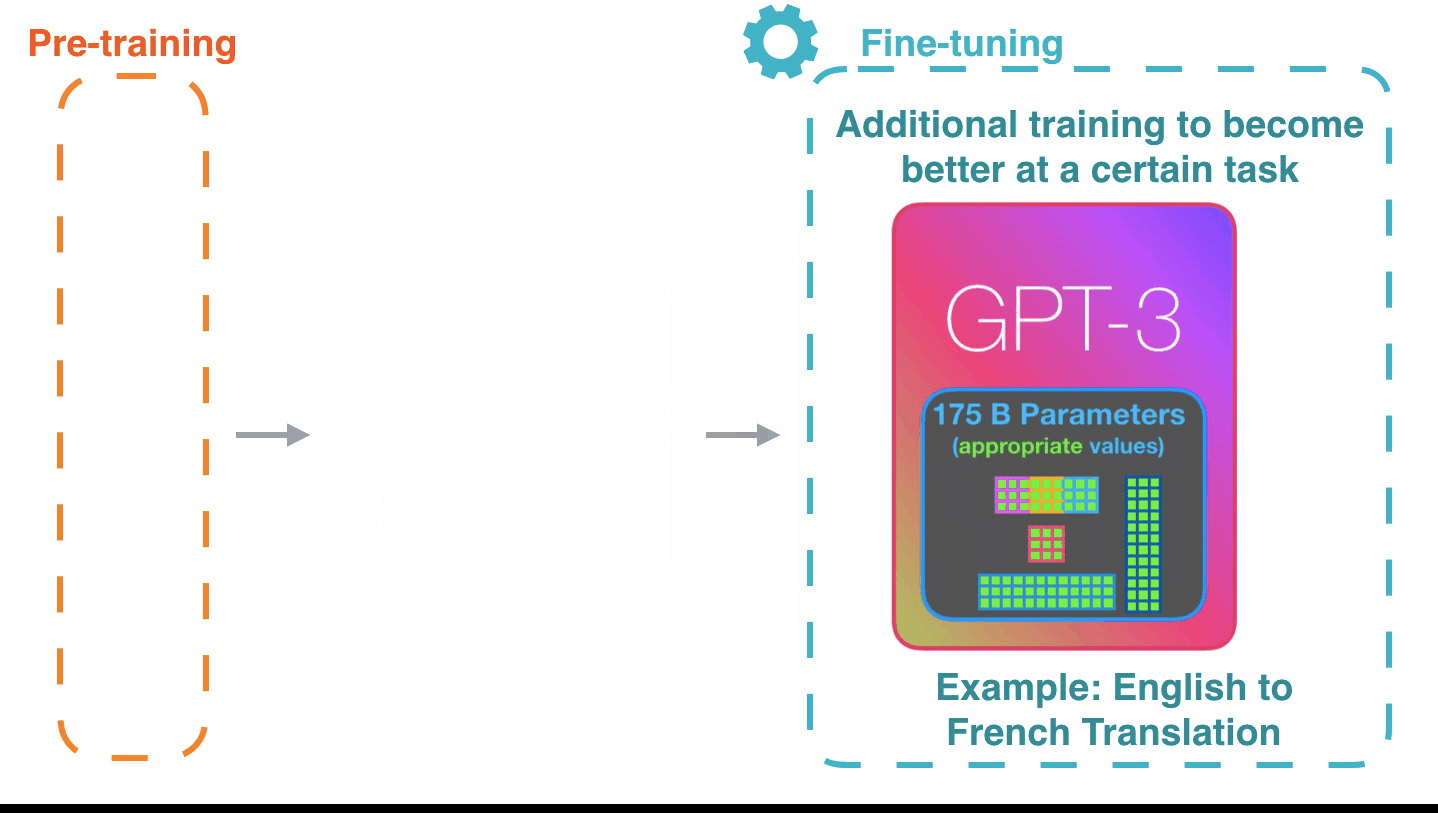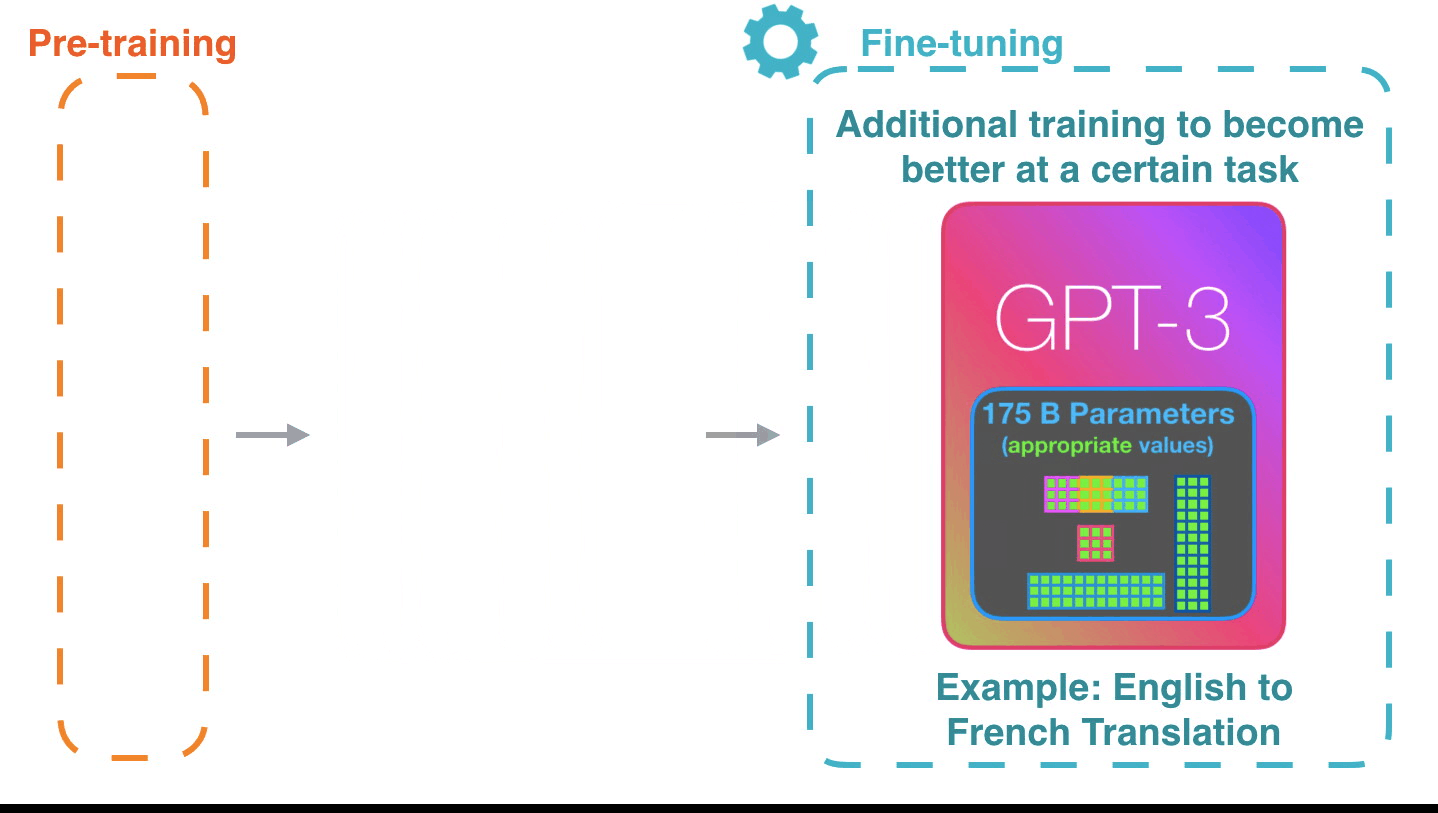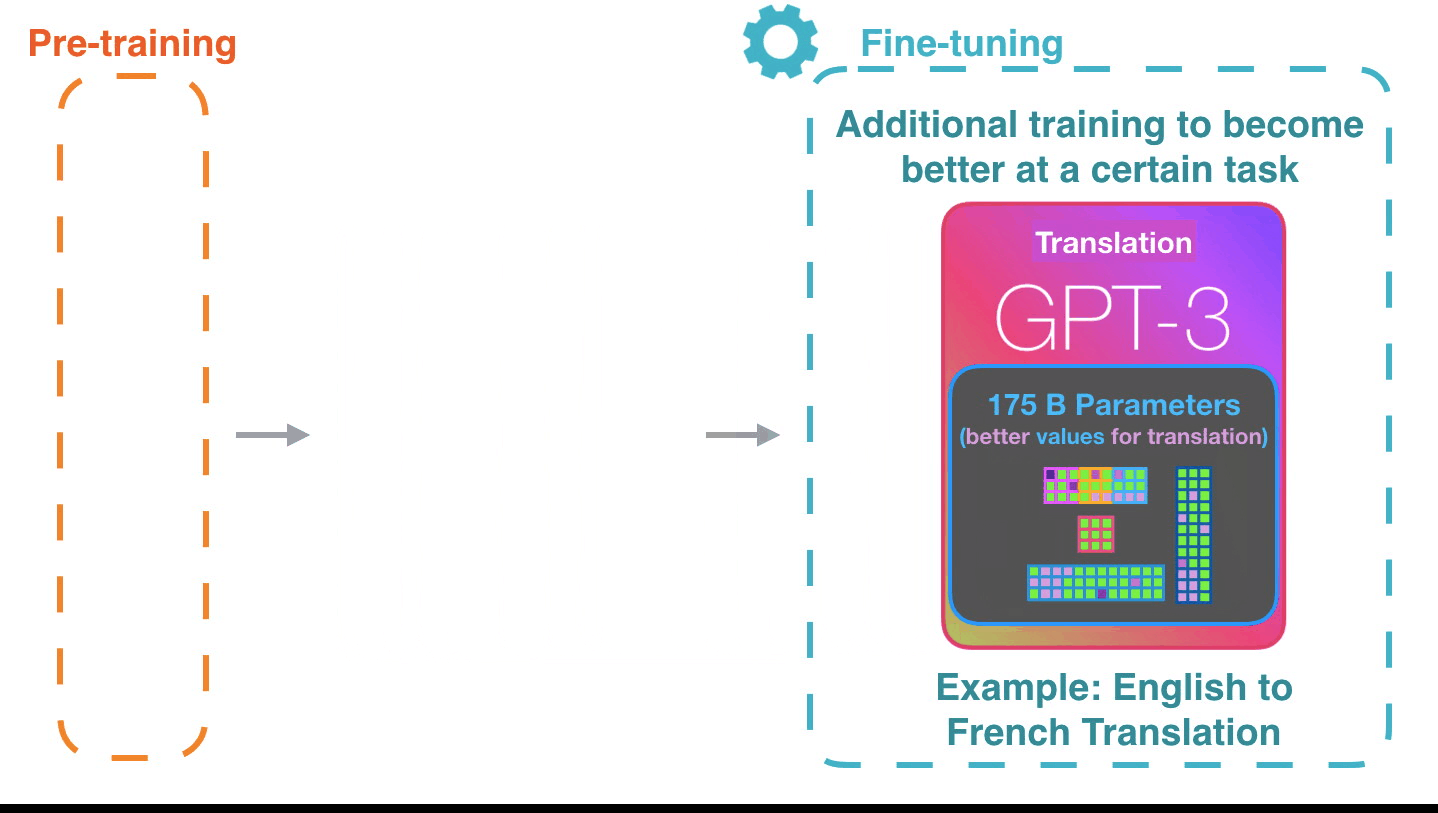
GPT-3は学習した内容を1750億ものパラメーターにエンコードし、そのパラメーターに基づいて予測を行います。パラメーターは学習前はランダムな状態ですが、学習によって精度の高い予測につながる値に調整されていくとのこと。
GPT-3は文字列を一度に入出力するのではなく、トークンと呼ばれる字句ごとに行います。GPT-3の構造はGoogleによる言語モデルである「Transformer」が基本とのこと。
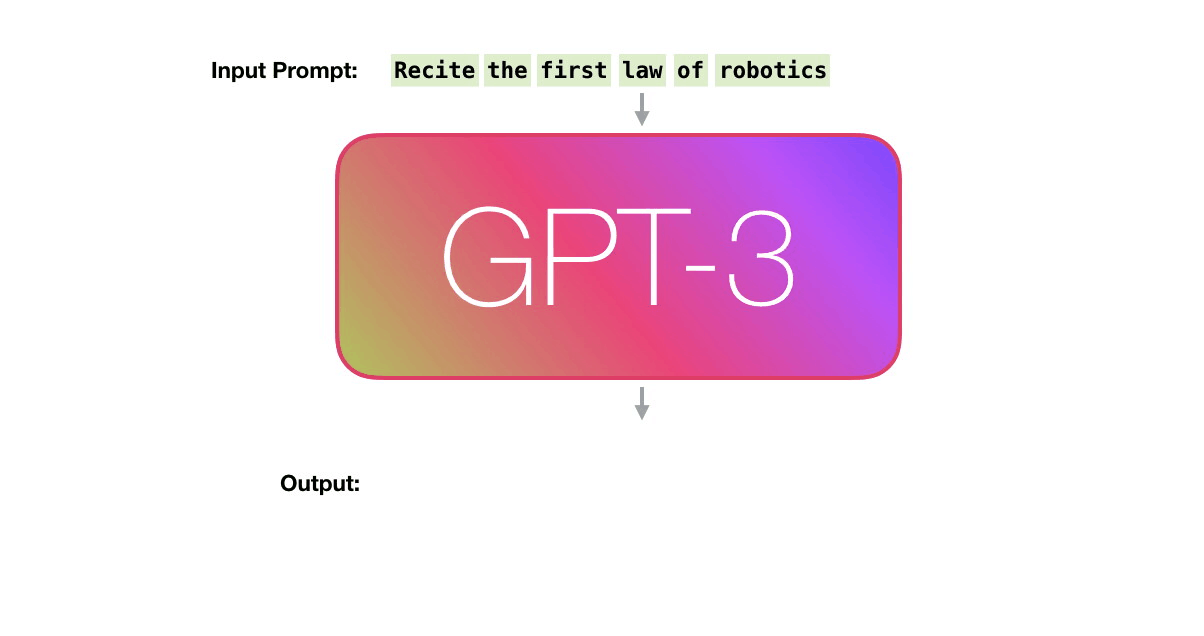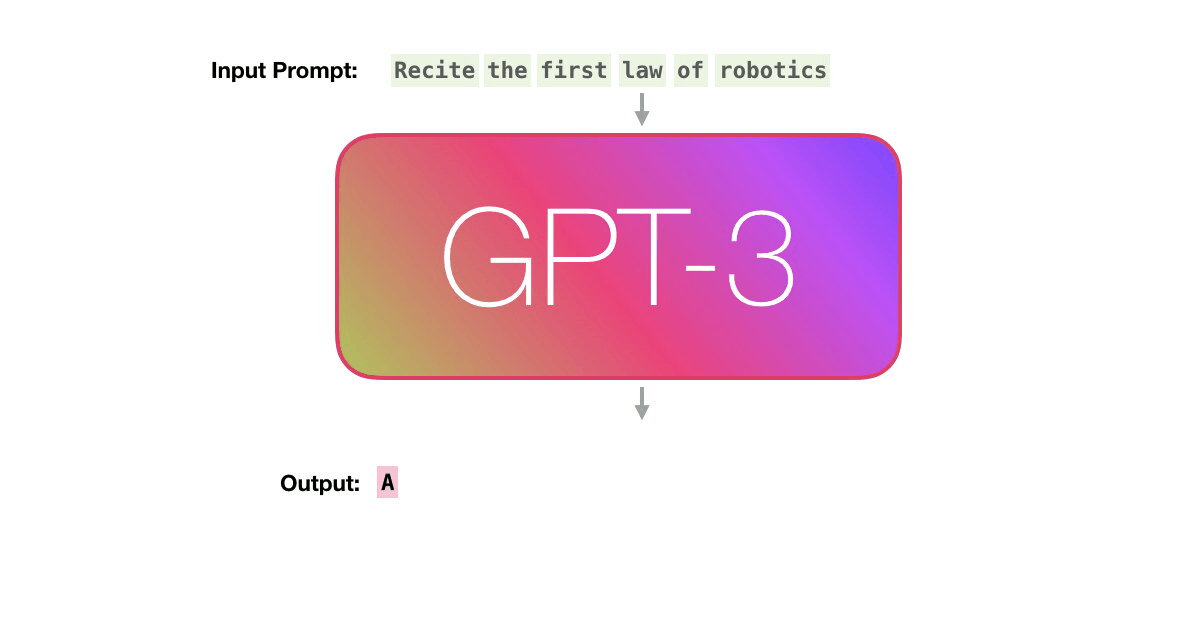