How is the language of the super-accurate language model 'GPT-3' spinning enough to write a natural blog?

'GPT-3' developed by
How GPT3 Works-Visualizations and Animations – Jay Alammar – Visualizing machine learning one concept at a time.
https://jalammar.github.io/how-gpt3-works-visualizations-animations/
The Illustrated GPT-2 (Visualizing Transformer Language Models) – Jay Alammar – Visualizing machine learning one concept at a time.
https://jalammar.github.io/illustrated-gpt2/
[2005.14165] Language Models are Few-Shot Learners
https://arxiv.org/abs/2005.14165
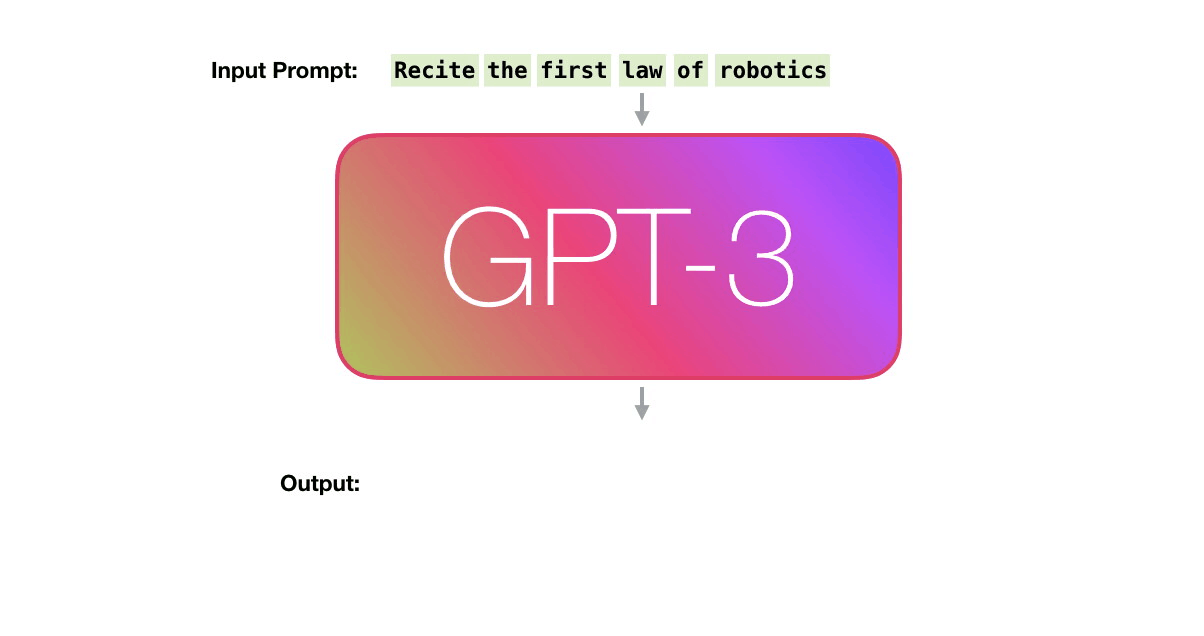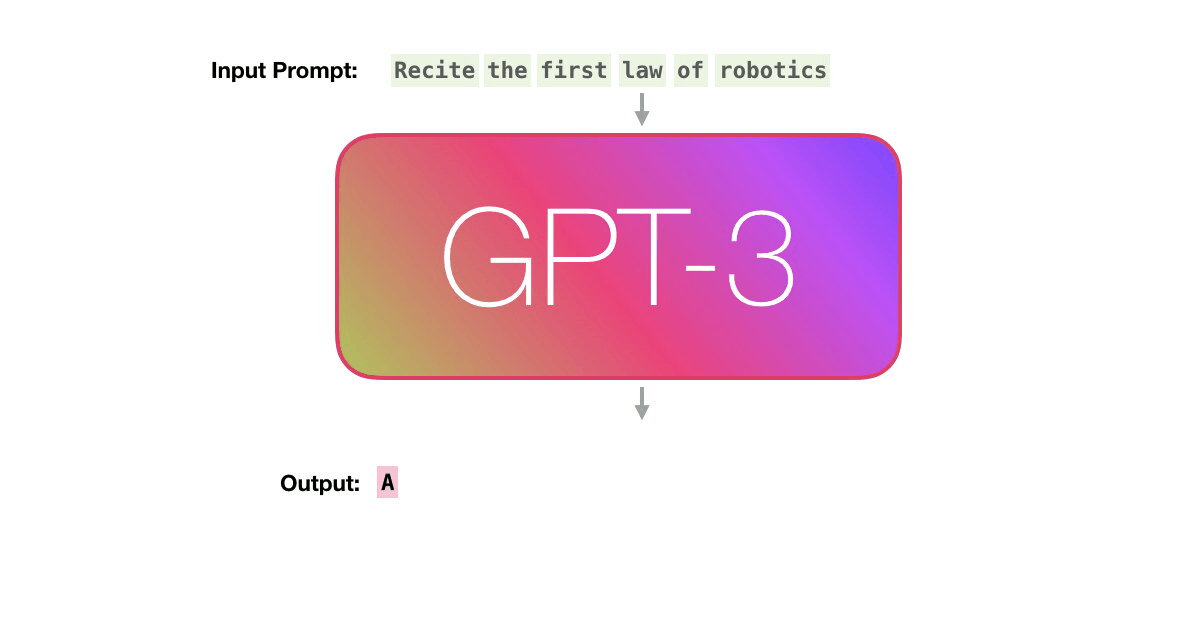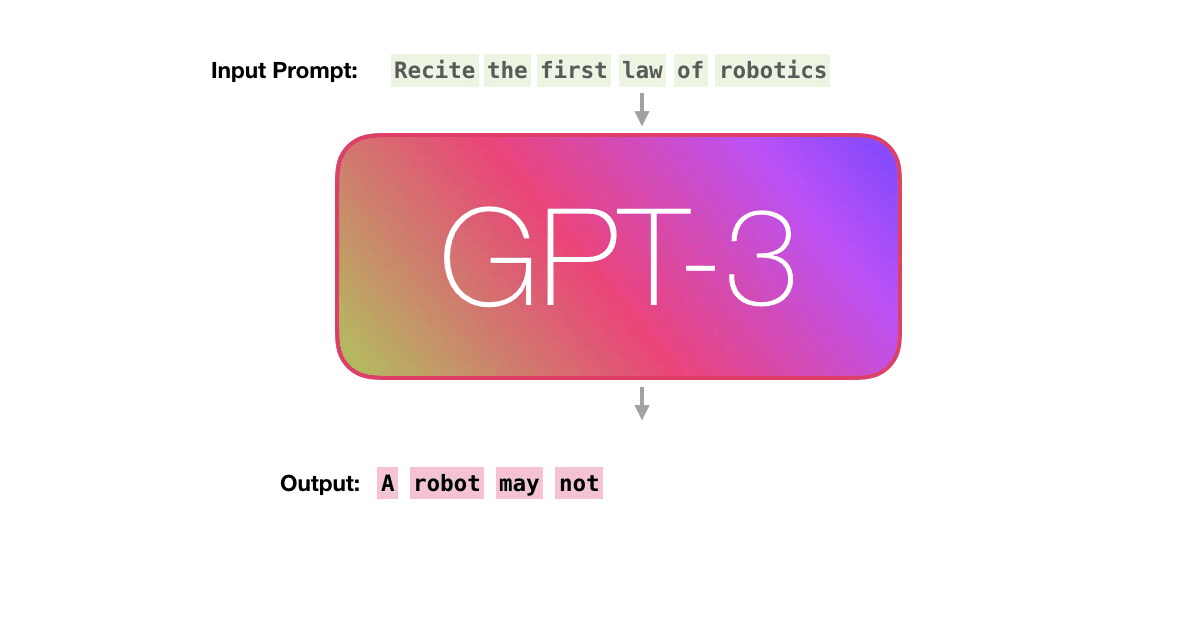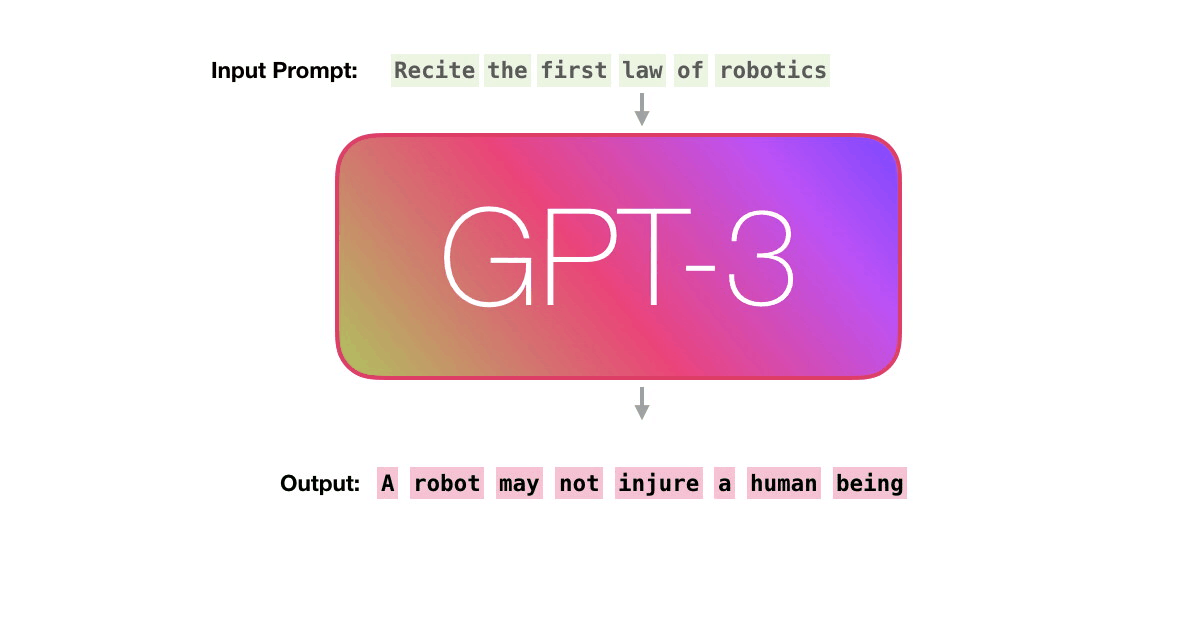
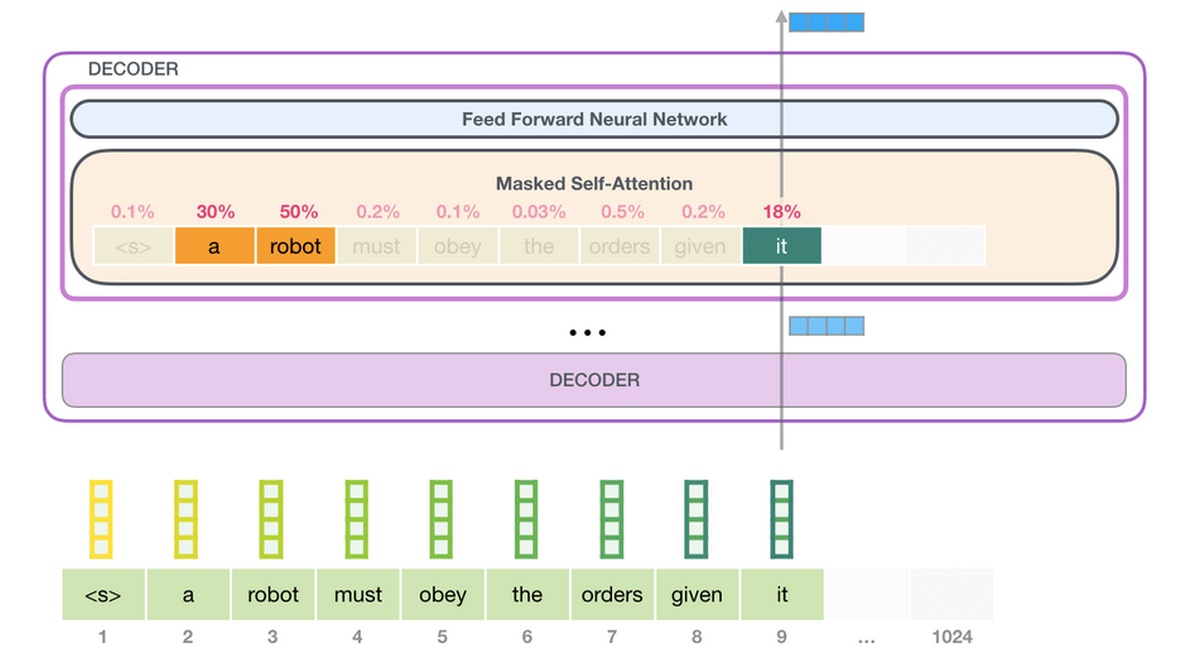
GPT-3 says that it is conducting training using a large-scale data set containing as many as 300 billion words. ' Unsupervised Pre-training ', in which feature patterns are learned without giving correct answers, is trained to predict the 'next word' from the data set. For example, the next word in the sequence of words “a”, “robot”, and “must” is learned without the correct answer as to what the next word is. According to Alammar, learning GPT-3 costs $4.6 million (about 490 million yen), and if you use one GPU, it will take 355 years to calculate.