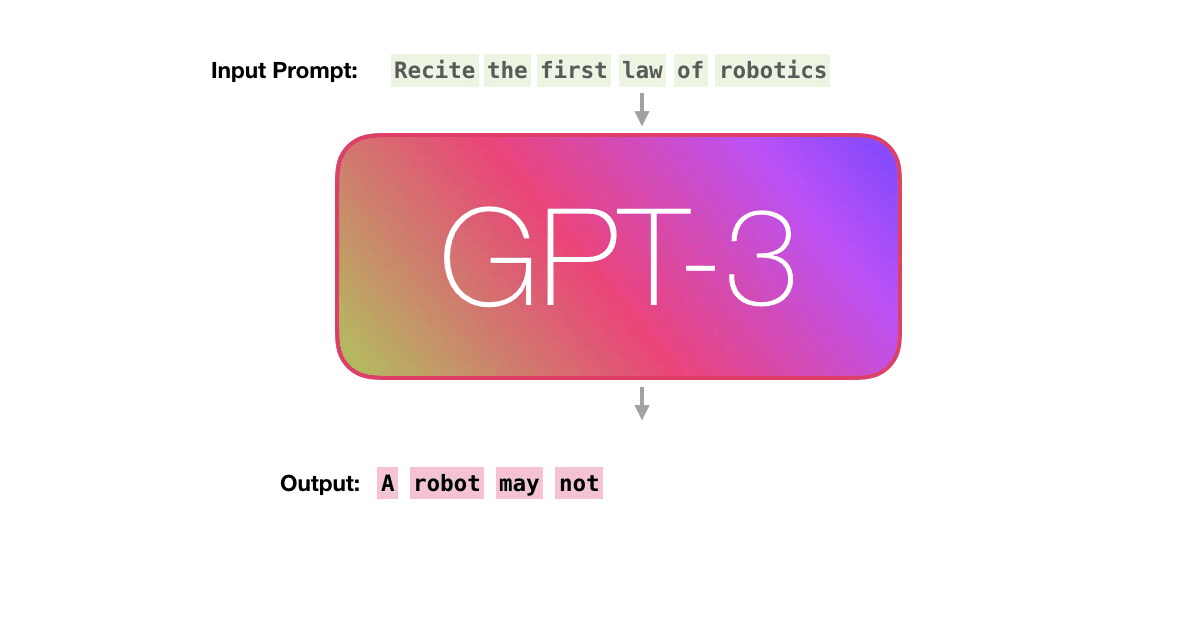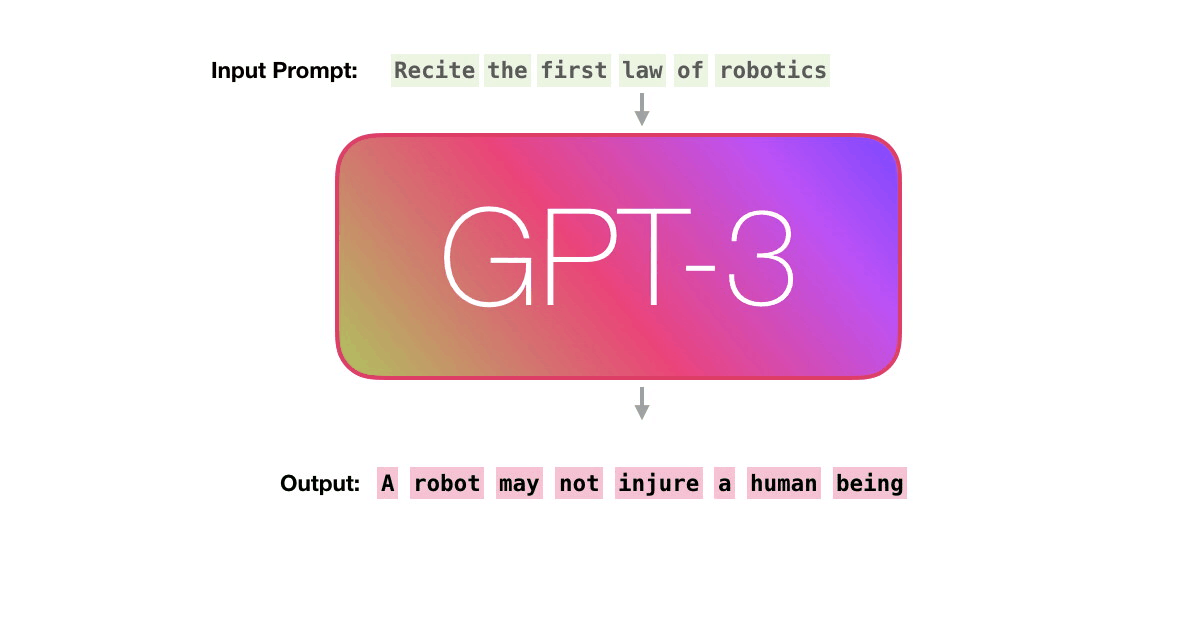
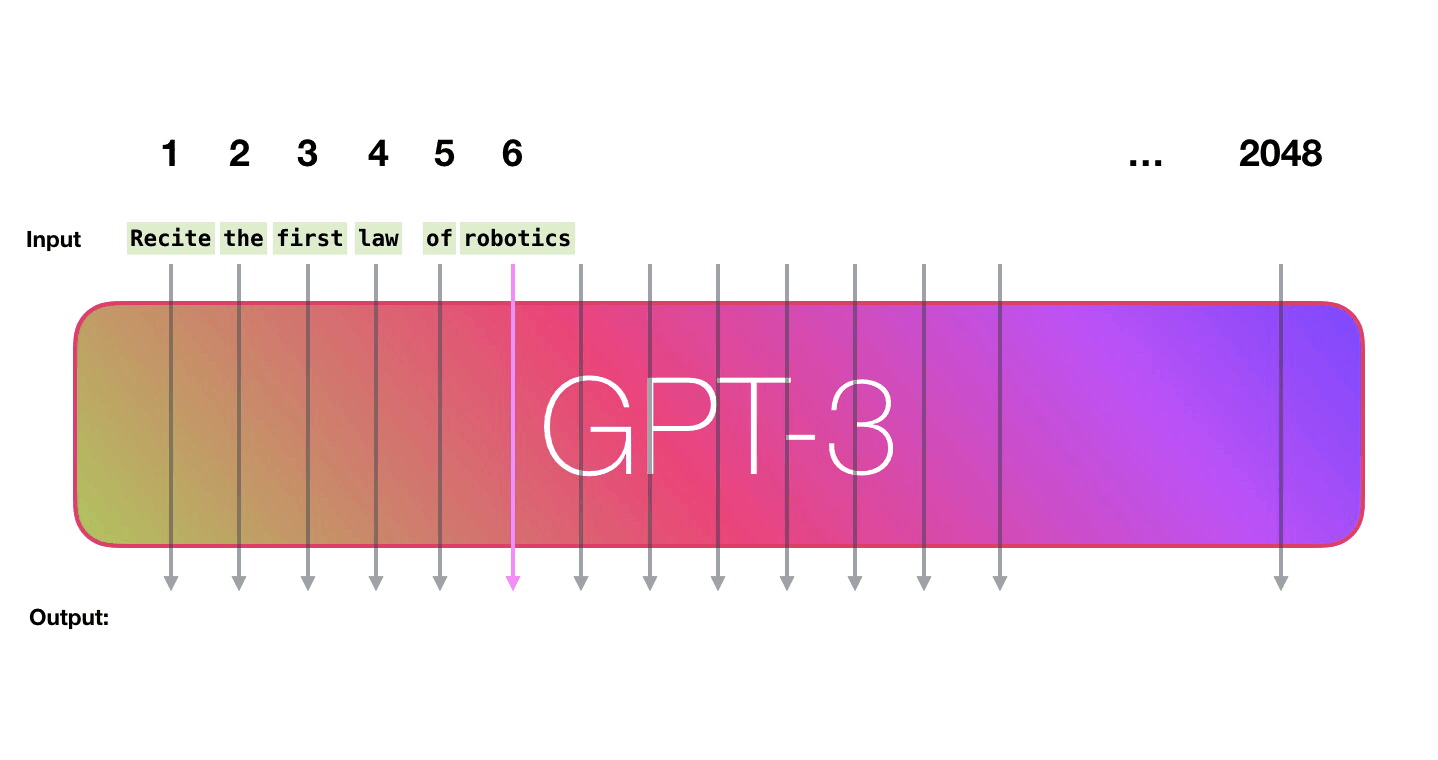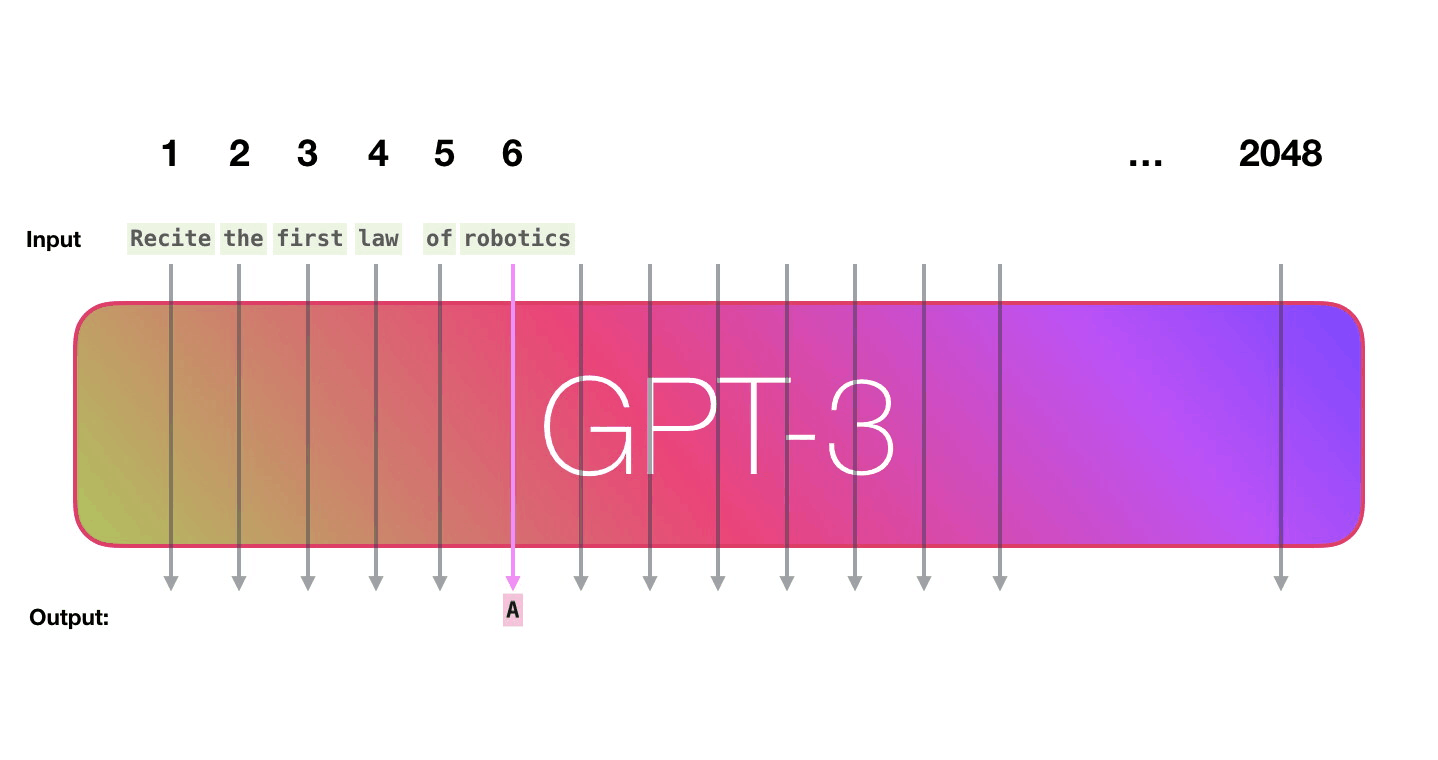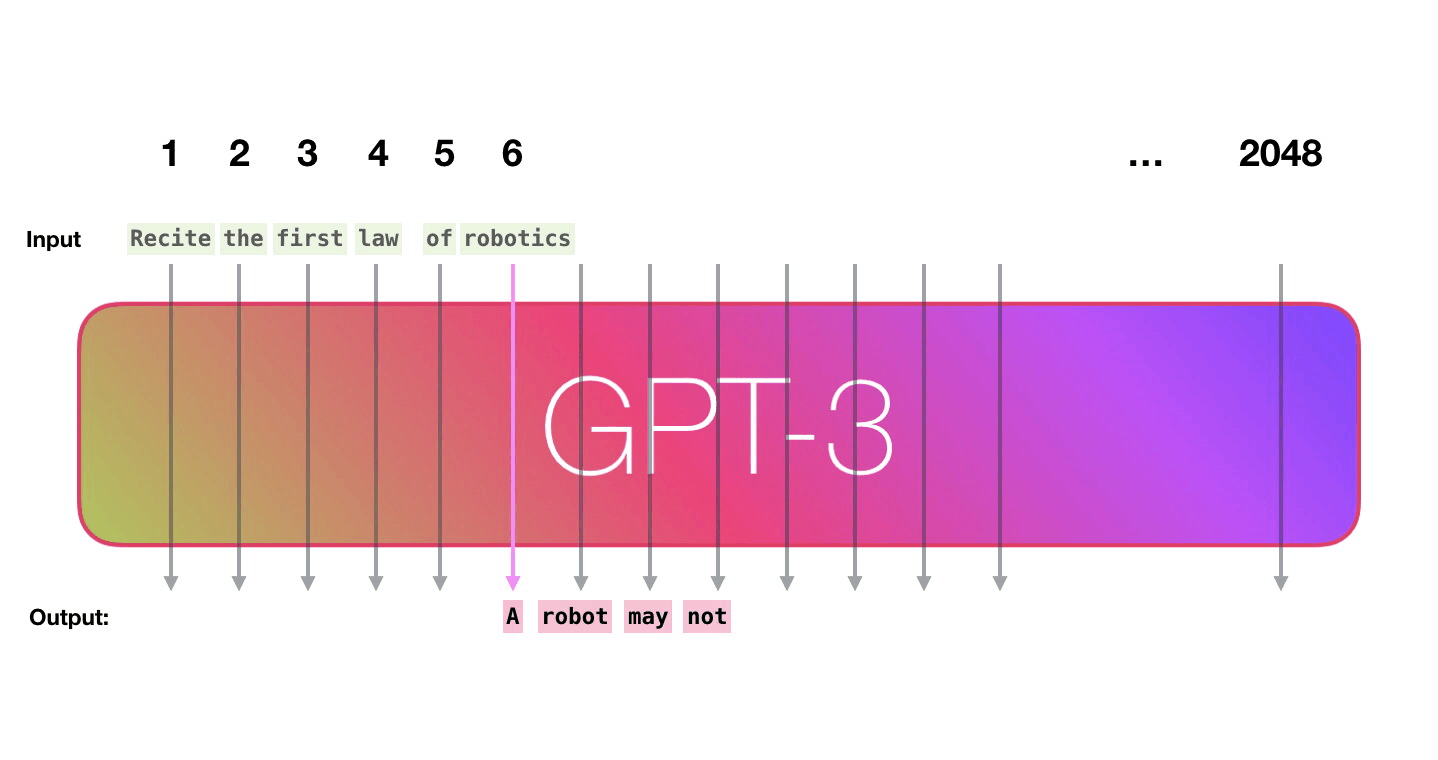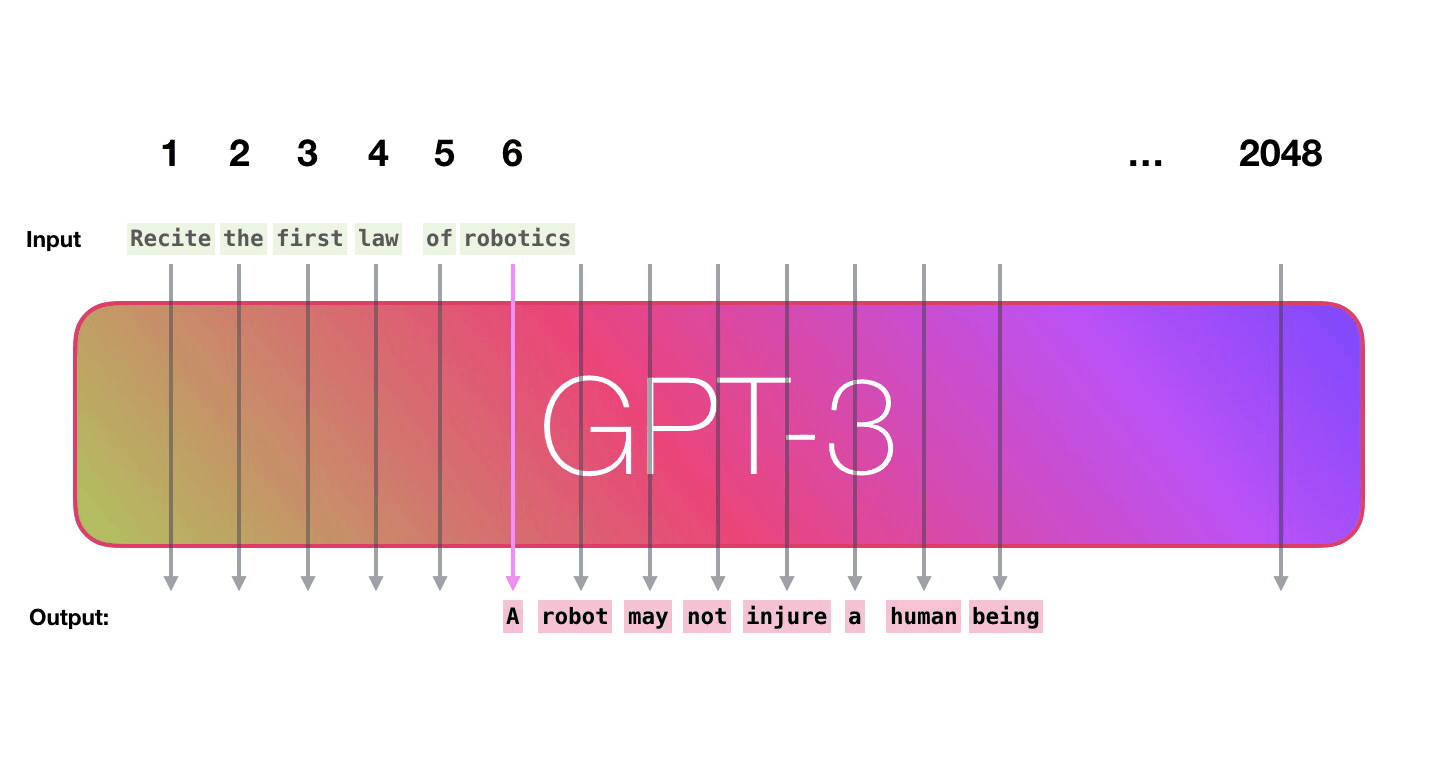
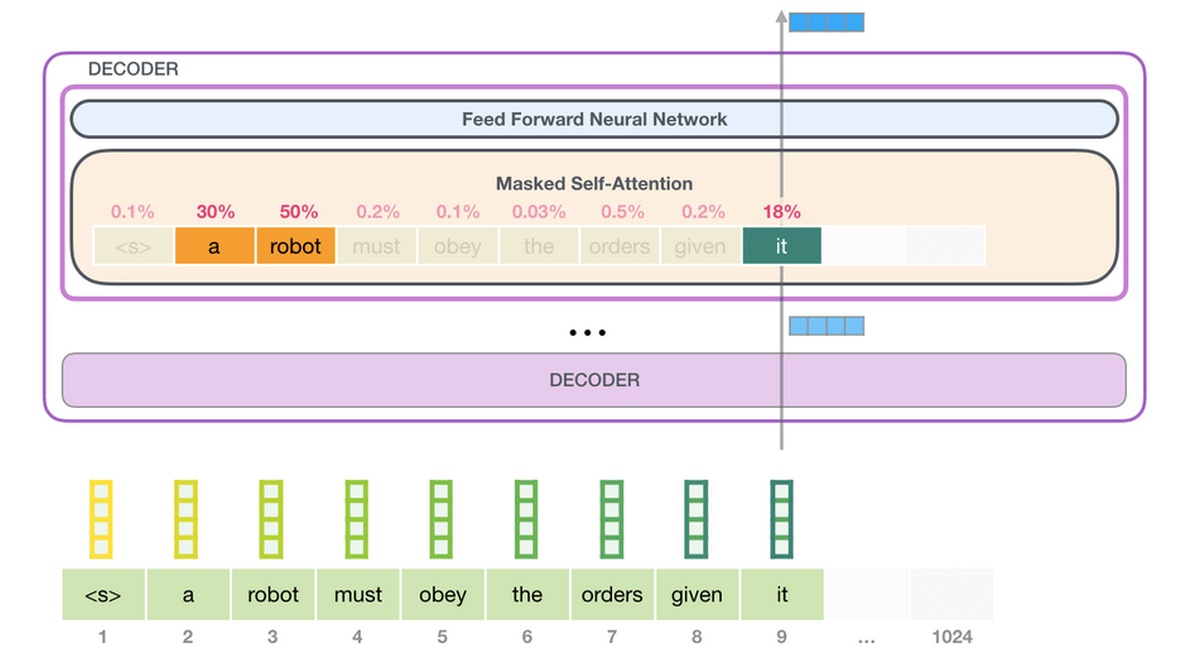
GPT-3は2048のトークンを処理可能で、GPT-2の1028トークンからの進化がうかがえます。Alammar氏はここで、6列目の「robotics」という単語から「A」という単語が生成されるまでの紫色で示された経路に注目。