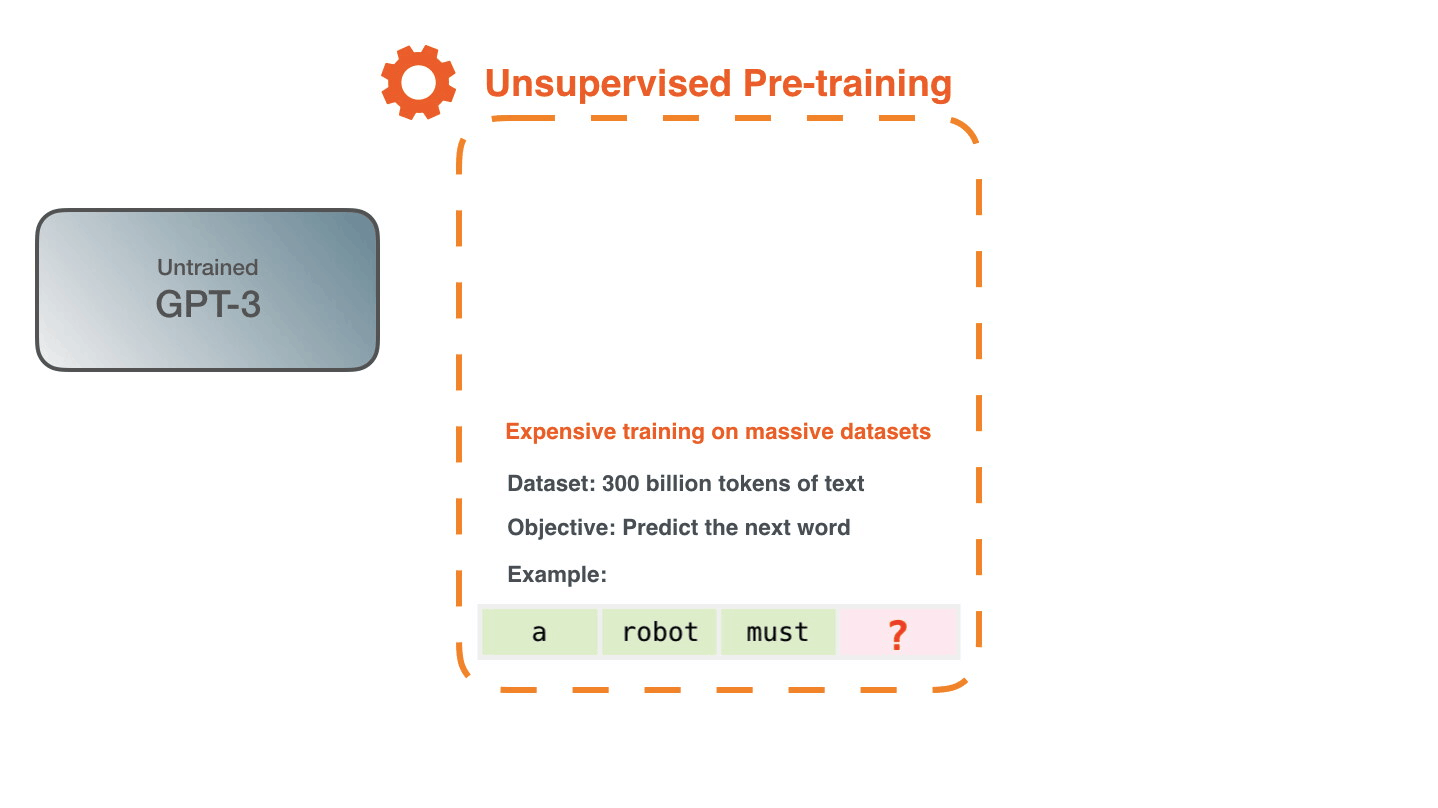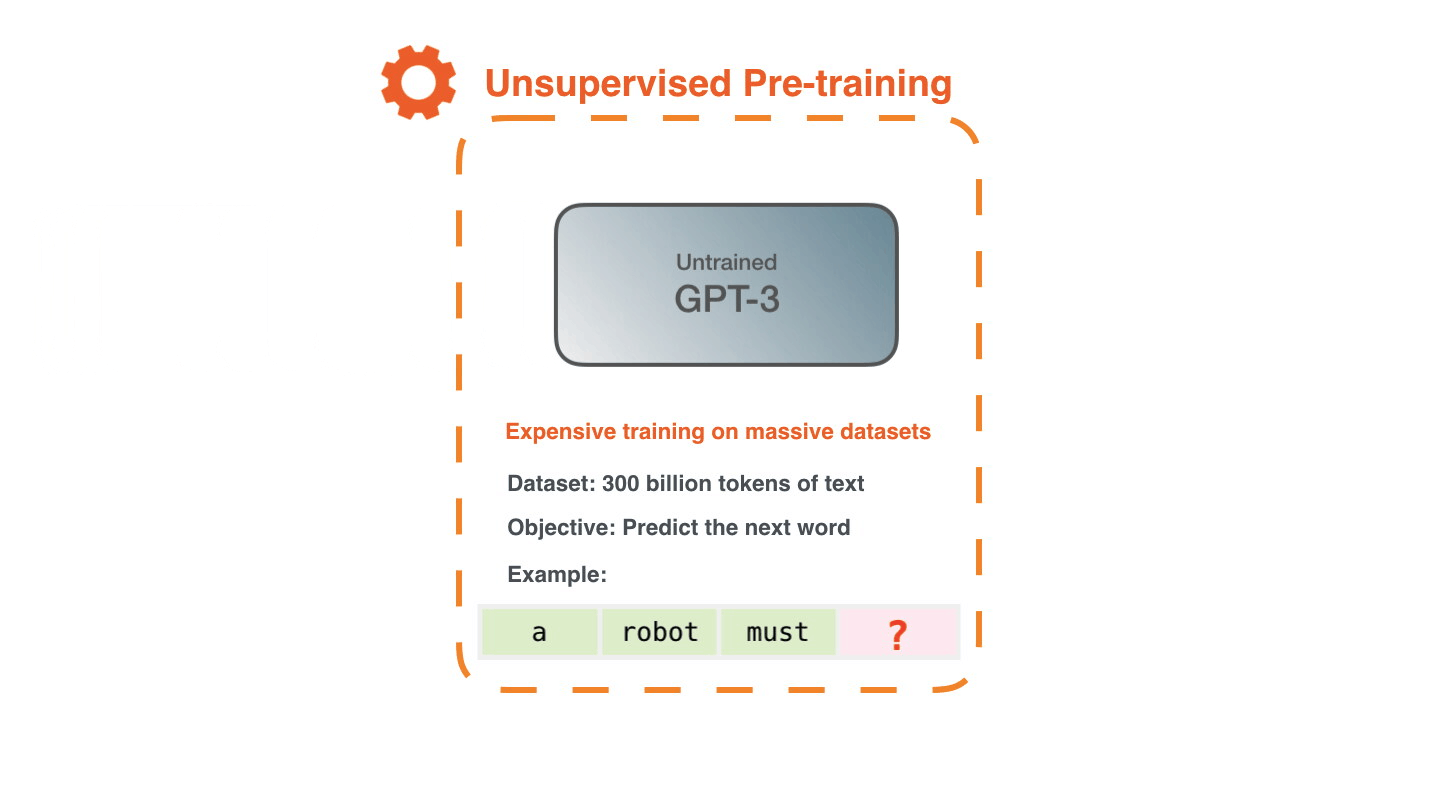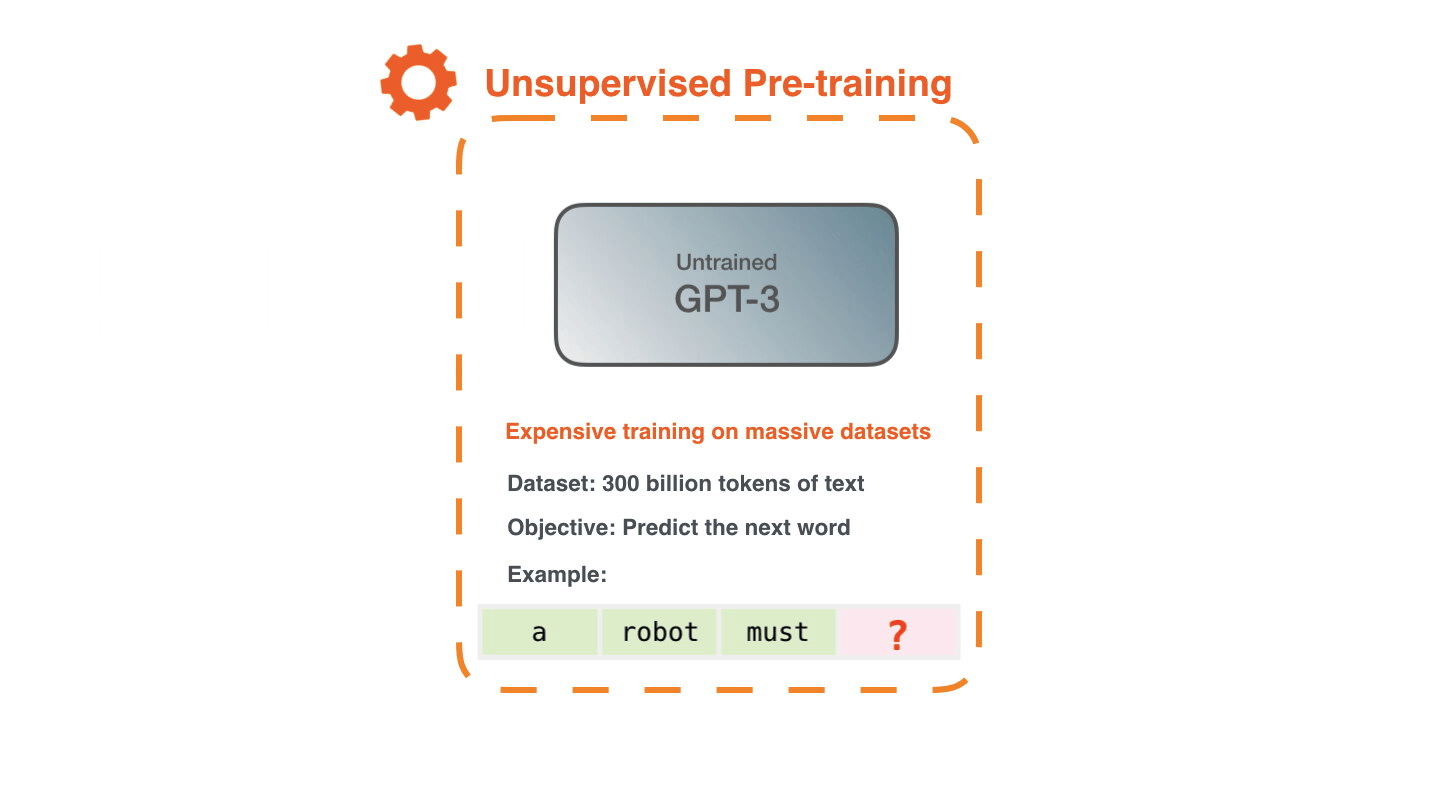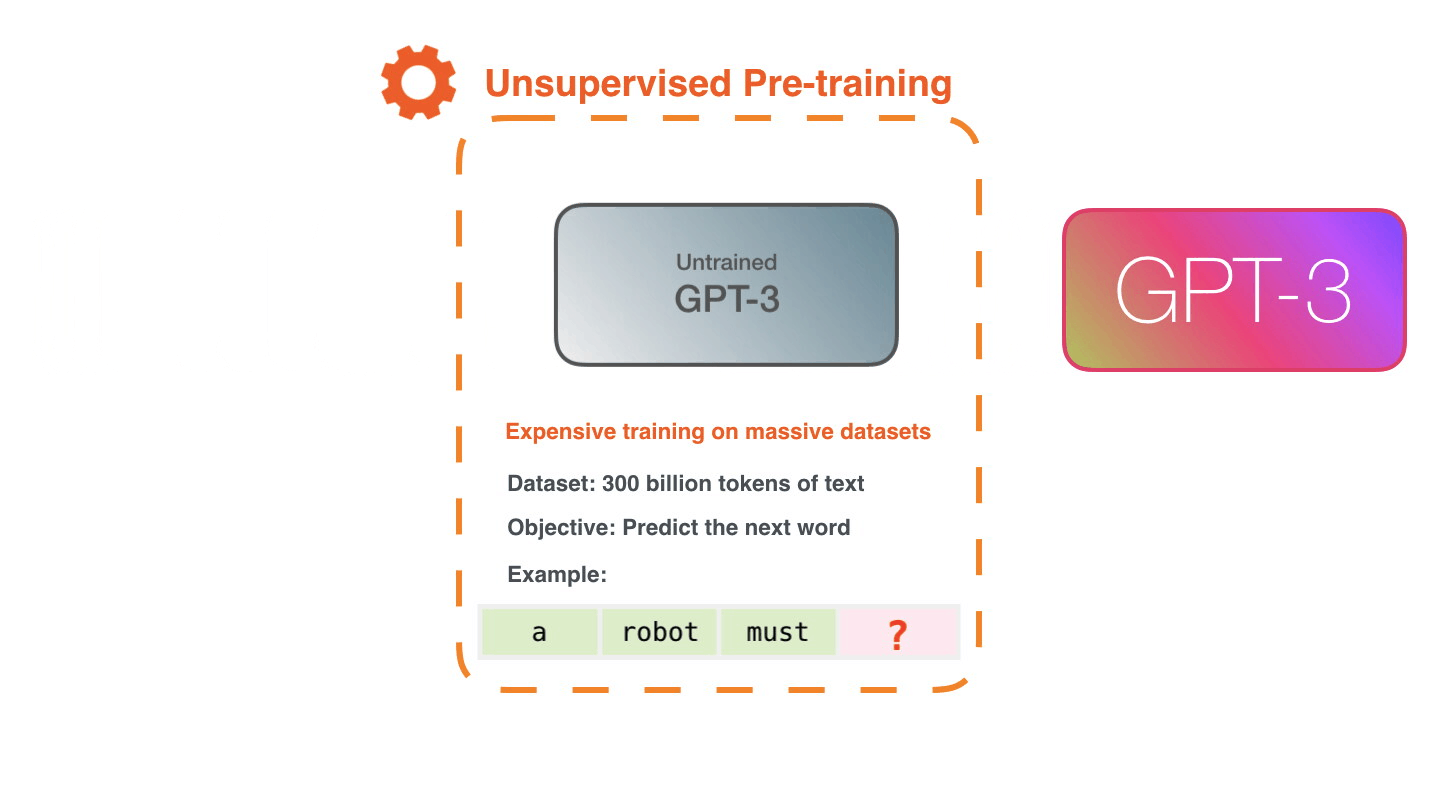
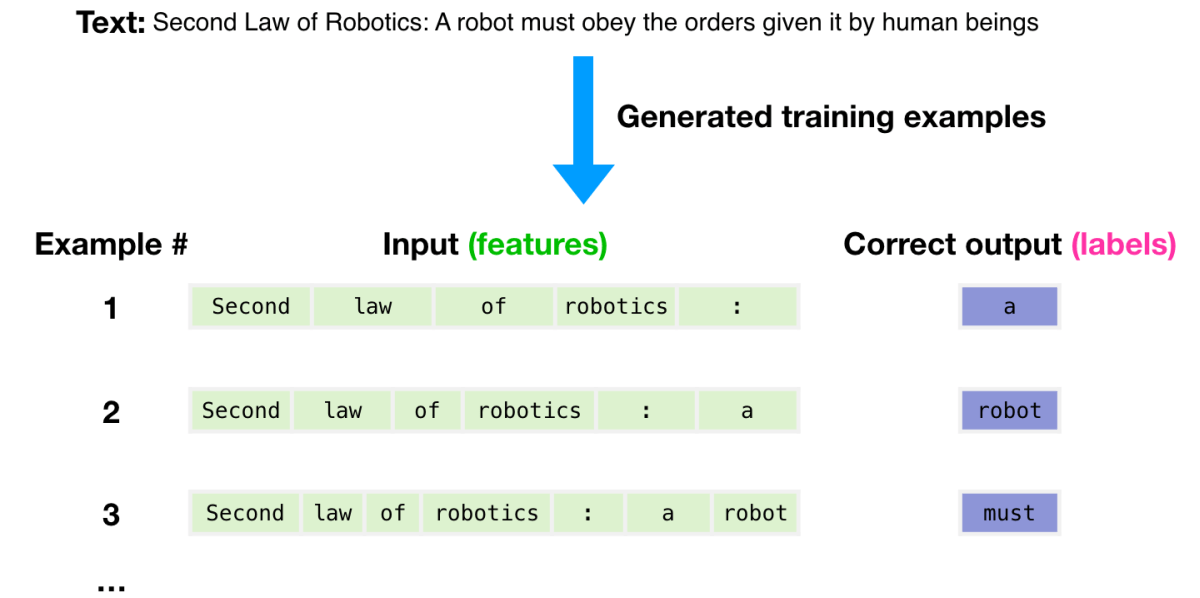
You can create a number of learning examples by changing the clipping method of the text example 'Second Law of Robotics: A robot must obey the orders given it by human beings' included in the dataset. We will generate a large amount of this learning example and let GPT-3 learn it.
Even with the high-precision and topic GPT-3, it is said that it will be mistaken during learning. Alammar explains that GPT-3 repeats the task of calculating the error between the wrong prediction and the correct answer and learning the error millions of times. 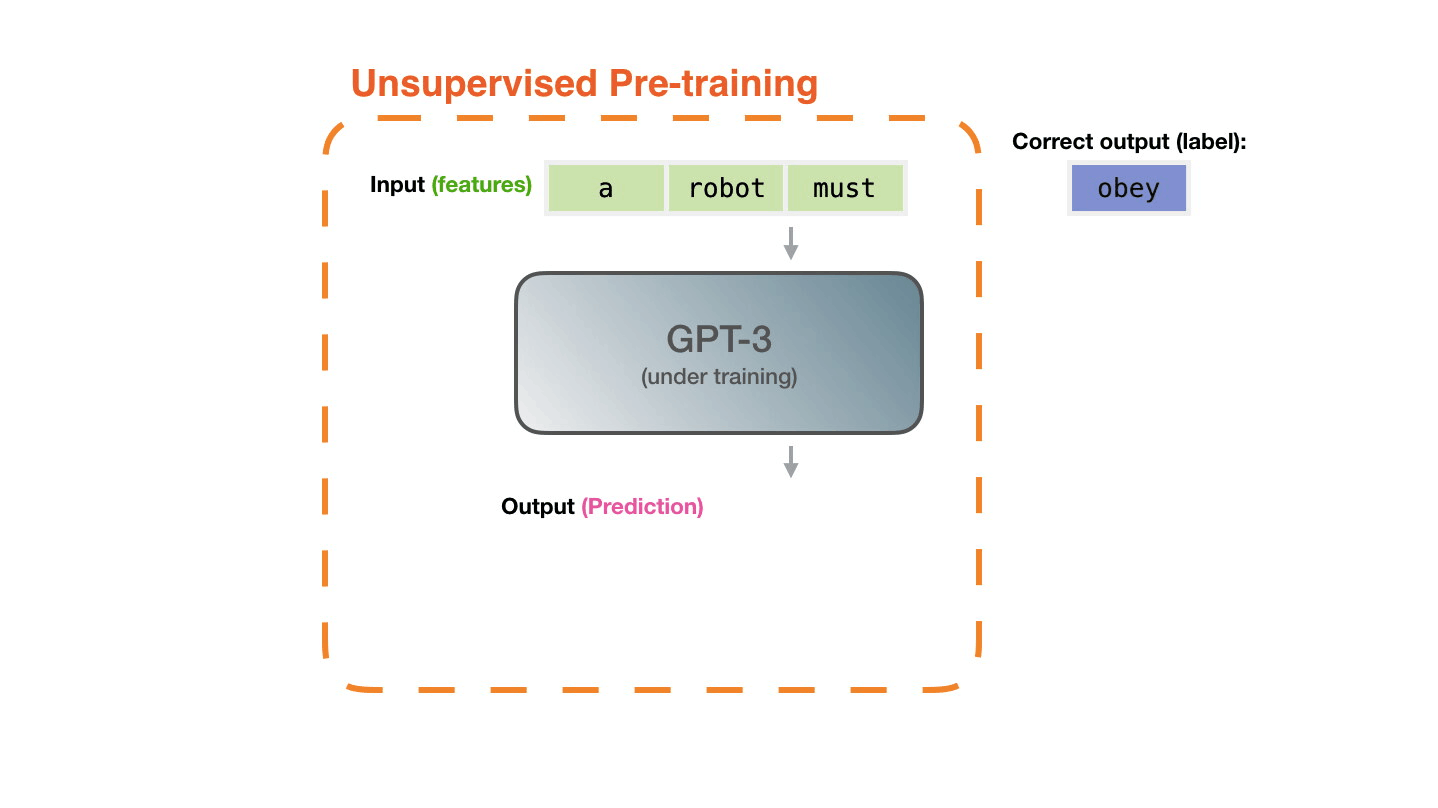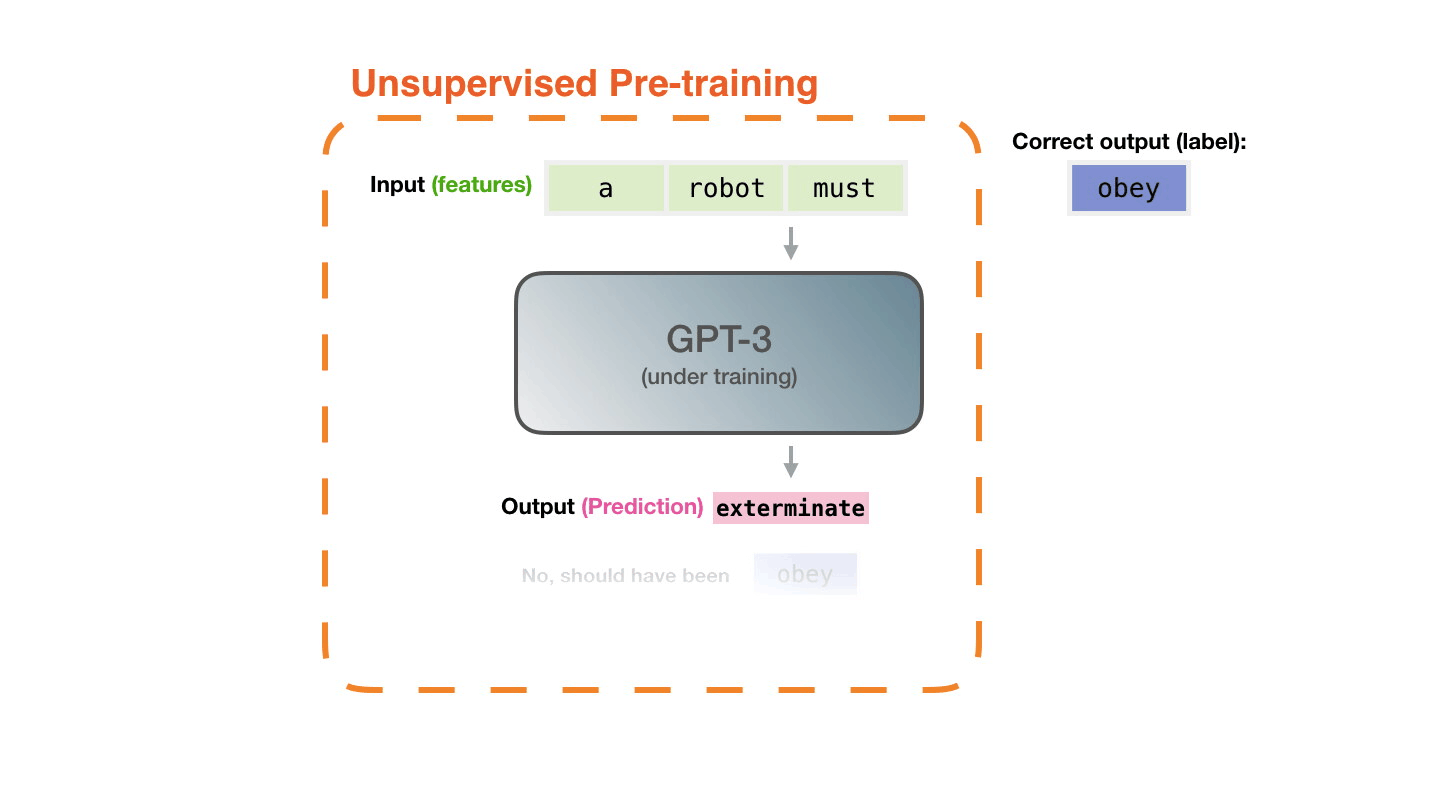