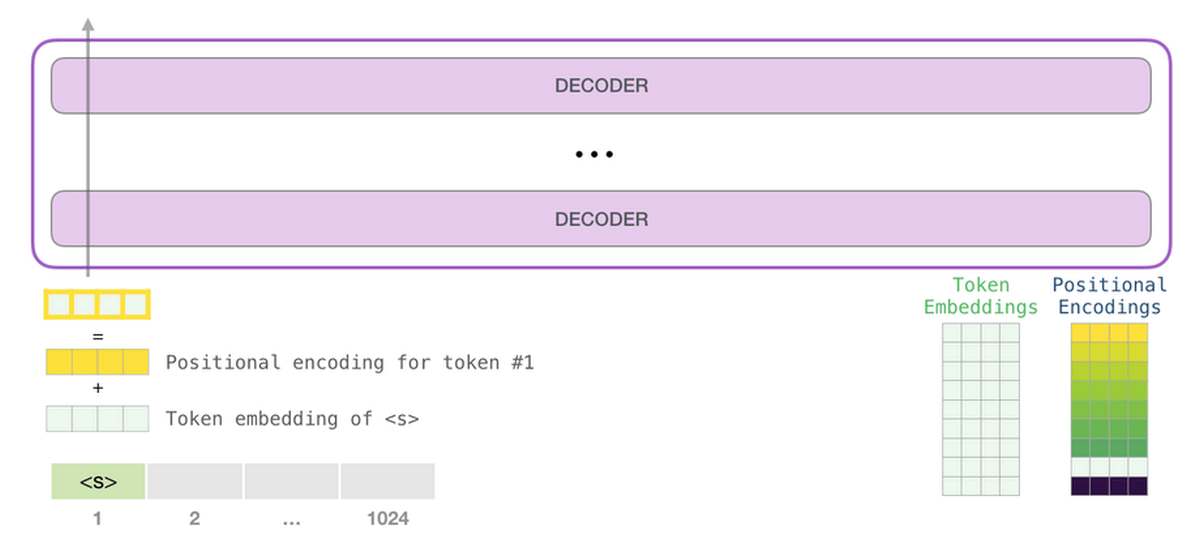
GPT-3は次のトークンを予測する1段階目の処理として、テキストをベクトルに変換する「埋め込み」を行うとともに、トークンの位置に対応した位置エンコーディングを足し合わせたベクトルを予測モデルに入力します。2段階目で入力したベクトルに基づく予測の計算を行い、3段階目の処理で予測モデルが出力したベクトルを単語に変換するとのこと。
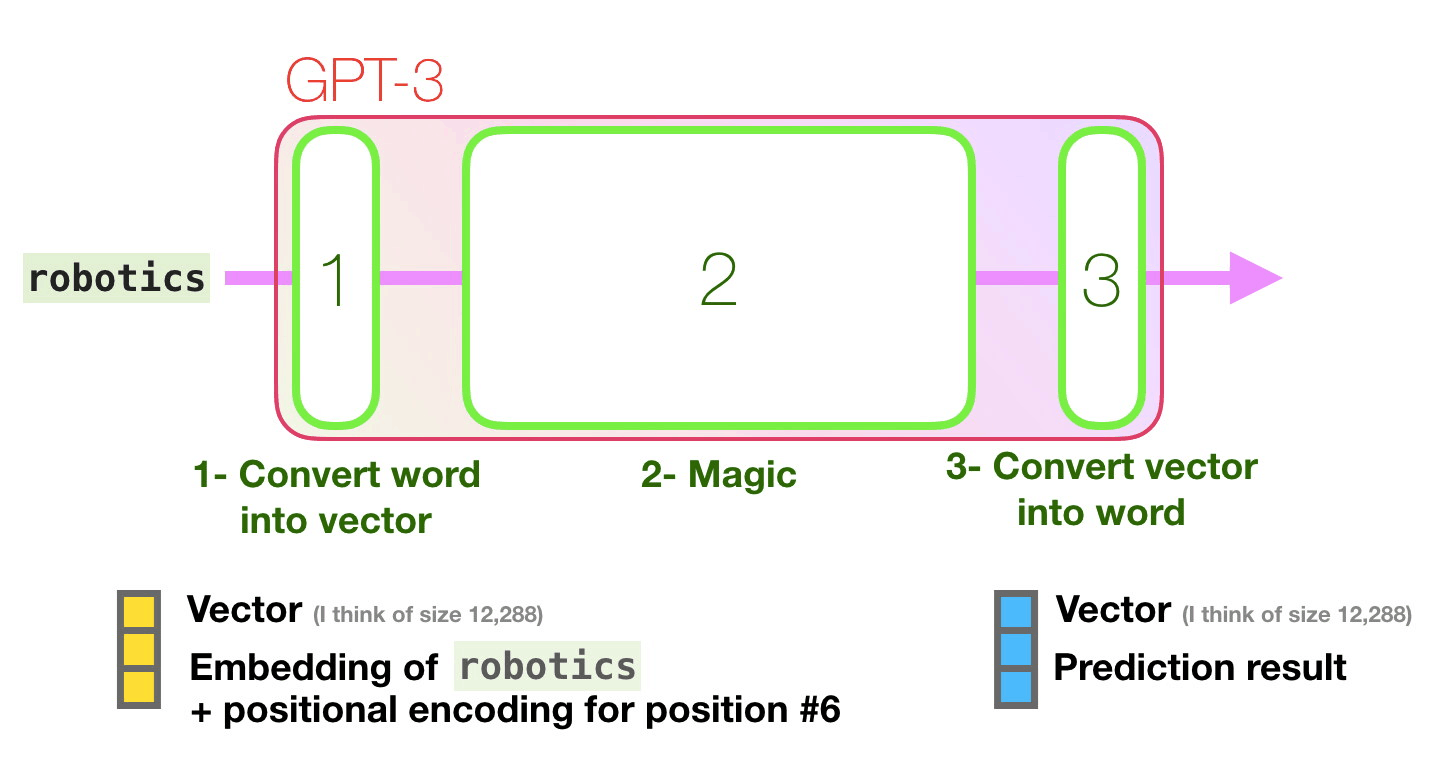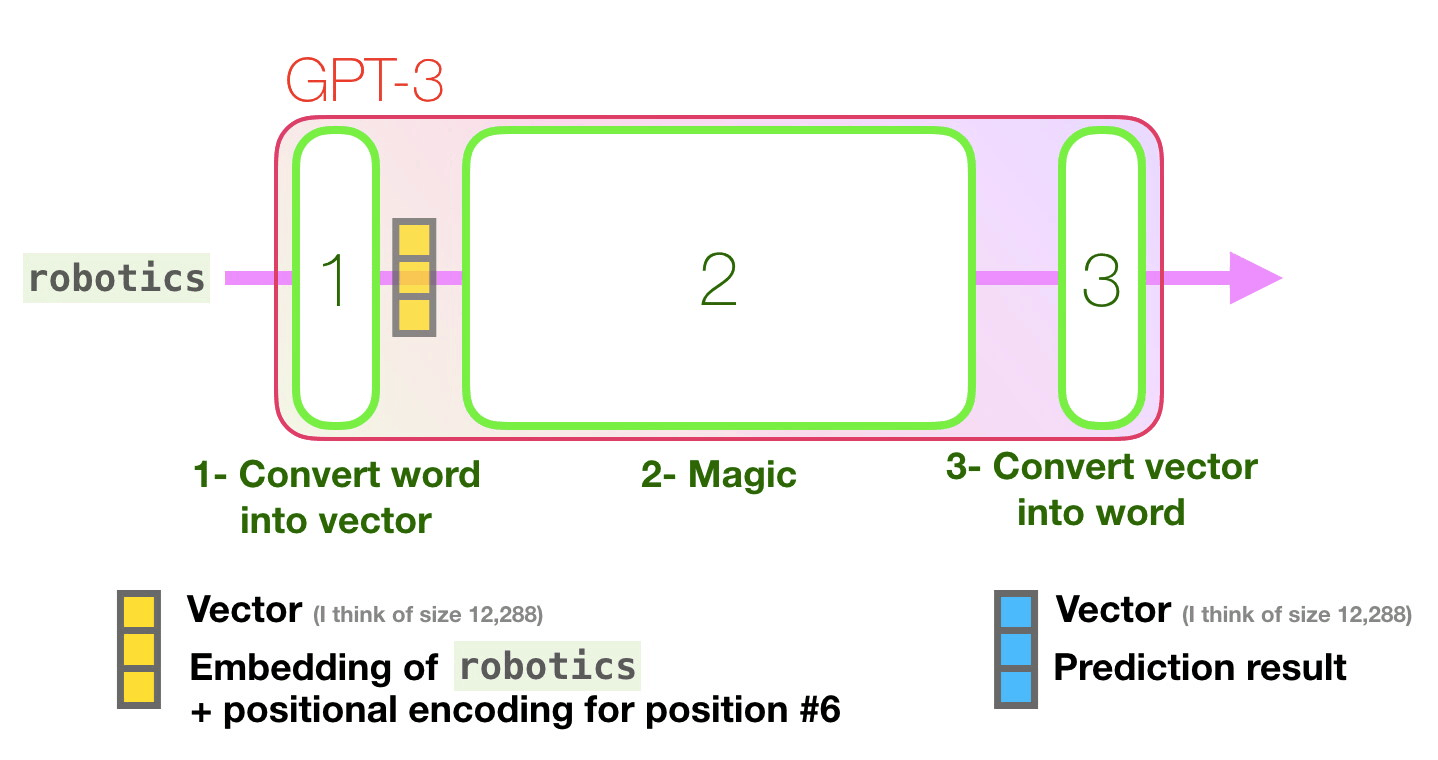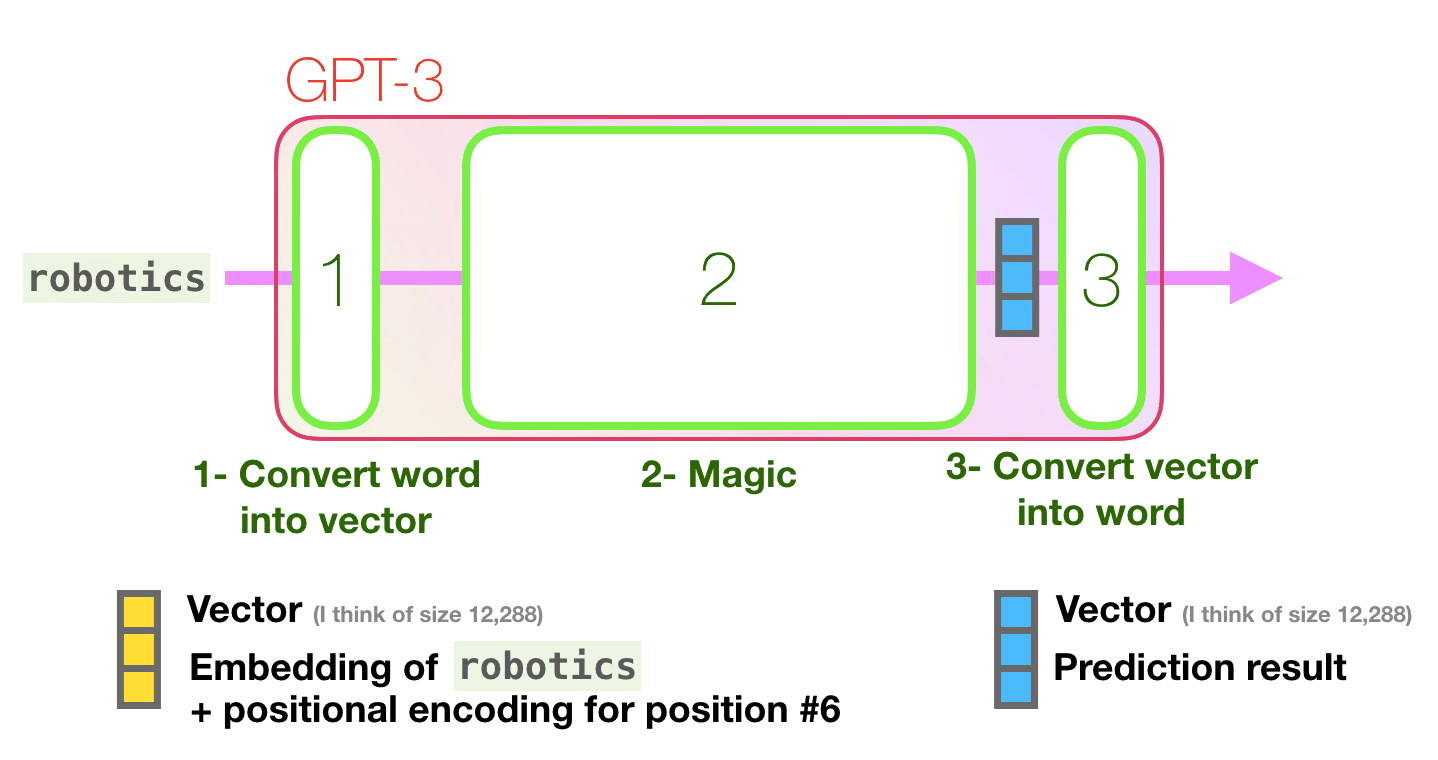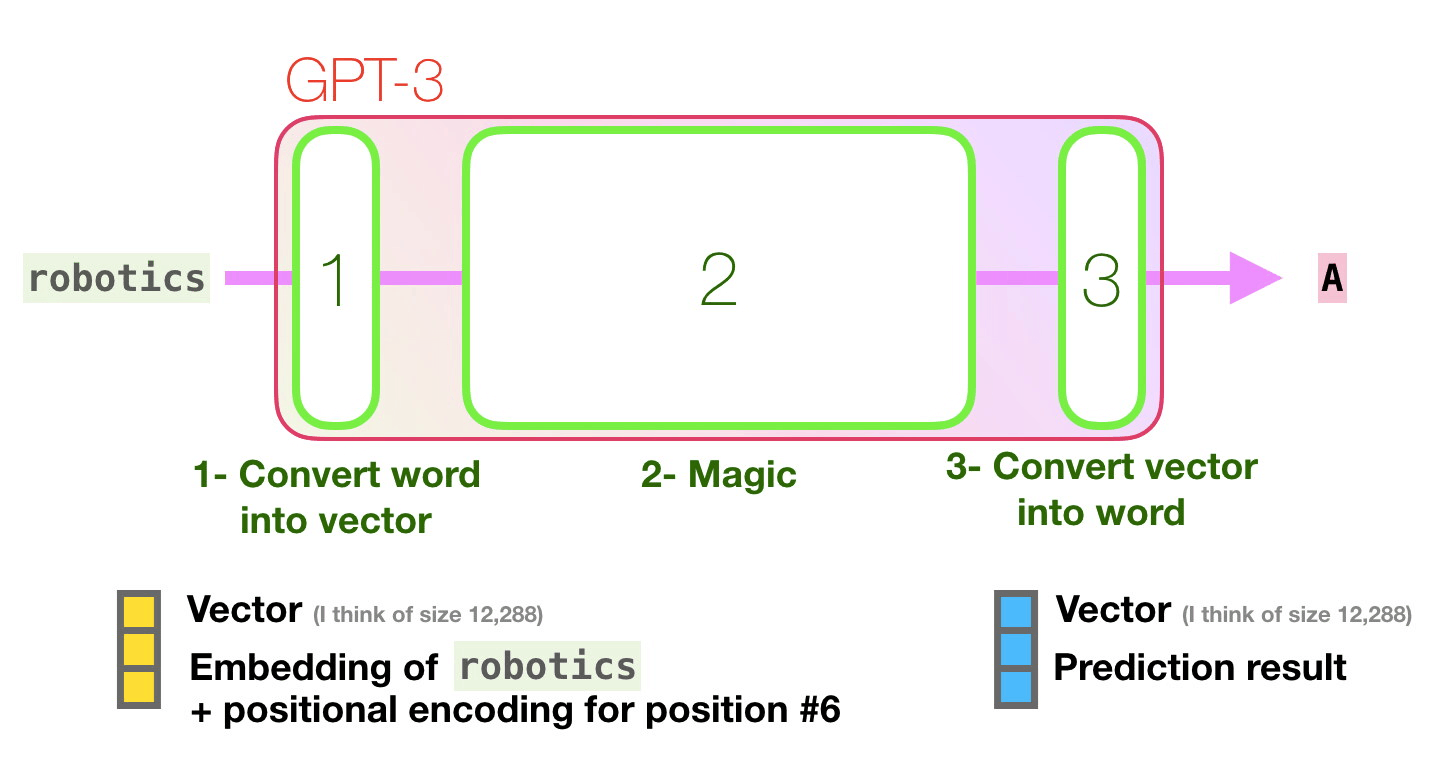
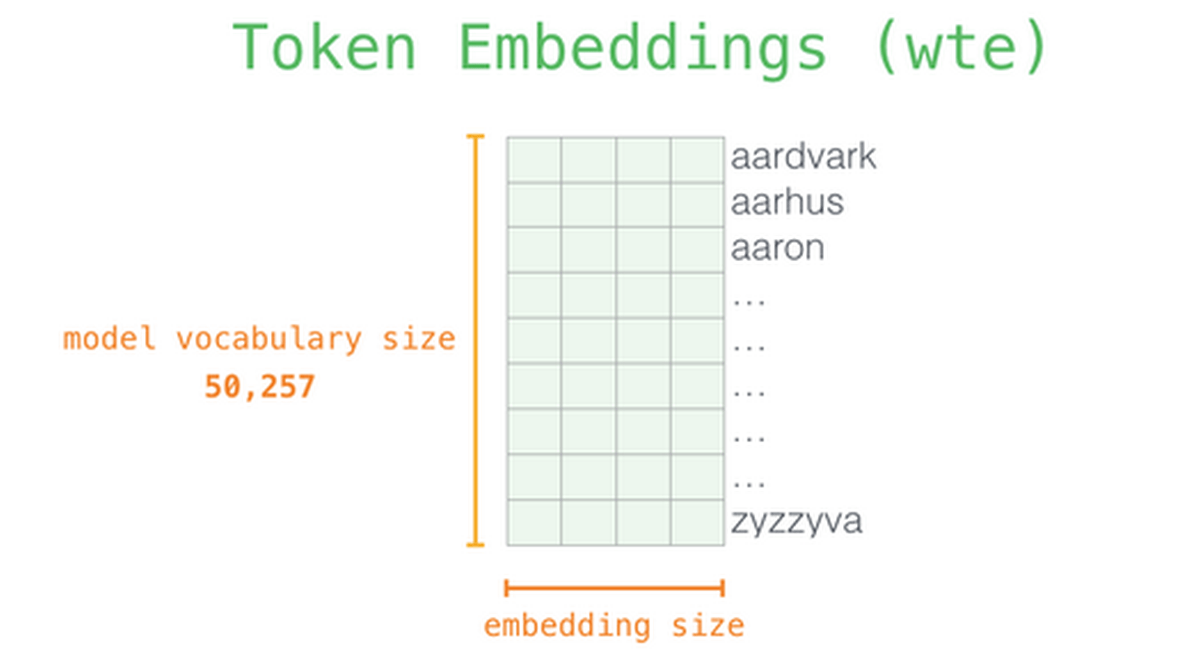