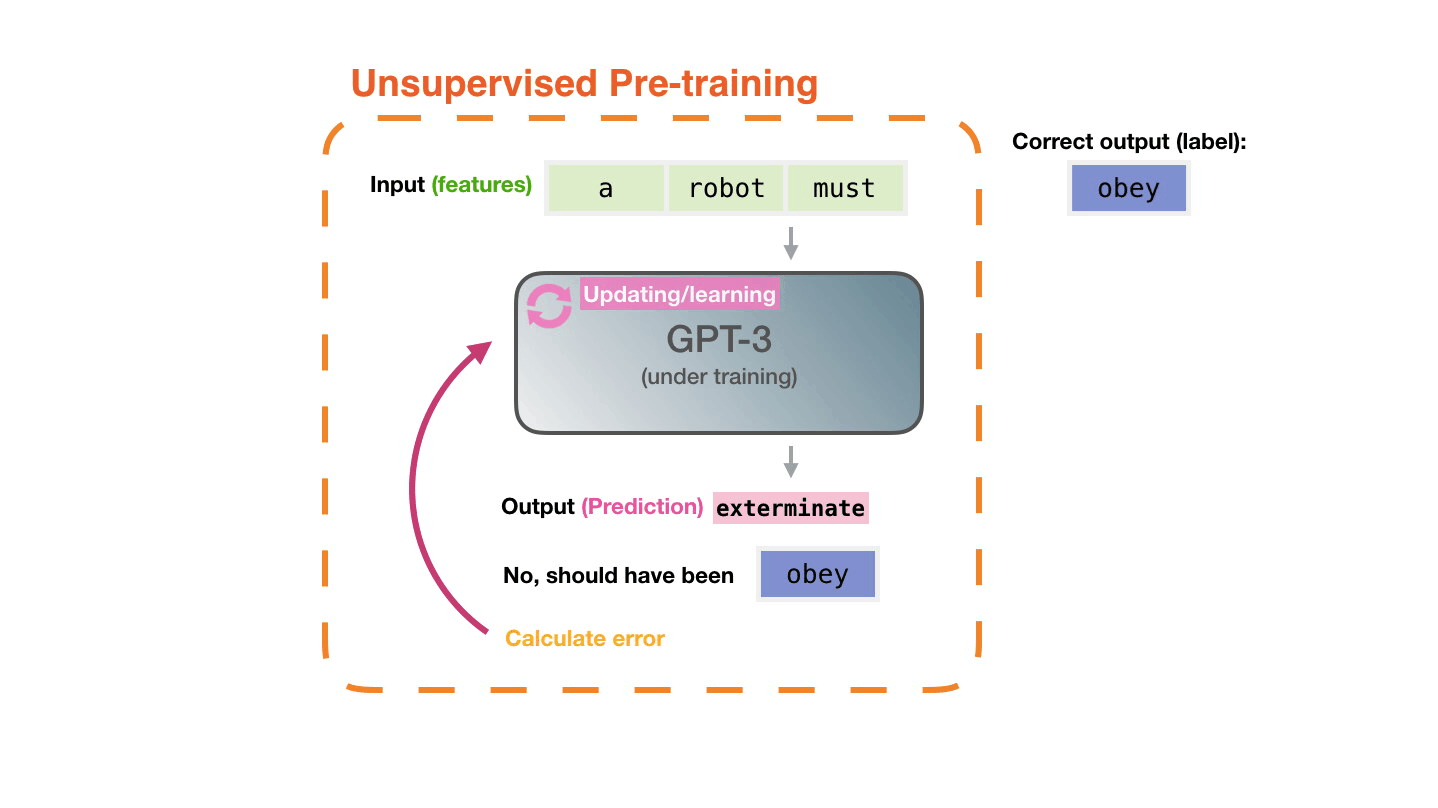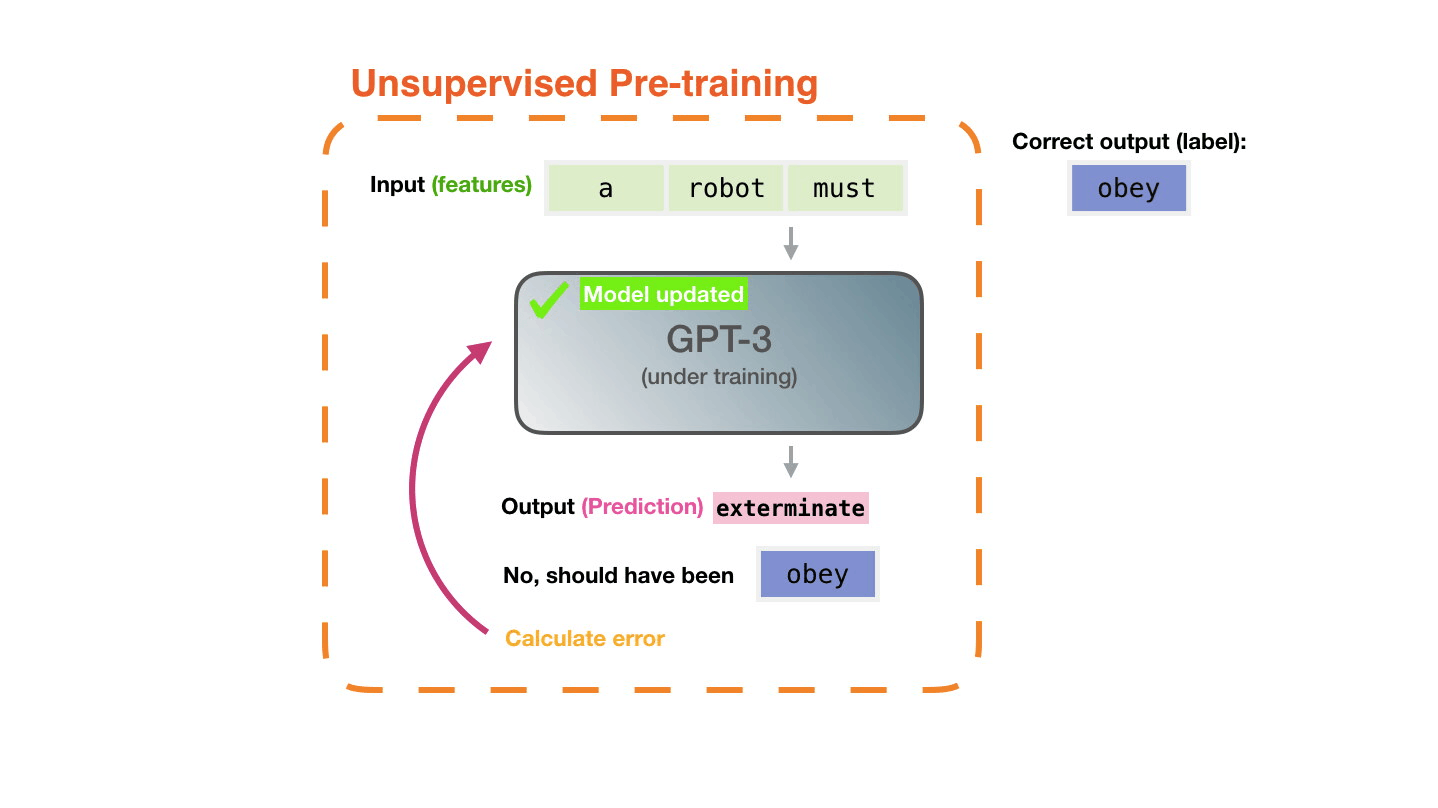
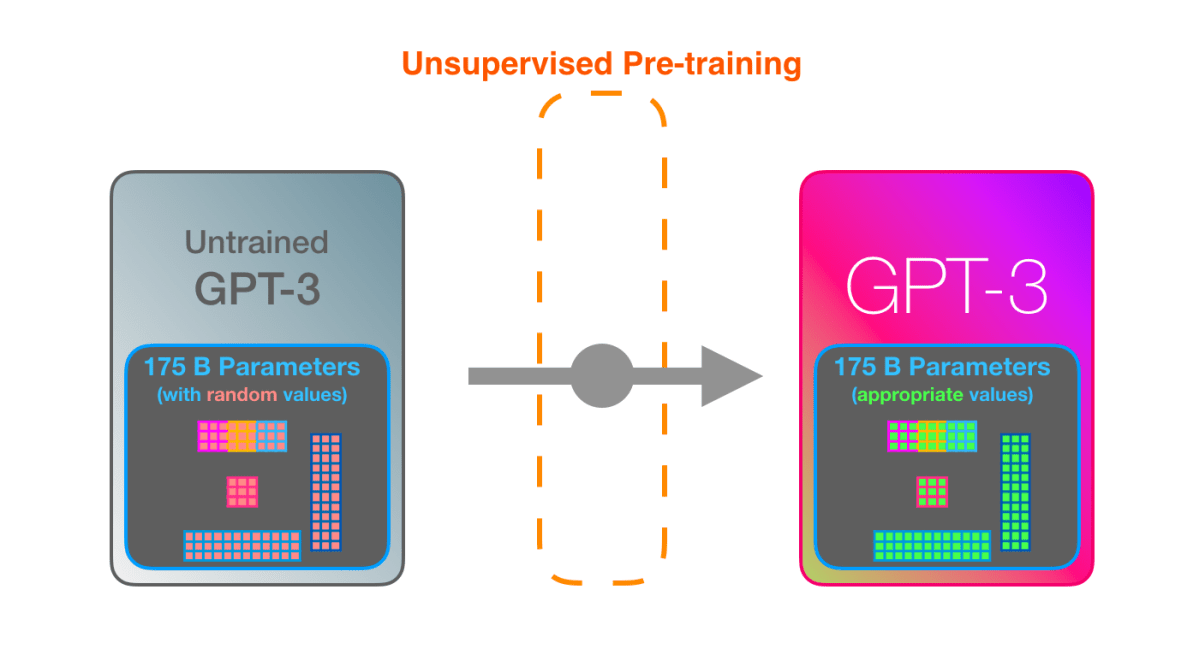
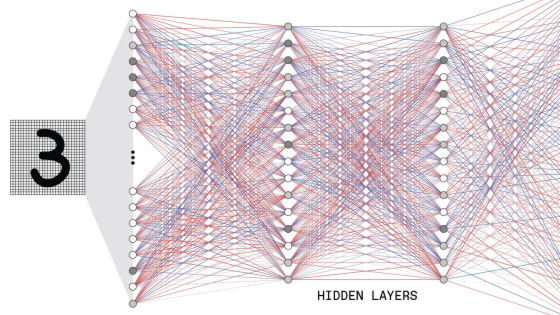
GPT-3 encodes what it learns into 175 billion parameters and makes predictions based on those parameters. The parameter is in a random state before learning, but it will be adjusted to a value that will lead to highly accurate prediction by learning.