GPT-3の予測モデルは、構造においてはGPT-2のモデルと同じですが、モデルの規模が大きくなっています。第1段階で行われている埋め込みにおいて、入力されたテキストはトークンに分解され、多次元のベクトルに変換されますが、変換時のベクトルの次元にあたる「embedded size」がGPT-2では最大モデルで1600だったのに対し、GPT-3では12288となっています。
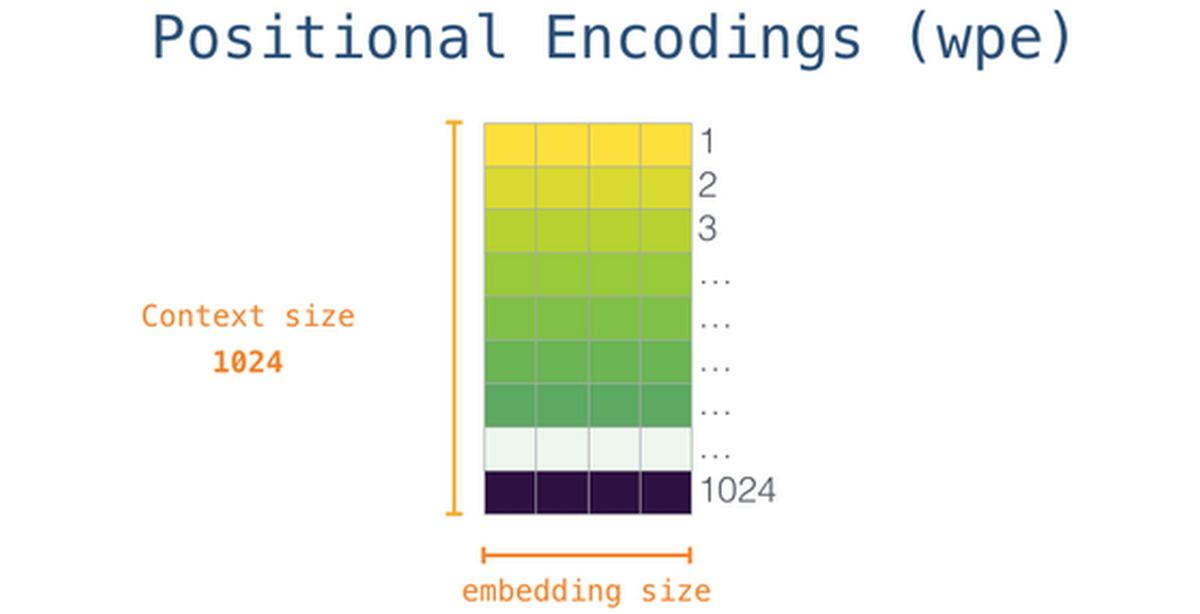
「I think, therefore I am(我思う、ゆえに我あり)」といった文章では、先に出てくる「I」と後に出てくる「I」を表現する数値は異なっているのが適切です。こうした単語の位置情報をベクトルに反映するため、GPT-3が行っているのが位置エンコーディング。