GPT-3 does not input and output the character string at once, but does it for each token called token. The structure of GPT-3 is based on Google's language model '
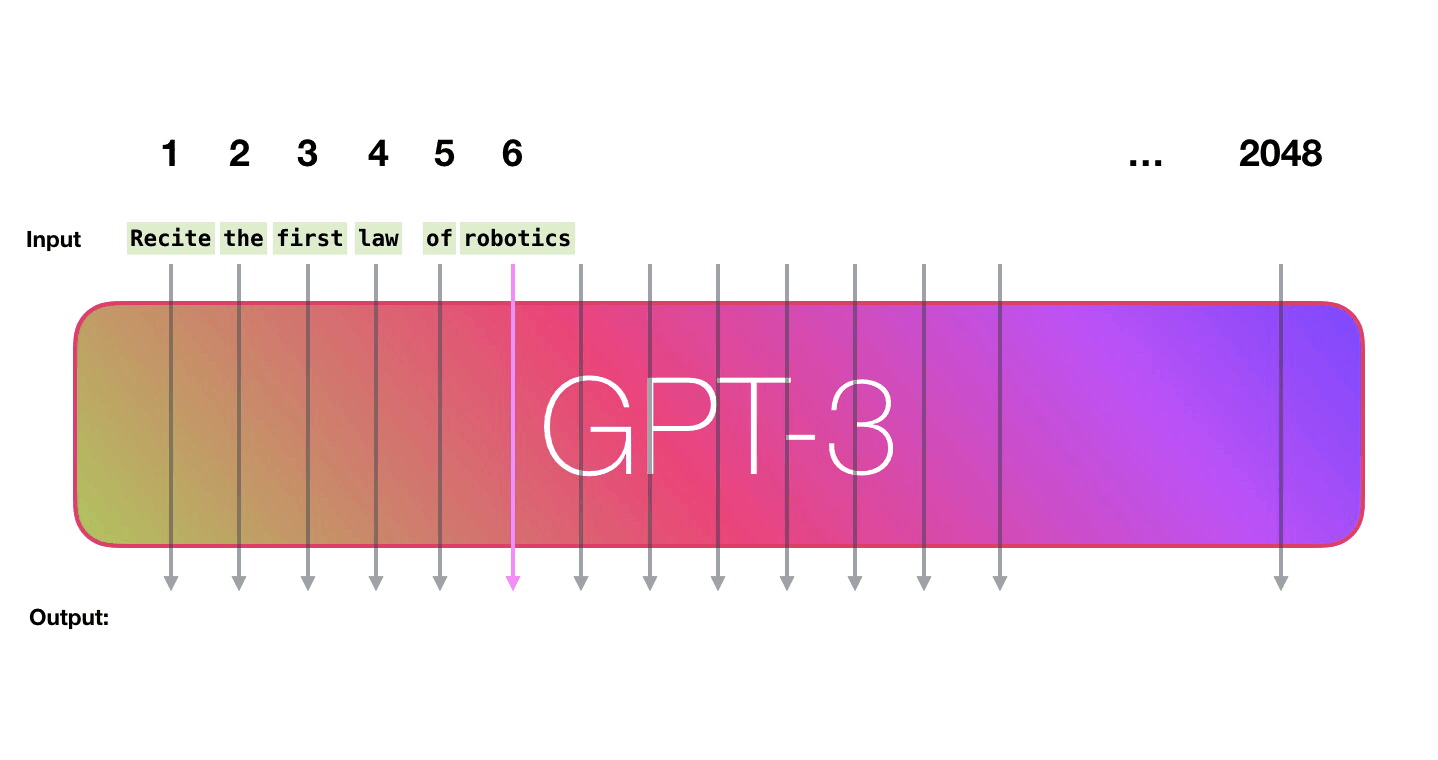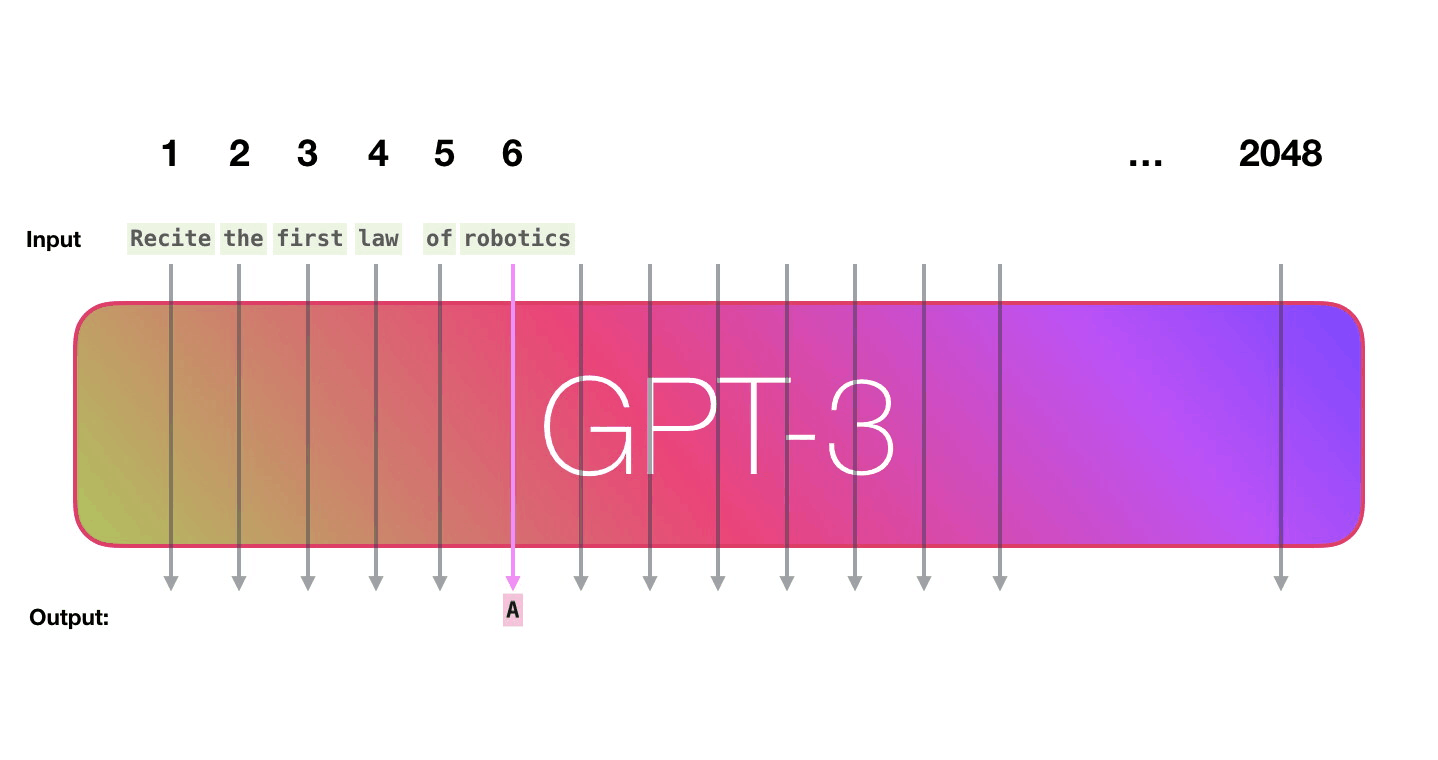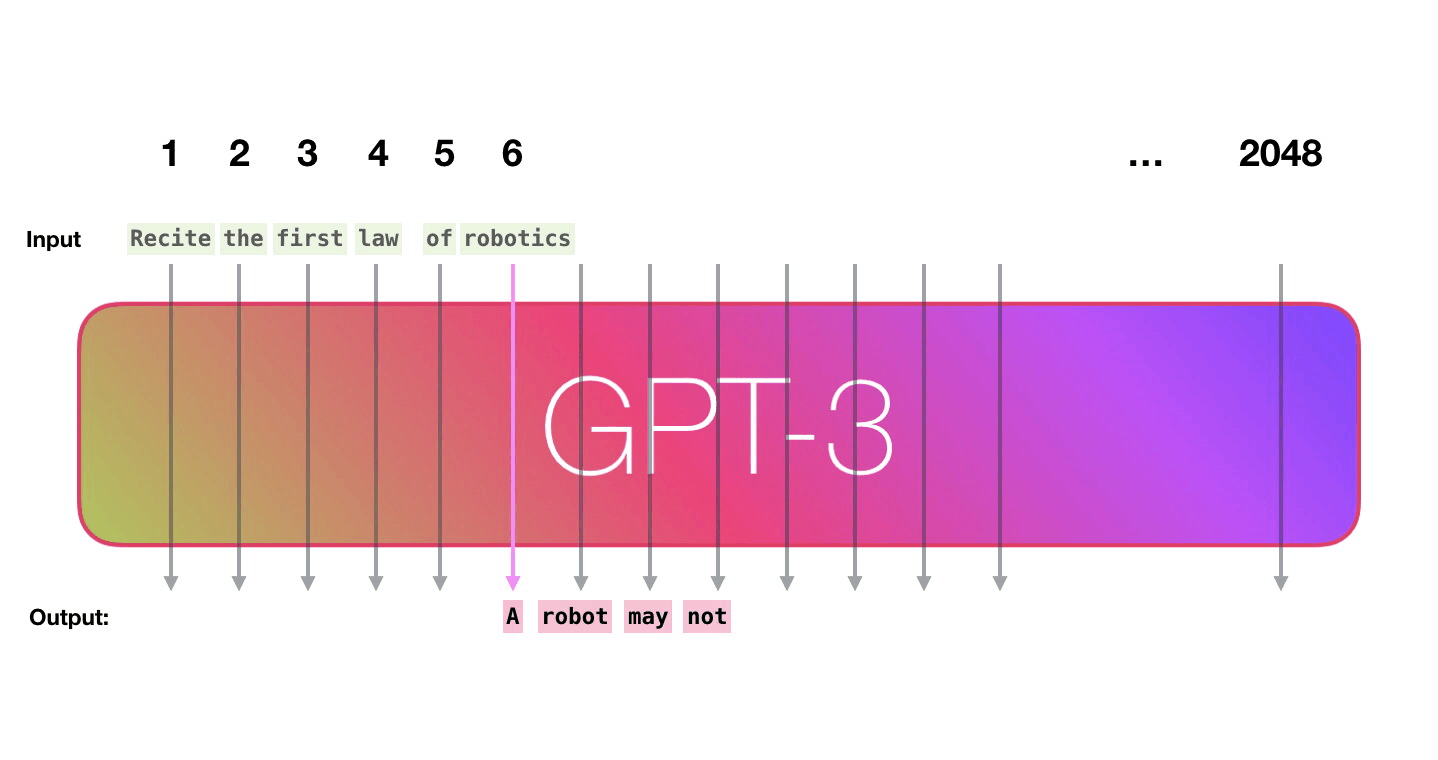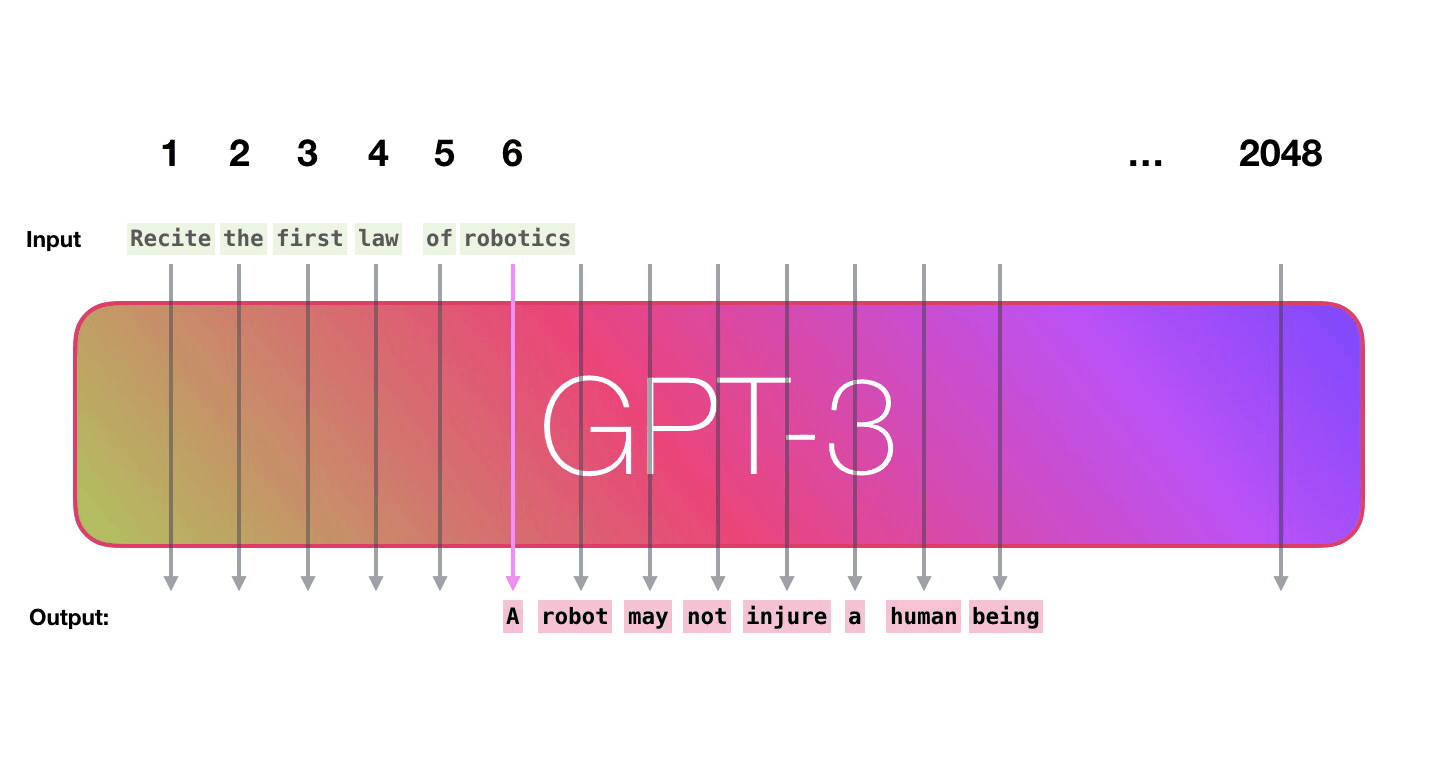
GPT-3 can handle 2048 tokens, showing evolution from GPT-2's 1028 tokens. Alammar pays attention to the path shown in purple from the word 'robotics' to the word 'A' in the sixth column.
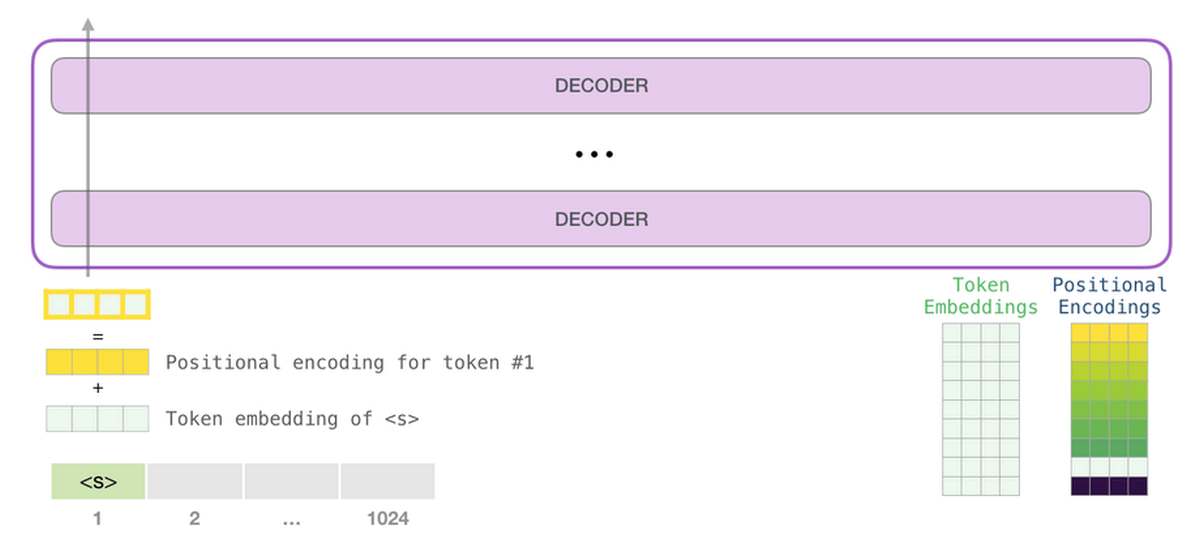
As the first step of predicting the next token, GPT-3 performs 'embedding' to convert text into a vector, and also inputs a vector that adds the position encoding corresponding to the position of the token to the prediction model. .. The prediction calculation based on the vector input in the second step is performed, and the vector output by the prediction model is converted into a word in the third step.
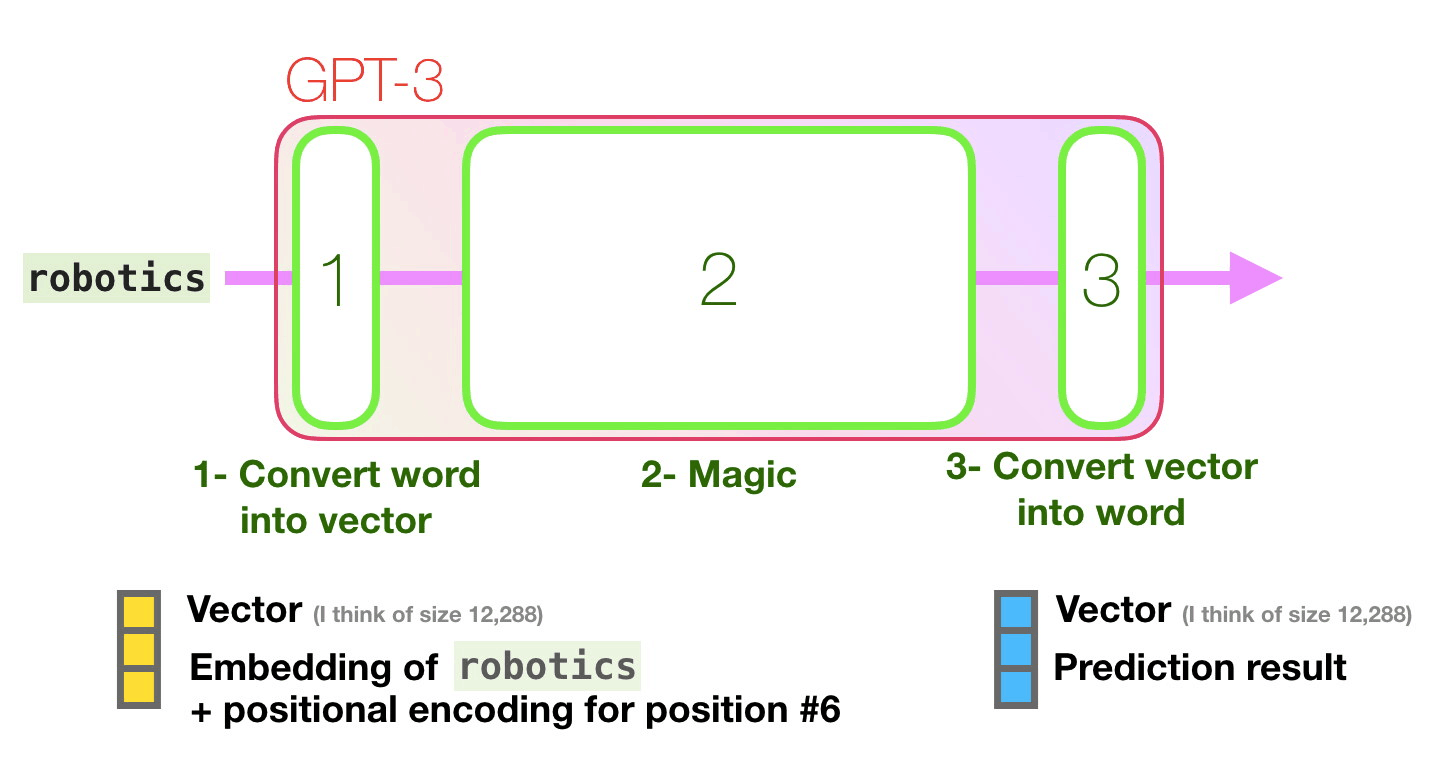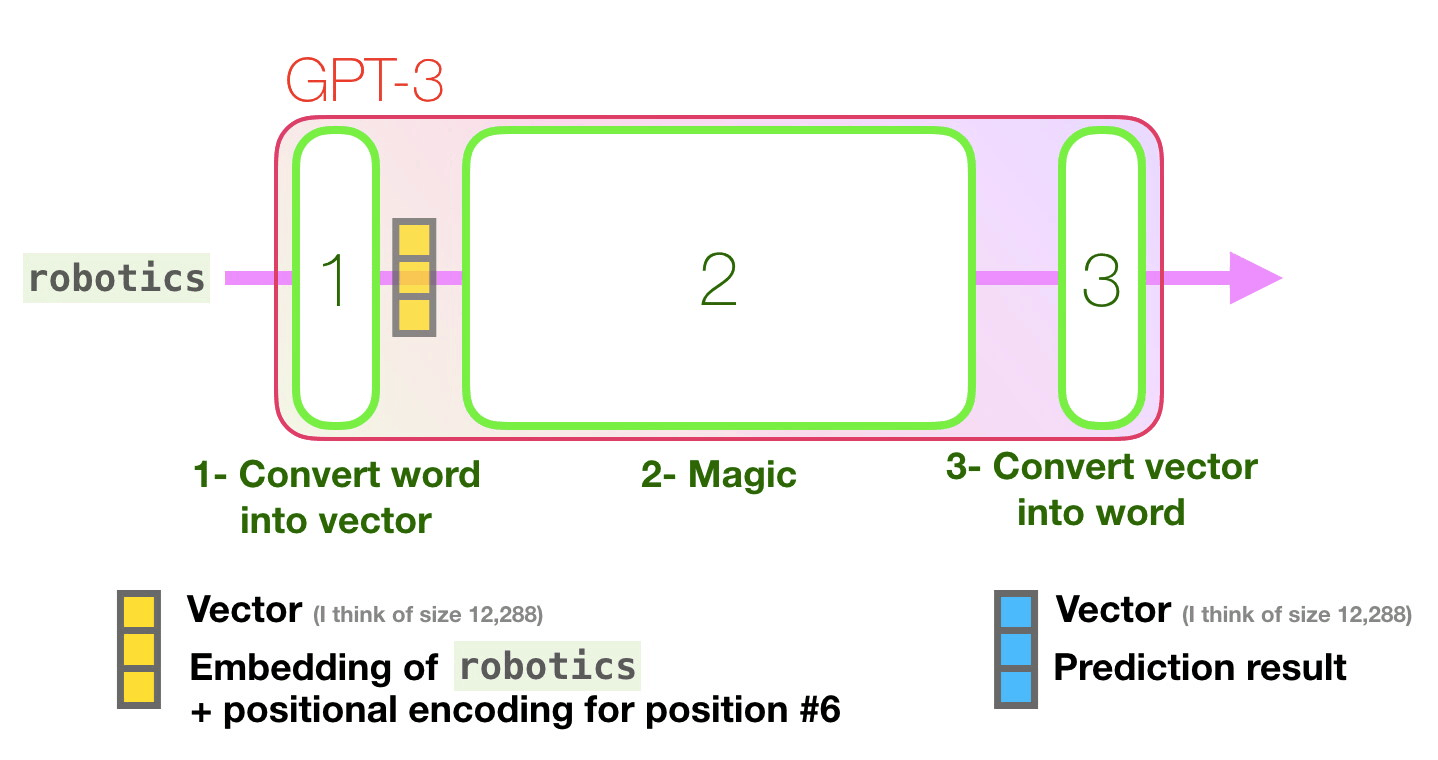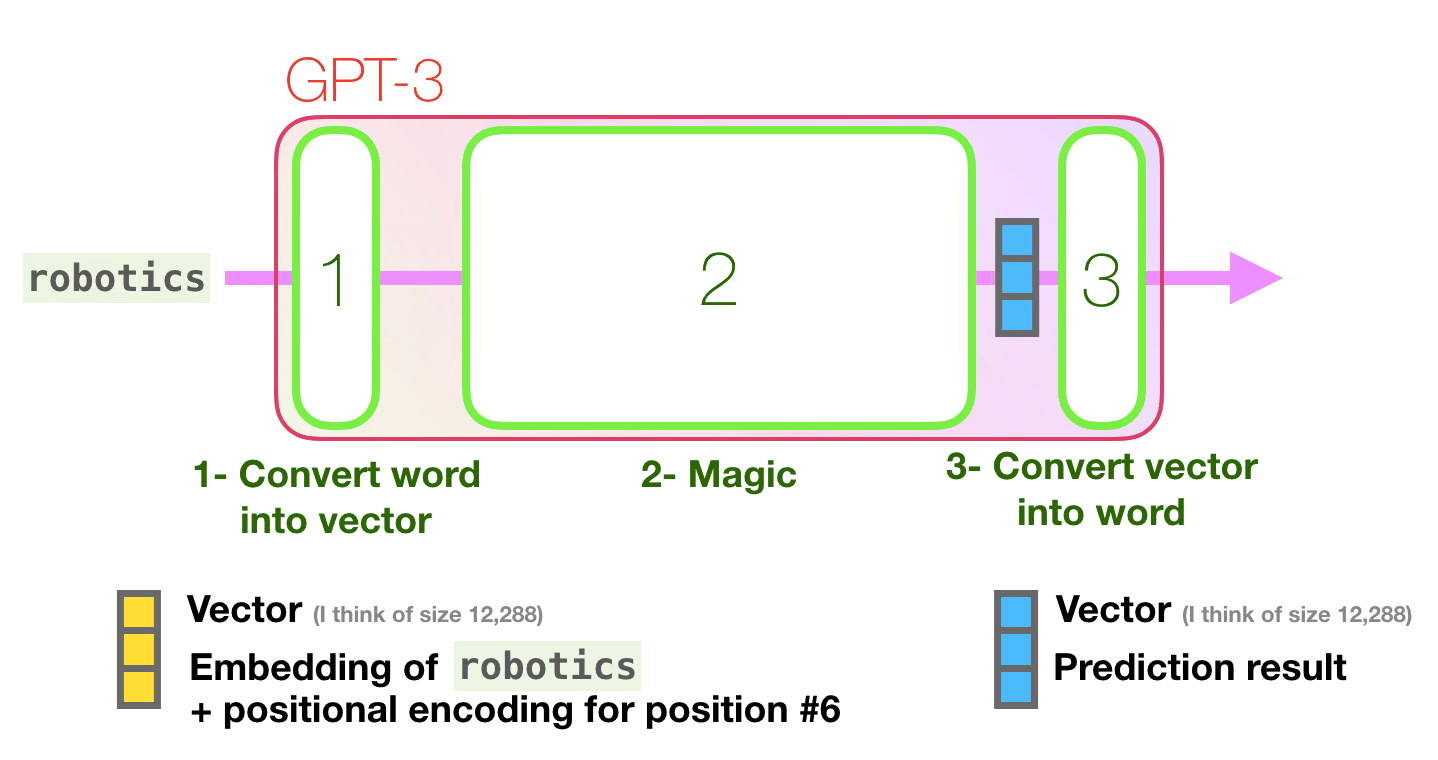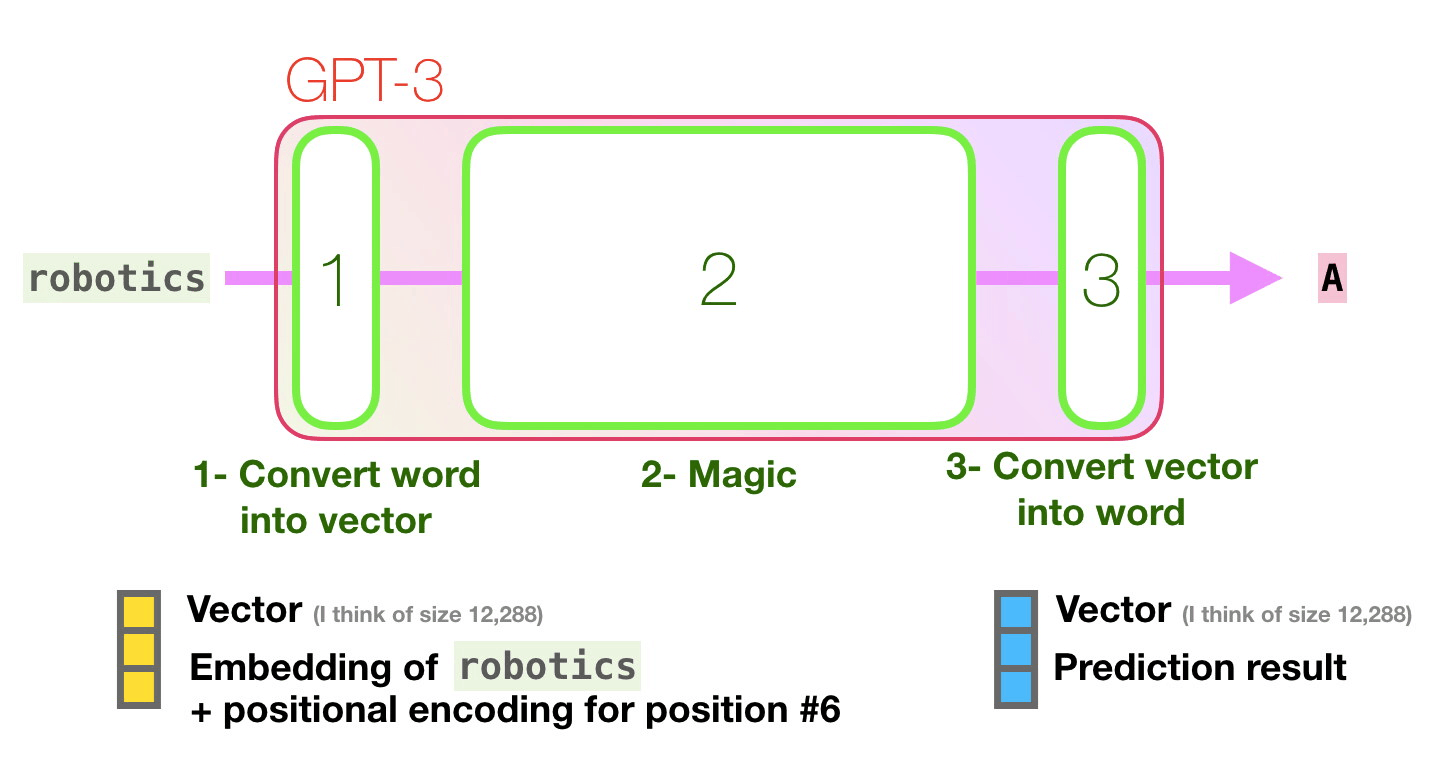
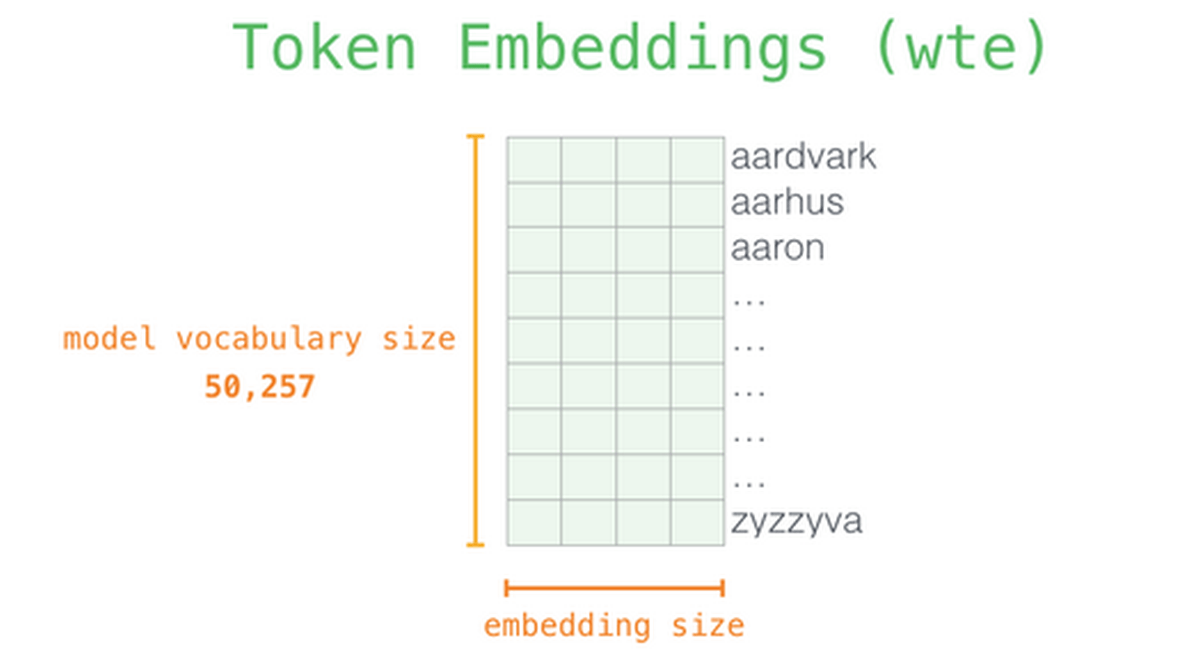
The GPT-3 predictive model is similar in structure to the GPT-2 model, but with a larger model. In the embedding performed in the first stage, the input text is decomposed into tokens and converted into a multidimensional vector. The 'embedded size', which is the dimension of the vector at the time of conversion, is the maximum model in GPT-2. While it was 1600, it was 12288 in GPT-3.
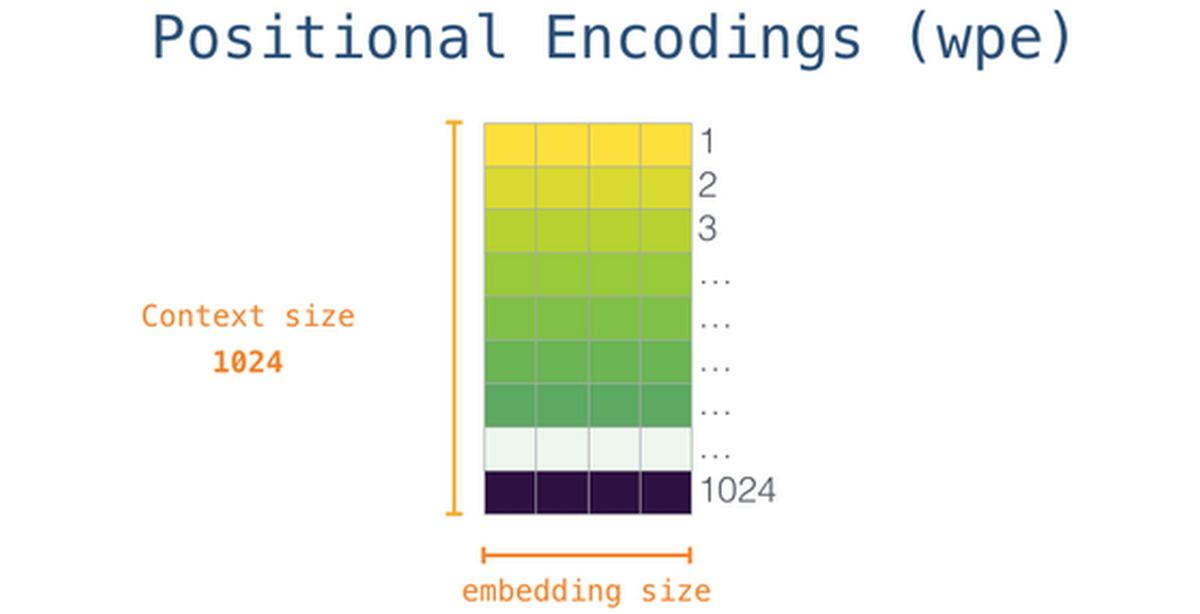
In a sentence such as 'I think, therefore I am,' it is appropriate that the numerical value that expresses 'I' that appears earlier and the value that appears after 'I' are different. The position encoding is performed by GPT-3 to reflect the position information of these words in the vector. Since the image below is of GPT-2, it is a 'context-size' that leads to the fineness of location information, that is, the number of tokens that can be processed at a time is 1028, but in GPT-3 it has been expanded to 2048, and location information is It is possible to reflect in more detail.