下記画像はGPT-2のものであるため位置情報の細かさにつながる「context-size」、すなわち一度に処理できるトークン数が1028ですが、GPT-3では2048に拡大されており、位置情報をより詳細に反映することが可能となっています。
埋め込みによってベクトルに変換された各トークンに対し、トークンの位置に対応する位置エンコーディングが足し合わされたベクトルが予測モデルに入力されます。ここまでが第1段階の処理の詳細です。
言語は背景に強く左右されるものであるとAlammar氏は指摘。例えば「A robot must obey the orders given it by human beings except where such orders would conflict with the First Law.」という英文において、「it」や「such orders」といった単語が何を指すのかを理解していないと、文章を理解することはできません。こうした言語の背景を取り込むためにGPT-3が行っているのが「Self-Attention」です。Self-Attentionでは、各トークンがお互いにどのくらい関係があるかというスコアを計算し、そのスコアをベクトルで表現して加算することで、トークン間の関係性を表現するとのこと。
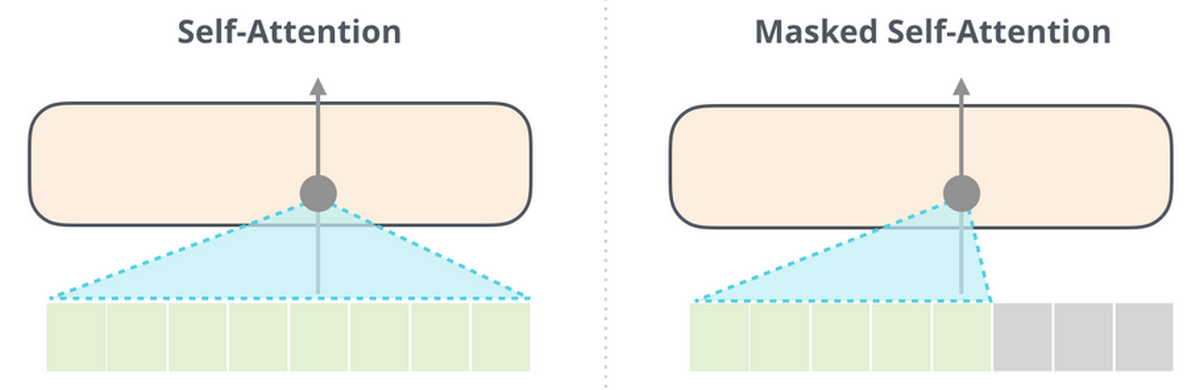
Self-AttentionにおけるGPT-2とGPT-3の違いは、密なSelf-Attentionと疎なSelf-Attentionが交互に存在することであるとAlammar氏。入力がすべて完了するまではトークンの出力が次の入力に影響を与えませんが、入力が終わり予測の段階に入ると、出力が次の入力に影響を与えるようになっています。
![]()
なお、GPT-3ではSelf-Attentionをテキスト前方の領域に対してのみ行っていますが(Masked Self-Attention)、同じ言語処理モデルであるBERTはSelf-Attentionを全領域において行います。
GPT-3はこうした一連の処理を行うデコード層を96層も有しており、GPT-2の最大モデルが持つ48層の2倍にまで強化されています。デコード層で予測にあたるベクトルが出力されるまでが第2段階で、第3段階でベクトルを単語に変換することで、単語の予測が完了するとのこと。
![]()
Alammar氏は特定のタスクでパフォーマンスを上げるようにモデルを調整するファインチューニングが行われれば、GPT-3の可能性はさらに広がると語っています。
・関連記事
あまりに高精度のテキストを作り出してしまうため「危険すぎる」と問題視された文章生成言語モデルの最新版「GPT-3」が公開 - GIGAZINE
超高精度な言語モデル「GPT-3」は本当に「人間そのもの」な会話ができるのか実験した結果は? - GIGAZINE
「GPT-3はビットコイン以来の破壊的な可能性を秘めている」というブログ記事が大反響を呼ぶ理由とは? - GIGAZINE
Googleの新たな自然言語処理モデル「ALBERT」はどのように進化したのか? - GIGAZINE
ディープラーニングで翻訳プログラムを0から作った人がその仕組みを複雑な数式ではなく図で解説するとこうなる - GIGAZINE
より高い品質の翻訳を実現するGoogleの「Transformer」がRNNやCNNをしのぐレベルに - GIGAZINE
・関連コンテンツ






in ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article How is the language of the super-accurat….