For each token that was converted to a vector by embedding, a vector is added to the predictive model with the position encoding corresponding to the token position added together. Up to here are the details of the first stage processing.
Alammar points out that language is strongly background driven. For example, in the English sentence 'A robot must obey the orders given it by human beings except where such orders would conflict with the First Law.' you must understand what the words 'it' and 'such orders' mean. , I can't understand the sentence. GPT-3 is doing 'Self-Attention' to capture the background of these languages. With Self-Attention, it is said that the relationship between tokens is expressed by calculating the score of how much each token is related to each other and expressing the score as a vector and adding.
The difference between GPT-2 and GPT-3 in self-attention is that dense Self-Attention and sparse Self-Attention exist alternately, Alammar said. The output of the token does not affect the next input until all the inputs are complete, but when the input is finished and the prediction stage is reached, the output affects the next input. ![]()
In GPT-3, Self-Attention is performed only on the area in front of the text (Masked Self-Attention), but
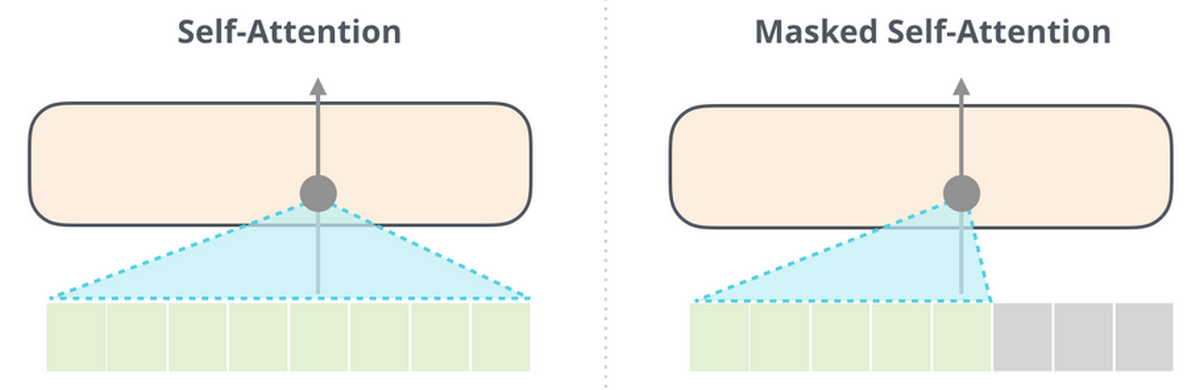
The GPT-3 has 96 layers of decoding layers that perform such a series of processing, and is strengthened to twice the 48 layers of the largest model of the GPT-2. It is the second stage until the vector corresponding to the prediction is output in the decoding layer, and the word prediction is completed by converting the vector into a word in the third stage. ![]()
Alammar says the potential of the GPT-3 will be even greater if fine-tuned to tune the model for better performance on specific tasks. 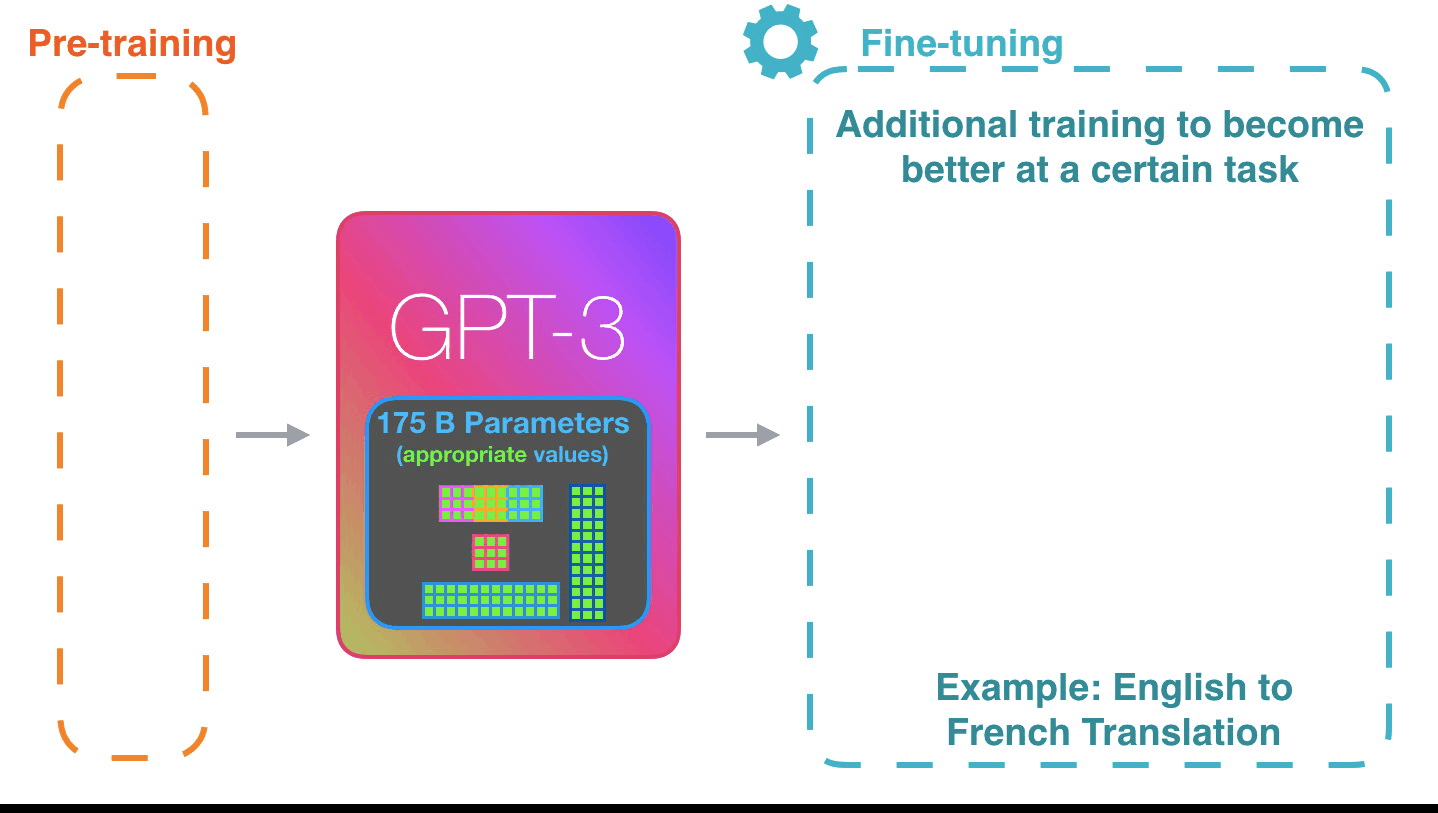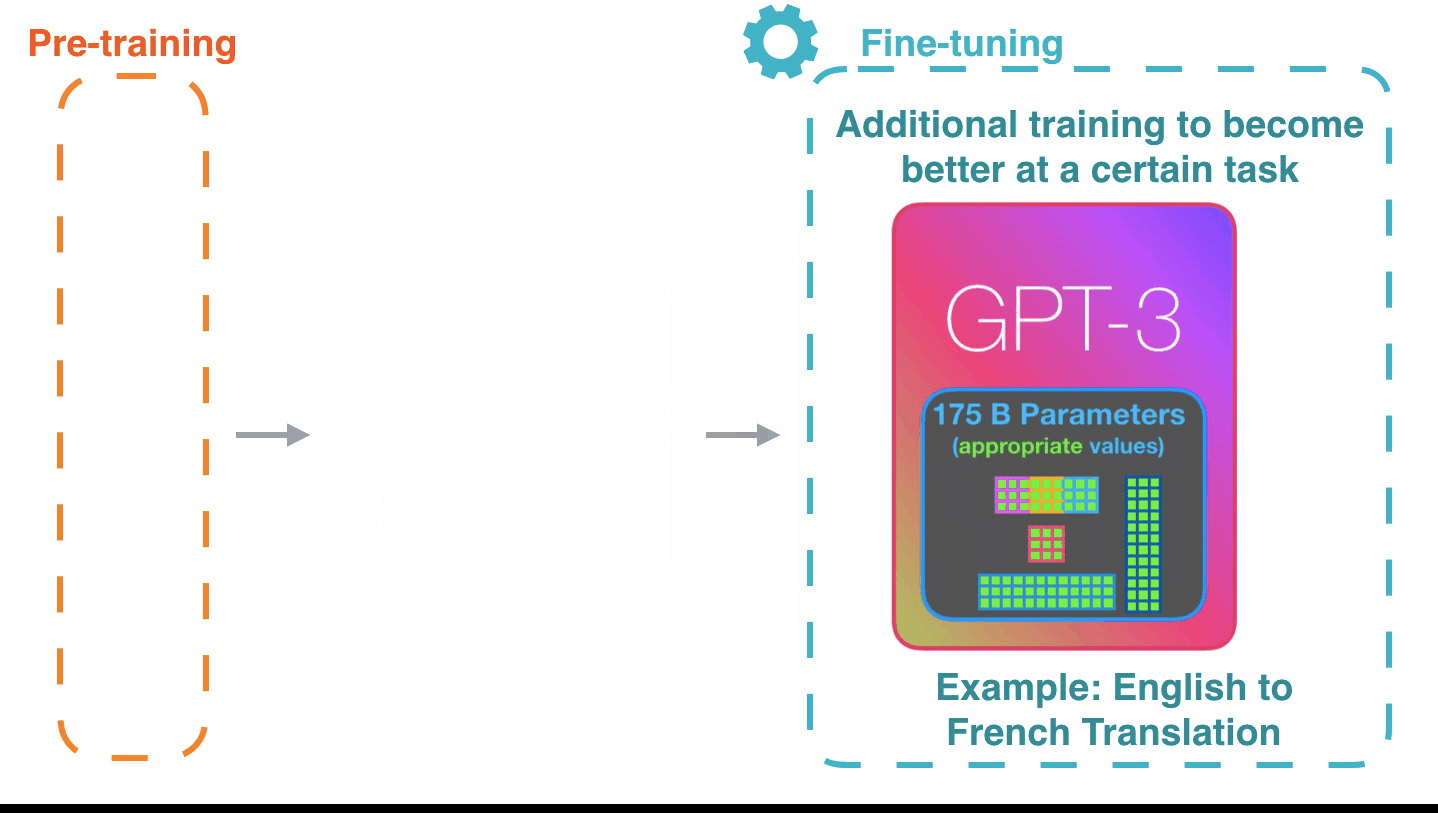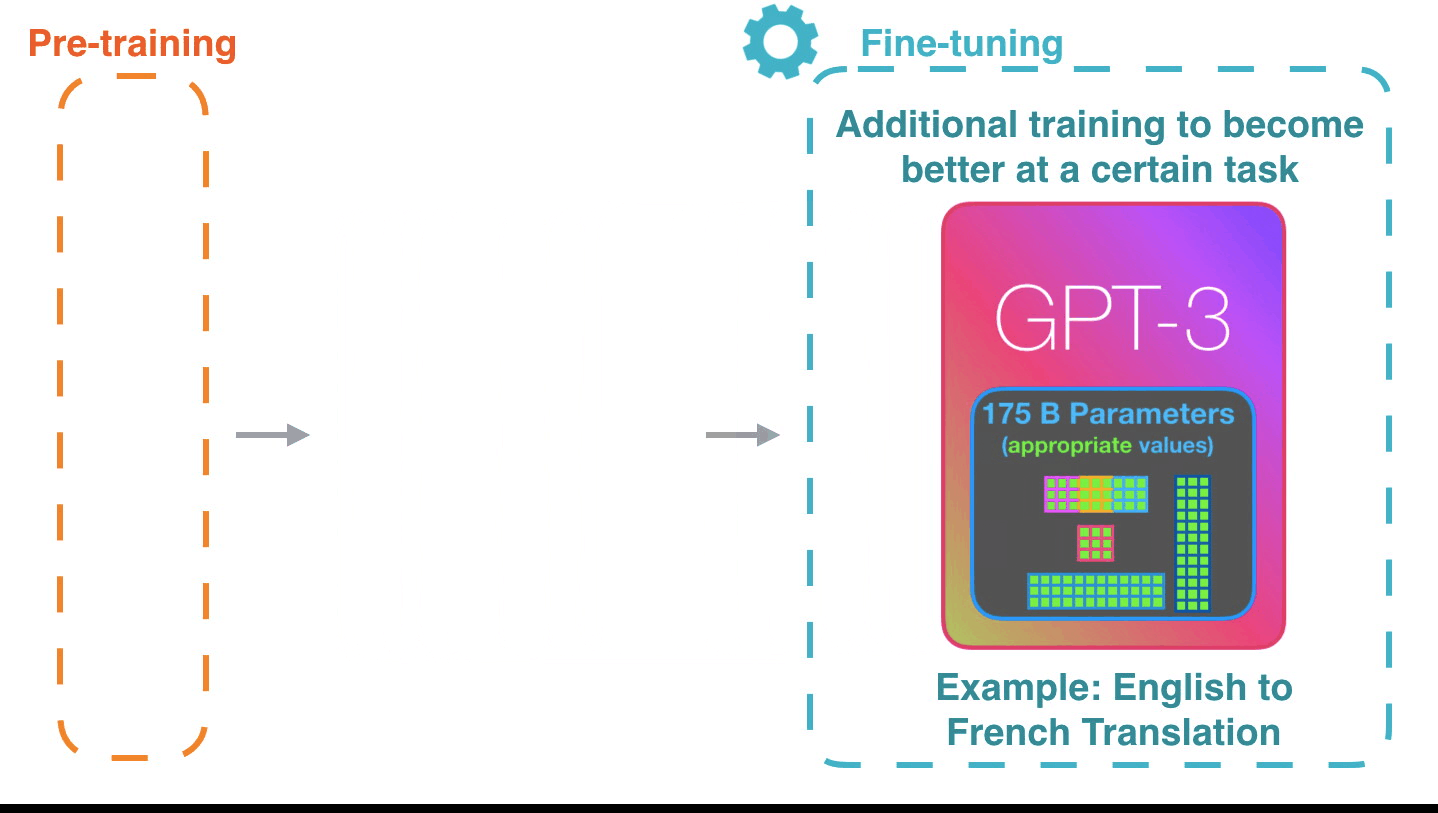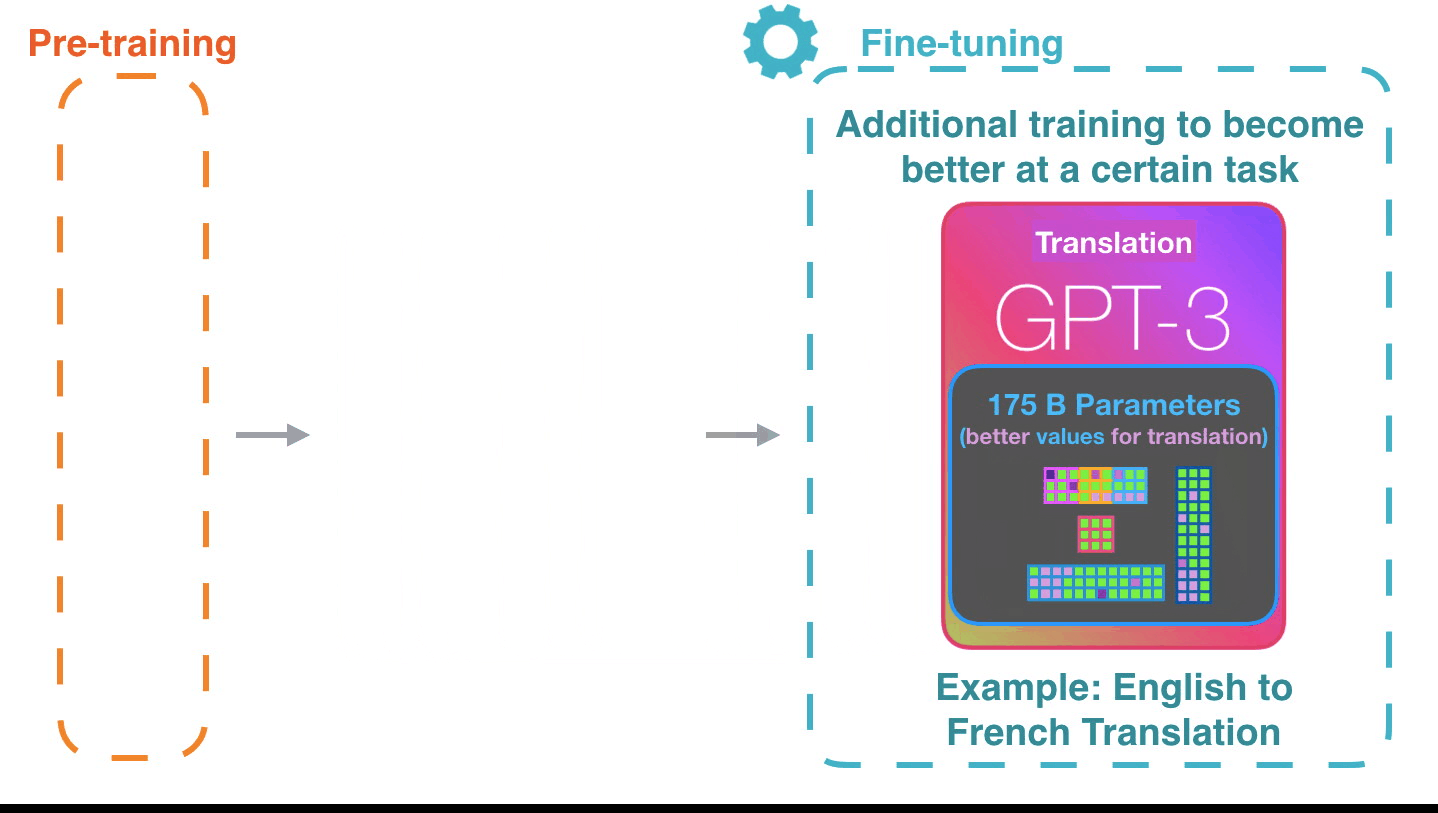
Related Posts:





in Software, Posted by darkhorse_log